Если в вашей компании принимают решения на основании анализа данных, значит вы уже сталкивались с трудностями, которые возникают при сборе и подготовке данных.
Обилие источников, низкое качество данных, ограничение времени и ресурсов, отсутствие стандартов и описанных процессов работы, человеческий фактор становятся причиной появления ошибок. Не важно, что вы используете для анализа: электронные таблицы, BI системы или программирование, ошибки в подготовке данных могут привести к неверным выводам и негативным последствиям для бизнеса и компании.
Подготовка данных и факторов для прогнозирования
Вопрос подготовки данных встает особенно остро при прогнозировании спроса. Прогнозирование — стартовая площадка процесса планирования продаж и операций, важный аналитический узел в организации цепи поставок. Цена ошибки высока, а значит выше потребность в правильной подготовке данных.
Запись вебинара «Подготовка данных для прогнозирования и корректировка» поможет организовать процесс подготовки данных для прогнозирования в компании.
Из видео, вы узнаете:
- Из каких этапов состоит процесс подготовки данных для прогнозирования
- Как найти и отобрать внутренние и внешние факторы прогнозирования
- Как правильно применять факторы к прогнозу
- Примеры факторов и порядок применения факторов к прогнозу
- Создание групп прогнозирования
- Очистка данных от аномалий и выбросов
- Статистические методы подготовки данных
- Примеры из практики бизнес-прогнозирования
Скачать материалы можно только после входа на сайт. Ниже появится ссылка.
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Источник: 4analytics.ru
Подготовка данных в Data Science-проекте: рецепты для молодых хозяек

В предыдущей статье я рассказывала про структуру Data Science-проекта по материалам методологии IBM: как он устроен, из каких этапов состоит, какие задачи решаются на каждой стадии. Теперь я бы хотела сделать обзор самой трудоемкой стадии, которая может занимать до 90% общего времени проекта: это этапы, связанные с подготовкой данных -сбор, анализ и очистка.
В оригинальном описании методологии Data Science-проект сравнивается с приготовлением блюда, а аналитик - с шеф поваром. Соответственно, этап подготовки данных сравнивается с подготовкой продуктов: после того, как на этапе анализа бизнес-задачи мы определились с рецептом блюда, которое будем готовить, необходимо найти, собрать в одном месте, очистить и нарезать ингредиенты. Соответственно, от того, насколько качественно был выполнен этот этап, будет зависеть вкус блюда (предположим, что с рецептом мы угадали, тем более рецептов в открытом доступе полно). Работа с ингредиентами, то есть подготовка данных - это всегда ювелирное, трудоемкое и ответственное дело: один испорченный или недомытый продукт - и весь труд впустую.
Сбор данных
После того, как мы получили список ингредиентов, которые нам могут понадобится, мы приступаем к поиску данных для решения задачи и формируем выборку, с которой в дальнейшем будем работать. Напомним, для чего нам нужна выборка: во-первых, по ней мы составляем представление о характере данных на этапе подготовки данных, а во-вторых из нее мы будем формировать тестовую и обучающую выборки на этапах разработки и настройки модели.

