Двухуровневая модель фактически является результатом распределения пяти указанных функций между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере. В чистом виде почти никакая модель не существует, однако рассмотрим наиболее характерные особенности каждой двухуровневой модели.
Модель удаленного управления данными. Модель файлового сервера
Модель удаленного управления данными также называется моделью файлового сервера ( File Server , FS). В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиенте.
Распределение функций в этой модели представлено на рис. 10.4.
В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база мета-данных, находится на клиенте.
Бизнес-логика в Django и архитектура Django проектов — на настоящем примере
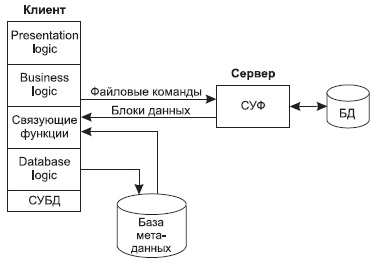
Рис. 10.4. Модель файлового сервера
Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на два взаимодействующих процесса. При этом сервер ( серверный процесс ) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на клиенте.
Каков алгоритм выполнения запроса клиента?
Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации и т. д.
Перекачка информации с сервера на клиент производится до тех пор, пока не будет получен ответ на запрос клиента.
- высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению;
- узкий спектр операций манипулирования с данными, который определяется только файловыми командами;
- отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
Модель удаленного доступа к данным
В модели удаленного доступа (Remote Data Access, RDA ) база данных хранится на сервере. На сервере же находится ядро СУБД. На клиенте располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на рис.
10.5.

Рис. 10.5. Модель удаленного доступа (RDA)
Преимущества данной модели:
Архитектура ПО, MVC и бизнес-логика. Критика Django
- перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД, сводя к минимуму общее число процессов в операционной системе;
- сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. (Это становится возможным, если отказаться от терминалов, не располагающих ресурсами, и заменить их компьютерами, выполняющими роль клиентских станций, которые обладают собственными локальными вычислительными ресурсами);
- резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, релевантные запросу, а не блоки файлов, как в FS-модели.
Основное достоинство RDA -модели — унификация интерфейса «клиент-сервер», стандартом при общении приложения-клиента и сервера становится язык SQL.
- все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть;
- так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование кода приложений;
- сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте. Действительно, например, если нам необходимо выполнять контроль страховых запасов товаров на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаление товара со склада, должно выполнять проверку на объем остатка, и в случае, если он меньше страхового запаса, формировать соответствующую заявку на поставку требуемого товара. Это усложняет клиентское приложение, с одной стороны, а с другой — может вызвать необоснованный заказ дополнительных товаров несколькими приложениями.
Модель сервера баз данных
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия:
- Необходимо, чтобы БД в каждый момент отражала текущее состояние предметной области , которое определяется не только собственно данными, но и связями между объектами данных. То есть данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми.
- БД должна отражать некоторые правила предметной области, законы, по которым она функционирует ( business rules ). Например, завод может нормально работать только в том случае, если на складе имеется некоторый достаточный запас (страховой запас) деталей определенной номенклатуры, деталь может быть запущена в производство только в том случае, если на складе имеется в наличии достаточно материала для ее изготовления, и т. д.
- Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них: например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры, при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара.
- Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи.
- Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, то есть такие, которые определены в DDL ( data definition language ) — языке описания данных, который является частью SQL. Однако в реальных предметных областях у нас действуют данные, которые несут в себе еще и семантическую составляющую, например, это координаты объектов или единицы различных метрик, например рабочая неделя в отличие от реальной имеет сразу после пятницы понедельник.
Данную модель поддерживают большинство современных СУБД: Informix , Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры. Модель сервера баз данных представлена на рис. 10.6.

Рис. 10.6. Модель активного сервера БД
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД.
Термин «триггер» взят из электроники и семантически очень точно характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры.
Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров , может быть инициатором обработки данных в БД.
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так называемый встроенный SQL . Встроенный SQL мы рассмотрим в «Встроенный SQL» .
