В основе любой логики лежат данные, над которыми выполняются логические действия, поэтому я могу точно сказать, что презентационная логика есть везде (в том числе в приложениях).
Презентационная логика — логика согласно которой создается некое конечное представление данных.
Представление данных — формат данных полученный в следствии работы презентационной логики.
Преобразование
Рассмотрим процесс преобразования презентационной логики.
Server app (json data) —> Web-browser (GUI) —> Человек.
Если абстрагироваться от названий (Server app, Web-browser, Человек) и назвать каждое взаимодействующее звено приложением, то получается что каждое приложение отправляет представление данных понятное клиенту приложения.
Таким образом, у нас всегда есть приложение и пользователь приложения (которое мы рассматриваем, как взаимодействующее приложение).
Обмен представлениями
А теперь задумайтесь, приложения ведь взаимодействуют, это значит что представление данных может быть как в одну сторону (от приложения 1 к приложению 2), так и в обратную сторону (от приложения 2 к приложению 1) и вовсе не обязательно что данные представления будут одинаковы, например:
Архитектура ПО, MVC и бизнес-логика. Критика Django
Приложение отправляет SQL-запрос в Базу данных, а База данных возвращает результирующий набор данных
Можно заметить, что взаимодействие Человека с другим Человеком тоже является представлением данных, например:
Человек 1 написал письмо Человеку 2, но Человек 2 позвонил Человеку 1 и ответил голосом
Кстати, слово является результатом полученным в следствии преобразований над буквами, думаю Вы уловили суть.
Презентационная логика VS Бизнес логика
Бизнес логика — логика преобразования данных согласно указанию бизнеса (не общепринятого стандарта), бывает:
- презентационной (как преобразовать данные, чтобы отобразить)
- непрезентационной (как преобразовать данные, без цели отображения)
Презентационная логика бывает двух видов:
- стандартизированная (преобразование одной структуры в другую, например csv в xls с указанием версий)
- нестандартизированная (преобразование одной структуры в другую, согласно бизнес требованиям)
В итоге, три вида логики продиктованы бизнесом и лишь одна стандартом.
Если обобщить, то есть всего два вида логики:
- стандартизированная презентационная логика
- бизнес-логика
Источник: yapro.ru
Модели клиент—сервер в технологии распределенных баз данных
При размещении СУБД на персональном компьютере, который не находится в сети, БД всегда используется в монопольном режиме. Даже если с ней работают несколько пользователей, они могут работать только последовательно.
Однако, как показала практика применения локальных баз данных, в большинстве случаев информация, которая в них содержится, носит многопользовательский характер, поэтому возникает необходимость разработки таких СУБД, которые обеспечили бы возможность одновременной работы пользователей с базами данных. Тем более, что все современные предприятия строят свою политику в области информационного обеспечения на основе принципов САLS-технологий.
#8 Бизнес логика или детали реализации? — Vue.js: концепции
Системы управления базами данных, обеспечивающие возможность одновременного доступа к информации различным пользователям называют системами управления распределенными базами данных. В общем случае режимы использования БД имеют вид, представленный на рис. 1.
Рассмотрим основные понятия, применяемые в системах управления распределенными базами данных.

Рис.1. Режимы работы с базами данных
Пользователь БД — программа или человек, обращающийся к базе данных.
Запрос — процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД.
Транзакция — последовательность операций модификации данных в БД, переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Логическая структура БД — определение БД на физически независимом уровне; ближе всего соответствует концептуальной модели БД.
Топология БД, или структура распределенной БД, — схема распределения физической организации базы данных в сети.
Локальная автономность означает, что информация локальной БД и связанные с ней определения данных принадлежат локальному владельцу и им управляются.
Удаленный запрос — запрос, который выполняется с использованием модемной связи.
Возможность реализации удаленной транзакции — обработка одной транзакции, состоящей из множества SQL-запросов, на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL, которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле.
Распределенный запрос — запрос, при обработке которого используются данные из БД, расположенные в разных узлах сети.
Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа. При этом пользовательские терминалы не имели собственных ресурсов, т. е. процессоров и памяти, которые могли бы использоваться для хранения и обработки данных. Первой полностью реляционной системой, работающей в многопользовательском режиме, была СУБД SYSTEM R фирмы IВМ. Именно в ней были реализованы как язык манипулирования данными SQL, так и основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД.
Модели клиент—сервер в технологии распределенных баз данных
Вычислительная модель клиент—сервер связана с появлением в 1990-х гг. открытых систем. Термин «клиент—сервер» применялся к архитектуре программного обеспечения, которое состояло из двух процессов обработки информации: клиентской и серверной. Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов. Учитывая что аппаратная реализация этой модели управления базами данных связана с созданием локальных вычислительных сетей предприятия, такую организацию процесса обработки информации называют архитектурой клиент — сервер.
Основной принцип технологии клиент— сервер применительно к технологии управления базами данных заключается в разделении функций стандартного интерактивного приложения на пять групп, имеющих различную природу:
— функции ввода и отображения данных (Presentation Logic);
— прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic);
— функции обработки данных внутри приложения (Database Logic);
— функции управления информационными ресурсами (Database Manager System);
— служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных в архитектуре клиент— сервер, приведена рис. 2.
Презентационная логика как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения. К этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация. Поэтому основными задачами презентационной логики являются:
• формирование экранных изображений;
• чтение и запись в информации экранные формы;
• обработка движений мыши и нажатие клавиш клавиатуры.