Постановка задачи

Первым шагом процесса интеллектуального анализа данных, как видно из диаграммы ниже, является четкое определение бизнес-задачи. Этот шаг включает анализ бизнес-требований, определение масштаба проблемы, метрик, по которым будет выполняться оценка модели, а также определение конечной цели проекта интеллектуального анализа данных. Эти задачи можно сформулировать в виде следующих вопросов:
- Что необходимо найти?
- Какой атрибут набора данных необходимо предсказать?
- Какие типы связей необходимо найти?
- Надо ли делать прогнозы на основании модели интеллектуального анализа данных или просто найти интересующие шаблоны и связи?
- Каким образом распределяются данные?
- Как связаны столбцы, а в случае с несколькими таблицами — как связаны таблицы?
Чтобы ответить на эти вопросы, возможно, потребуется исследовать уровень доступности данных, изучить потребности пользователей в отношении доступных данных. Если данные не поддерживают потребности пользователей, то может возникнуть необходимость в изменении определения проекта.
Подготовка данных
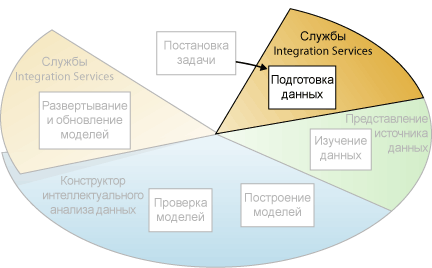
Вторым шагом процесса интеллектуального анализа данных, как видно из следующей диаграммы, является объединение и очистка данных, определенных во время шага Постановка задачи. Службы Microsoft SQL Server 2005 Integration Services (SSIS) содержат все средства, необходимые для завершения данного шага, включая преобразования для очистки и объединения данных.
Данные могут находиться в разных частях компании и храниться в различных форматах или содержать такие ошибки согласования, как дефектные или отсутствующие записи. Например, согласно данным может оказаться, что клиент купил продукт еще до своего рождения или регулярно делает покупки в магазине, расположенном за 2000 километров от дома.
Прежде чем перейти к разработке моделей, необходимо устранить эти несоответствия. Обычно пользователь работает с очень большим набором данных и не может просмотреть каждую транзакцию. Следовательно, для просмотра данных и выявления несогласованности в них необходимо использовать какой-либо вид автоматизации, например тот, который имеется в службах Integration Services.
Просмотр данных
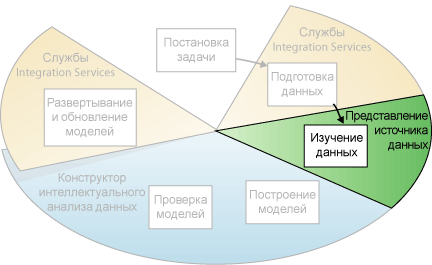
Третьим шагом процесса интеллектуального анализа данных, как видно из диаграммы ниже, является просмотр подготовленных данных. Для принятия правильных решений при создании моделей необходимо понимать данные.
Методы исследования данных включают в себя расчет минимальных и максимальных значений, расчет средних и стандартных отклонений и изучение распределения данных. После исследования данных можно определить, содержит ли набор данных дефектные данные или нет, а затем разработать стратегию по устранению несоответствий. Конструктор представлений источников данных в среде BI Development Studio содержит несколько средств, которые можно использовать для просмотра данных.
Построение моделей
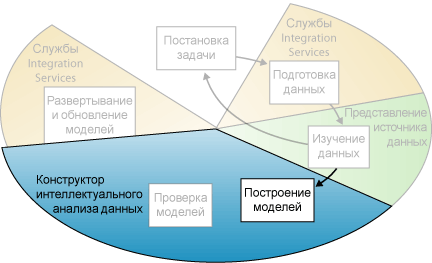
Четвертым шагом процесса интеллектуального анализа данных, как видно из диаграммы ниже, является построение моделей интеллектуального анализа данных. Прежде чем построить модель, необходимо случайным образом разделить подготовленные данные в отдельные наборы обучающих и контрольных данных.
Набор обучающих данных используется для построения модели, а контрольный набор данных — для проверки точности модели путем создания прогнозирующих запросов. Чтобы разделить набор данных, можно использовать Преобразование «Процентная выборка» в службах Integration Services.
Знания, полученные при выполнении шага Просмотр данных, помогут определить и создать модель интеллектуального анализа данных. Обычно модель содержит входные столбцы, идентифицирующий столбец и прогнозируемый столбец.
Данные столбцы можно затем определить в новой модели при помощи языка расширений интеллектуального анализа данных или мастера интеллектуального анализа данных в среде BI Development Studio. Дополнительные сведения об использовании языка расширений интеллектуального анализа данных см. в разделе Справочник по расширениям интеллектуального анализа данных.
Дополнительные сведения об использовании мастера интеллектуального анализа данных см. в разделе Мастер интеллектуального анализа данных. После определения структуры модели интеллектуального анализа данных выполняется ее обработка и наполнение пустой структуры шаблонами, описывающими модель. Данный процесс известен как обучение модели.
Шаблоны выявляются путем применения в отношении исходных данных математического алгоритма. SQL Server 2005 содержит отдельный алгоритм для каждого типа модели, доступной для построения. Для настройки каждого алгоритма можно использовать параметры. Модель интеллектуального анализа данных определяется объектом структуры интеллектуального анализа данных, объектом модели интеллектуального анализа данных и алгоритмом интеллектуального анализа данных.
Источник: studfile.net