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции:
- осуществляет мониторинг событий, связанных с описанными триггерами;
- обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
- обеспечивает исполнение внутренней программы каждого триггера;
- запускает хранимые процедуры по запросам пользователей;
- запускает хранимые процедуры из триггеров;
- возвращает требуемые данные клиенту;
- обеспечивает все функции СУБД : доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД.
Если мы переложили на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом», в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с » толстым клиентом «.
Для разгрузки сервера была предложена трехуровневая модель.
Модель сервера приложений
Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Архитектура трехуровневой модели приведена на рис. 10.7. Этот промежуточный уровень содержит один или несколько серверов приложений.
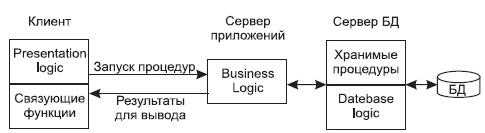
Рис. 10.7. Модель сервера приложений
В этой модели компоненты приложения делятся между тремя исполнителями:
- Клиент обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД , расположенной на компьютере-клиенте. Клиент исполняет коммуникационные функции front-end части приложения, которые обеспечивают доступ клиенту в локальную или глобальную сеть. Дополнительно реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует тем случаям, когда клиент также является клиентом менеджера распределенных транзакций.
- Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения общих незагружаемых функций для клиентов. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, поддерживают сетевую доменную операционную среду, хранят и исполняют наиболее общие правила бизнес-логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях.
- Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application).
Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-приложений. (On-line analytical processing .) В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного SQL , реализованного в конкретной СУБД , и может быть выполнена на стандартных языках программирования, таких как C, C++, SmallTalk, Cobol. Это повышает переносимость системы, ее масштабируемость .
Функции промежуточных серверов могут быть в этой модели распределены в рамках глобальных транзакций путем поддержки XA-протокола (X/Open transaction interface protocol ), который поддерживается большинством поставщиков СУБД .
Источник: intuit.ru
3. Logical DB model
Логическая модель РБД. Бизнес-логика файл-серверной, клиент-серверной и N-уровневой архитектуры.
Логическая модель РБД
Логическая модель РБД строится на 3-х уровнях (слоях) абстракции данных: представления информации, обработки(бизнес- логики) и хранения. Слои образуют строгую иерархию: слой бизнес -логики взаимодействует со слоями хранения и представления. Физически, слои могут входить в состав одного программного модуля, или же распределяться на нескольких параллельных процессах в одном или нескольких узлах сети.
- Слой представления информации
Обеспечивает интерфейс с пользователем. Как правило, получение информации от пользователя происходит посредством различных форм. А выдача результатов запросов — посредством отчетов. - Слой бизнес-логики
Связующий, именно он определяет функциональность и работоспособность системы в целом. Блоки программного кода распределены по сети и могут использоваться многократно (CORBA, DCOM) для создания сложных распределенных приложений. - Слой хранения данных
Обеспечивает физическое хранение, добавление, модификацию и выборку данных. На данный слой также возлагается проверка целостности и непротиворечивости данных, а также реализацию разделенных транзакций.
Слои распределенной системы могут быть по разному реализованы и исполняться в разных узлах сети. Обычно рассматриваются следующие архитектуры
Слой Тип архитектуры
Клиент-сервер
(Бизнес-логика на клиенте)
Клиент-сервер
(бизнес-логика на сервере)
Сервер приложений
(комп. кластер)
Файл- сервер (или клиент)
Все три слоя образуют единый программный модуль
Пользоват. Интерфейс и бизнес-логика образуют единый модуль. Данные хранятся на сервере БД
Вся бизнес логика реализована в виде хранимых процедур, исполняемых на сервере БД
Все слои исполняются на разных машинах.
Файл-сервер
В системах, построенных по архитектуре файл-сервера все слои системы представляют единое и неделимое целое. БД хранится в виде файла или набора файлов на файл-сервере. Вся логика выборки, хранения и обеспечения непротиворечивости данных возлагается на клиентскую часть. Файл- серверные системы ориентированы на работу с отдельными записями в таблице.