Рис. 2. Структура типового приложения, работающего с базой данных
Бизнес-логика, или логика собственно приложений — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как С, С++, Visual Basic и др.
Таблица 1

Логика обработки данных — это часть кода приложения, которая непосредственно связана с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используется язык SQL.
Процессор управления данными — это собственно СУБД. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения их надо выделить в отдельную часть приложения.
В централизованной архитектуре эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений (табл. 1):
• распределенная презентация (DR – Distribution Presentation);
• удаленная презентация (RP — Remote Presentation);
• распределенная бизнес-логика (RBL – Remote business logic);
• распределенное управление данными (DDM – Distributed data manegement);
• удаленное управление данными (RDM – Remote data manegement).
Эта условная классификации показывает, как могут быть распределены отдельные задачи между серверным и клиентскими процессами. В этой классификации отсутствует реализация удаленной бизнес-логики. Считается, что она не может быть удалена сама по себе полностью, а может быть лишь распределена между разными процессами, которые могут взаимодействовать друг с другом.
Двухуровневые модели
Двухуровневая модель фактически является результатом распределения пяти указанных выше функций между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере. В чистом виде почти никакая модель не существует, однако рассмотрим наиболее характерные особенности каждой двухуровневой модели: модели удаленного управления данными и модели удаленного доступа к данным.
Модель удаленного управления данными. Она также называется моделью файлового сервера (FS – File Server). В этой модели презентационная логика и бизнес-логика располагаются на клиентской части. На сервере располагаются файлы с данными, и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиентской части.
Распределение функций в этой модели представлено на рис. 3.

В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база метаданных, находится на клиенте.
Достоинство этой модели заключается в том, что приложение разделено на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами.
Собственно СУБД должна находиться в этой модели на клиентском компьютере.
Алгоритм выполнения клиентского запроса сводится к следующему.
1. Запрос формулируется в командах ЯМД.
2. СУБД переводит этот запрос в последовательность файловых команд.
3. Каждая файловая команда вызывает перекачку блока информации на компьютер клиента, а СУБД анализирует полученную информацию; если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации, и т.д.
4. Перекачка информации с сервера на клиентский компьютер производится до тех пор, пока не будет получен ответ на запрос клиента.
Данная модель имеет следующие недостатки:
• высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению;
• узкий спектр операций манипулирования с данными, который определяется только файловыми командами;
• отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
Модель удаленного доступа к данным. В модели удаленного доступа (RDA – Remote Data Access) база данных хранится на сервере. На сервере же находится и ядро СУБД. На компьютере клиента располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL.
Структура модели удаленного доступа приведена на рис. 4.

Рис.4. Структура модели удаленного доступа к данным
Преимущества данной модели заключаются в следующем:
• перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгружает сервер БД, сводя к минимуму общее число выполняемых процессов в операционной системе;
«сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных запросов и транзакций;
• резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, а их объем существенно меньше. В ответ на запросы клиент получает только данные, соответствующие запросу, а не блоки файлов.
Основное достоинство RDA-модели — унификация интерфейса клиент—сервер (стандартом при общении приложения-клиента и сервера становится язык SQL).
Данная модель имеет следующие недостатки:
• запросы на языке SQL при интенсивной работе клиентской части приложения могут существенно загрузить сеть;
• так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование приложения;
• сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Двухуровневые модели
Двухуровневая модель фактически является результатом распределения пяти указанных функций между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере. В чистом виде почти никакая модель не существует, однако рассмотрим наиболее характерные особенности каждой двухуровневой модели.
Модель удаленного управления данными. Модель файлового сервера

Модель удаленного управления данными также называется моделью файлового сервера (File Server, FS). В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиенте. Распределение функций в этой модели представлено на рис. 10.4. В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база мета-данных, находится на клиенте. Рис. 10.4. Модель файлового сервера Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на клиенте. Каков алгоритм выполнения запроса клиента? Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации и т. д. Перекачка информации с сервера на клиент производится до тех пор, пока не будет получен ответ на запрос клиента. Недостатки:
- высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению;
- узкий спектр операций манипулирования с данными, который определяется только файловыми командами;
- отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
Модель удаленного доступа к данным
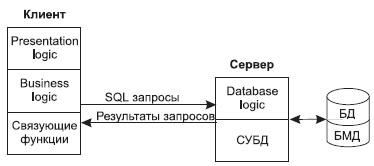
В модели удаленного доступа (Remote Data Access, RDA) база данных хранится на сервере. На сервере же находится ядро СУБД. На клиенте располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на рис. 10.5. Рис. 10.5. Модель удаленного доступа (RDA) Преимущества данной модели:
- перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД, сводя к минимуму общее число процессов в операционной системе;
- сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. (Это становится возможным, если отказаться от терминалов, не располагающих ресурсами, и заменить их компьютерами, выполняющими роль клиентских станций, которые обладают собственными локальными вычислительными ресурсами);
- резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, релевантные запросу, а не блоки файлов, как в FS-модели.
Основное достоинство RDA-модели — унификация интерфейса «клиент-сервер», стандартом при общении приложения-клиента и сервера становится язык SQL. Недостатки:
- все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть;
- так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование кода приложений;
- сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте. Действительно, например, если нам необходимо выполнять контроль страховых запасов товаров на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаление товара со склада, должно выполнять проверку на объем остатка, и в случае, если он меньше страхового запаса, формировать соответствующую заявку на поставку требуемого товара. Это усложняет клиентское приложение, с одной стороны, а с другой — может вызвать необоснованный заказ дополнительных товаров несколькими приложениями.
Источник: studfile.net