Достоинства
- Простота логики.
- Низкие требования к аппаратному обеспечению и малый объем требуемой памяти.
- Не требуют надежных многозадачных и многопользовательских ОС.
- Невысокая цена СУБД.
Недостатки
- Ограниченность языка и негибкость среды разработки приложений
- Слабая масштабируемость
- Не обеспечивают многопользовательский режим работы
- Трудно поддерживать целостность и непротиворечивость данных
- Необходимость ручной блокировки записей или таблиц целиком.
- Низкий уровень защищенности как внешней (от взлома), так и внутренней (от ошибок приложений) Например индексы отдельно от таблиц.
- Не имеют средств шифрации сетевого трафика
- Создают высокую нагрузку на сеть
Выводы
Файл-серверная архитектура является достаточно привлекательной альтернативой для создания однопользовательских ИС со слабыми требованиями к защите данных.
Клиент-сервер с бизнес-логикой на клиенте
В данных системах хранение, выборка и поддержание непротиворечивости данных возлагается на сервер БД, а вся бизнес-логика и логика представления исполняются на клиентских машинах. Так как все операции по манипулированию данными осуществляются только через сервер, производительность и сохранность данных зависит только от сервера БД. Серверы БД изначально рассчитаны на многопользовательский режим работы, имеют эффективные алгоритмы кеширования данных. Современные серверы имеют хорошую масштабируемость.
Клиентская часть обменивается данными с сервером посредством SQL запросов. Обработка информации в клинт-серверных системах ведется на уровне множества кортежей.
Процесс разработки разделяется на создание БД и написание клиентской части с бизнес-логикой.
Достоинства
- Высокая производительность, стабильность и надежность при многопользовательской работе.
- Легко организуется защита данных (шифрование сетевого трафика SSH, SSL )
- Универсальность языка определения и манипулирования данными
Недостатки
- Более высокая цена СУБД. (сервер БД продается отдельно).
- Достаточно высокие требования к квалификации разработчиков
- Навыки администрирования сервера БД
- Повышенные требования к пропускной способности сети
- Повышенные требования к клиентским местам (на них выполняется слой бизнес- логики)
Выводы
При количестве пользователей от 2 до ~50 она является хорошим вариантом. С ростом числа пользователей начинает сказываться недостаточная пропускная способность сети.
Клиент-сервер с бизнес-логикой на сервере.
Используется возможность современных серверов БД исполнять хранимые SQL процедуры на сервере, куда и переносится максимально возможная часть бизнес-логики. Требования к серверу БД возрастают, однако резко понижаются требования к клиентским машинам (за счет выноса с них бизнес-логики) и к пропускной способности сети (клиенту передаются только данные, необходимые пользователю).
Достоинства
- Пониженные, по сравнению с предыдущим классом систем, требования к пропускной способности сети и клиентским местам.
- Более простой процесс создания бизнес-логики.
Недостатки
- Повышенные требования к серверу БД.(каждый сеанс «съедает» память из расчета предельной загрузки)
- Невысокая переносимость ( мобильность) системы на другие серверы БД.
Выводы
По сравнению с предыдущими классами, позволяет держать большую нагрузку.
N-уровневая архитектура
Основными элементами являются сервера БД, сервер(кластер) приложений и клиентская часть. Главная идея n-уровневой архитектуры заключается в максимальном упрощении клиента (тонкий клиент) , выносе всей бизнес-логики с клиента и сервера БД.
Тонкий клиент представляет собой некоторый терминал типа HTML-browser или эмуляторы X-терминала
Вся бизнес- логика оформляется в виде набора приложений, запускаемых на сервере приложений под управлением ОС типа UNIX.
Сервера БД занимаются только проблемами хранения, добавления, модификации и поддержания непротиворечивости данных.
Сервер приложений соединен с сервером БД при помощи отдельного высокоскоростного сегмента сети.
Достоинства
- Повышенная защищенность.
- Высокая производительность.
- Легкость развития и модификации.
- Легкость администрирования.
- Возможность создания системы с массовым параллелизмом (серверов БД может быть несколько, а сервером приложений могут служить несколько соединенных в кластер компьютеров).
Недостатки
- Высокая сложность.
- Высокая цена решения.
- В некоторых случаях уступает по производительности клиент-серверным системам с бизнес-логикой на сервере.
Выводы
Единственная альтернатива для создания ИС для очень большого количества пользователей.
- Нет меток
Источник: mai.moscow
Модели архитектуры клиент-сервер: rda-модель, dbs-модель, as-модель. Преимущества и недостатки.
Выделяют три основных модели архитектуры клиент-сервер:
- модель доступа к удаленным данным или модель удаленного доступа к данным (Remote Data Access – RDA-модель);
- модель сервера баз данных или модель удаленного представления (Database Server – DBS-модель);
- модель сервера приложений или модель распределенной функции (Application Server – AS-модель).
RDA-модель В модели доступа к удаленным данным на компьютере-клиенте располагаются презентационная логика и бизнес-логика приложений. На сервере находится ядро СУБД. Функции сервера определяются управлением данными и обработкой запросов со стороны клиентов. Клиент обращается к серверу с запросами на языке SQL. В ответ на запрос клиент получает только данные, соответствующие запросу. Основное достоинство данной модели состоит в том что, во-первых, взаимодействие пользователя с сервером осуществляется с помощью стандартного языка запросов SQL. Во-вторых, это наличие большого числа готовых СУБД и других инструментальных средств, обеспечивающих быстрое создание программ клиентской части. Недостатки RDA-модели:
- высокая загрузка системы передачи данных;
- неудобны с точки зрения разработки, модификации и сопровождения. Так как в этой модели на клиенте располагается и презент. логика, и бизнес-логика приложений, то при повторении аналогичных функций в различных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование кода приложений.
DBS-модель В модели сервера баз данных на компьютере-клиенте располагаются части приложения, реализующие только функции представления, а прикладные функции, определяющие основные алгоритмы решения задач приложения и включающие обеспечение целостности, безопасности и секретности, реализуются на стороне сервера. Работа приложения основана на механизме хранимых процедур и триггеров. Хранимые процедуры – это специальные программные модули, которые используются для извлечения или изменения данных. Существует два вида хранимых процедур: системные и пользовательские. Системные хранимые процедуры предназначены для получения информации из системных таблиц и выполнения различных служебных операций. Чаще всего такие процедуры используются при администрировании базы данных. Пользовательские хранимые процедуры создаются непосредственно разработчиками или администраторами базы данных. Обычно процедуры хранятся в словаре базы данных и могут разделяться между несколькими клиентами. Выполняются хранимые процедуры на том же компьютере, где функционирует SQL-сервер. Хранимые процедуры пишутся на процедурном языке, который зависит от конкретной СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет ее и возвращает клиенту требуемые данные. Механизм триггеров позволяет выполнять централизованный контроль целостности базы данных. Триггер – это особый тип хранимой процедуры, автоматически выполняющейся при каждой попытке изменить данные. Триггер, как и хранимая процедура, хранится в словаре базы данных. Если триггер вызывает ошибку в запросе, обновление информации не производится, а в приложение возвращается сообщение об ошибке. Достоинства модели сервера баз данных: возможность централизованного администрирования приложений и обеспечения целостности, а также эффективное использование вычислительных и коммуникационных ресурсов. Недостатки DBS-модели: ограниченность действий, выполняемых с помощью хранимых процедур и триггеров и очень большая загрузка сервера. AS-модель Модель сервера приложений является трехзвенной моделью. На компьютере пользователя расположены приложения клиентов, обеспечивающие пользовательский интерфейс. Это нижний уровень модели. Между клиентом и сервером вводится дополнительный промежуточный уровен – сервер приложений, обеспечивающий управление данными и реализующий несколько прикладных функций. Серверов приложений может быть несколько, в зависимости от вида предоставляемого сервиса. Любая программа, запрашивающая услугу у сервера приложений, является для него клиентом. На верхнем, третьем уровне располагается удаленный сервер баз данных, выполняющий функции управления информационными ресурсами базы данных. Трехзвенная модель эффективна в тех случаях, когда требуется выполнить сложные аналитические расчеты над базой данных. К достоинствам AS-модели относят разгрузку сервера базы данных, к недостаткам – увеличение нагрузки на сеть.
- ТехнологииCOMDCOM, CORBA, MIDAS, EJB.
COMDCOM Технология COM (Component Object Model) и ее вариант для распределенных систем DCOM(Distributed Component Object Model) была разработана компанией Microsoft. DCOM является расширением COM и включает в себя среду распределенных вычислений и механизм удаленного вызова процедур. Технология СОМ предоставляет модель связи и взаимодействия между компонентами и приложениями, а также реализация клиент-серверных взаимодействий при помощи интерфейсов. Технология СОМ применяется при описании API и двоичного стандарта для связи объектов различных языков и сред программирования. Технология СОМ работает с так называемыми СОМ-объектами. СОМ-объект представляет собой двоичный код, который выполняет какую-либо функцию и имеет один или более интерфейс. Все СОМ-объекты обычно содержатся в файлах с расширением DLL или OCX. Один такой файл может содержать как одиночный СОМ-объект, так и несколько СОМ-объектов. СОМ-объекты похожи на обычные объекты визуальной библиотеки компонентов Delphi. В отличие от объектов VCL Delphi, СОМ-объекты содержат свойства, методы и интерфейсы. СутьCOM Программа-клиент использует при своей работе объект (объекты) некоторой другой программы (сервера) так, словно эти объекты являются частью самого клиента. Основную роль при этом играет интерфейс объектов. Клиенты СОМ связываются с объектами при помощи СОМ-интерфейсов. Обычный СОМ-объект включает в себя один или несколько интерфейсов. Каждый из этих интерфейсов имеет собственный указатель. Интерфейсы – это группы логически или семантически связанных процедур, которые обеспечивают связь между поставщиком услуги (сервером) и его клиентом. Клиент получает именно интерфейс затребованного объекта. Интерфейсы не являются самостоятельными объектами, они лишь обеспечивают доступ к объектам. Таким образом, клиенты не могут напрямую обращаться к данным, доступ осуществляется при помощи указателей интерфейсов. Каждый интерфейс имеет свой уникальный идентификатор, который называется глобальный уникальный идентификатор (Globally Unique Identifier, GUID). Уникальные идентификаторы интерфейсов называют идентификаторами интерфейсов (Interface Identifiers, IIDs). Данные идентификаторы обеспечивают устранение конфликтов имен различных версий приложения или разных приложений. Технология СОМ имеет два явных преимущества:
- создание СОМ-объектов не зависит от языка программирования. Таким образом, СОМ-объекты могут быть написаны на различных языках;
- СОМ-объекты могут быть использованы в любой среде программирования под Windows. В число этих сред входят Delphi, Visual C++, C++Builder, Visual Basic, и многие другие.
Хотя технология СОМ обладает явными плюсами, она имеет также и минусы, среди которых зависимость от платформы. Данная технология применима только в операционной системе Windows и на платформе Intel. CORBA CORBA (Common Request Broker Architecture) – архитектура для построения распределенных объектных приложений. Была предложена некоммерческой организацией – консорциумом OMG (Object Management Group). Технология основана на использовании брокера объектных запросов (Object Request Broker, ORB) для прозрачной отправки и получения объектами запросов в распределенном окружении. Технология позволяет строить приложения из распределенных объектов, реализованных на различных языках программирования. Как и DCOM, CORBA основывается на коммуникации типа клиент-сервер. CORBA-технология также использует интерфейс объекта. Но в этом случае схема взаимодействия объектов включает промежуточное звено (Smart agent), реализующее доступ к удаленным объектам. Smart agent моделирует сетевой каталог известных ему серверов объектов. На машине клиента создаются два объекта-посредника: Stab и ORB (Object Request Broker – брокер вызываемого объекта). ORB отвечает за все механизмы, необходимые для поиска подходящей для запроса реализации объекта, подготовки реализации к получению запроса и передачи данных в процессе выполнения запроса. Stub передает вызов брокеру, который посылает сообщение в сеть. Smart agent, получив сообщение, отыскивает сетевой адрес сервиса и передает запрос брокеру, размещенному на машине сервера. Вызов требуемого объекта производится через специальный адаптер (BOA). MIDAS MIDAS (Multi-tier Application Server Suite) представляет собой технологию создания распределенных систем, состоящих из сервера баз данных, сервера доступа к данным (который, в свою очередь, является клиентом сервера баз данных) и так называемого тонкого клиентского приложения, являющегося, соответственно, клиентом сервера доступа к данным (рис.). Фактически два последних звена делят между собой функциональность, характерную для клиентского приложения, используемого в «классических» двухзвенных клиент-серверных системах. «Тонкий» клиент обычно является приложением, с которым работает конечный пользователь, и поэтому предназначен главным образом для предоставления пользовательского интерфейса (то есть тех форм и интерфейсных элементов, с помощью которых пользователь редактирует данные). Естественно, подобное приложение должно «знать», на каком компьютере локальной или глобальной сети находится сервер доступа к данным, каково имя (или иной идентификатор) предоставляемого им сервиса и с помощью каких средств (имеются в виду сервисы операционной системы, сетевые протоколы и т.д.) с ним можно этими данными обмениваться. Это и есть те немногочисленные параметры, которые требуют настройки. Что касается сервера доступа к данным, то обычно он недоступен конечным пользователям, и поэтому хотя у него может быть пользовательский интерфейс в традиционном понимании (формы, кнопки, поля для ввода данных), но не обязательно. Иными словами, сервер доступа к данным может представлять собой как обычное Windows-приложение с формами, так и приложение без форм, а также консольное приложение либо сервис операционной системы, пишущий сообщения для администратора системы в log-файл. Его задача — обмениваться данными с «тонким» клиентом и обращаться к серверу баз данных с собственными запросами (обычно инициированными этим обменом). Поэтому сервер доступа к данным должен, с одной стороны, предоставлять клиентам интерфейсы, позволяющие получать от него данные, а с другой стороны, быть полноценным клиентом сервера баз данных, то есть содержащий его компьютер должен иметь как минимум установленную клиентскую часть серверной СУБД. Нередко такой компьютер имеет и другие библиотеки доступа к данным, например, в прежних двух версиях MIDAS обязательной составляющей его частью была библиотека Borland Database Engine. В текущей версии MIDAS могут быть использованы и другие библиотеки, например библиотеки ADO (или исключительно те библиотеки, что содержат клиентский API и поставляются с сервером баз данных). EJB Основная идея, лежавшая в разработке технологии EJB (Enterprise JavaBeans) – создать такую инфраструктуру для компонент, чтобы они могли бы легко «вставляться» («plug in») и удаляться из серверов, тем самым увеличивая или снижая функциональность сервера. Существует подход построения информационной системы EJB (Enterprise JavaBeans) – разделение ее на три уровня. Каждый уровень имеет свои обязанности и функциональные возможности. На первом уровне находится клиентское приложение, которое занимается в основном презентационным слоем системы. Второй уровень отвечает за бизнес-логику системы и взаимодействует с презентационным слоем, отвечая на его запросы – уровень сервера приложений. Еще одним преимуществом является возможность групповой работы над системой, в которой каждый из уровней разрабатывается независимо. Кто-то проектирует структуры баз данных, кто-то «рисует» презентационные слои, а кто-то пишет оптимальные алгоритмы. Компонентная технология EJB ориентирована на возможность распределения второго уровня, т.е. если Ваш сервер приложений не справляется с нагрузкой, то есть возможность без единого изменения кода сервера приложений, разнести его на несколько вычислительных машин. А компоненты, из которых состоит второй уровень, не будут чувствовать разницы между работой на одной вычислительной машине и на нескольких машинах. Минусом таких систем является их направленность на крупные корпоративные решения.
Ограничение
Для продолжения скачивания необходимо пройти капчу:
Источник: studfile.net