Об анализе информации в применении к бизнес-процессам в последнее время говорят много. Плохо лишь то, что под этим термином каждый понимает то, что ему нужно, часто не имея общей картины по проблеме. Фрагментарность в подходе напоминает другое, к сожалению, распространенное явление — «лоскутную автоматизацию», когда на отдельные рабочие места устанавливаются разрозненные, слабо взаимосвязанные программные средства.
С анализом ситуация аналогичная: очень часто в качестве «полнофункционального решения» предлагаются разрозненные механизмы, покрывающие только незначительную часть задач.
Как человек принимает решения?
Объяснить, как рождается мысль, мы, конечно, не в состоянии. Поэтому сконцентрируемся на том, как можно в этом процессе использовать информационные технологии. Первый вариант: лицо, принимающее решение (далее буду называть его ЛПР), использует компьютер только как средство извлечения данных, а выводы делает уже самостоятельно.
Для решения такого рода задач используются системы отчетности, многомерный анализ данных, диаграммы. Второй вариант: программа не только извлекает данные, но и проводит их предобработку, например, очистку, сглаживание и пр., а к обработанным таким образом данным применяет математические методы анализа — кластеризацию, классификацию, регрессию и т.д. В этом случае человек работает уже с моделями, подготовленными компьютером.
В первом случае практически все, что связано собственно с механизмами принятия решений, возлагается на человека, а потому проблема с подбором адекватной модели и выбором методов обработки выносится за пределы механизмов анализа. Базой для принятия решения является либо инструкция (например, каким образом можно реализовать механизмы реагирования на отклонения), либо интуиция. Иногда этого вполне достаточно, но если ЛПР интересуют знания, находящиеся достаточно глубоко, то простое извлечение данных тут не поможет. Это и есть тот самый второй случай, когда лишь надежные механизмы предобработки и анализа позволят ЛПР работать на более высоком уровне. И если первый вариант хорошо подходит для решения тактических и оперативных задач, то второй — для тиражирования знаний и решения стратегических проблем.
В идеале человеку нужна возможность применять оба подхода к анализу, варьируя методики в зависимости от задач. Вместе они позволяют покрыть почти все потребности организации при работе с бизнес-информацией.
Элементы анализа
Часто при описании того или иного продукта, анализирующего бизнес-информацию, применяют такие термины как «риск-менеджмент», «прогнозирование», «сегментация рынка»… Но в действительности решения каждой из этих практических задач сводятся к применению одного из описанного ниже методов анализа. Например, прогнозирование — это задача регрессии, сегментация рынка — это кластеризация, управление рисками — это комбинация кластеризации, классификации и, возможно, других методов. Фактически, они являются атомарными (базовыми) элементами, из которых собирается решение той или иной задачи (см. схему).
Источники данных
В качестве первичного источника данных должны выступать все сведения, которые могут пригодиться для принятия решения — базы данных систем управления предприятием, офисные документы, Интернет. Причем речь идет не только о внутренних, но и о внешних данных (макроэкономические показатели, конкурентная среда, демографические данные и т.п.).
Хранение данных
Хотя в хранилище данных не реализуются технологии анализа, оно является той базой, на которой нужно строить аналитическую систему. При отсутствии хранилища данных на сбор и систематизацию необходимой для анализа информации будет уходить большая часть времени. Что в значительной степени сведет на нет все достоинства анализа — ведь одним из ключевых показателей любой аналитической системы является возможность быстро получить результат.
Семантический слой
Следующий элемент схемы — семантический слой. Вне зависимости от того, каким образом будет анализироваться информация, необходимо, чтобы она была понятна ЛПР. В большинстве случаев анализируемые данные располагаются в различных базах данных, а ЛПР не должен вникать в нюансы работы с СУБД.
Поэтому требуется создать некий механизм, трансформирующий термины предметной области в вызовы механизмов доступа к БД. Эту задачу и выполняет семантический слой. Желательно, чтобы он был один для всех приложений анализа — так будет легче применять к задаче различные подходы.
Системы отчетности
Предназначение систем отчетности — ответ на вопрос «что происходит». Первый вариант их использования — регулярные отчеты для контроля оперативной ситуации и анализа отклонений. Например, система ежедневно готовит отчеты об остатке продукции на складе, и когда его значение меньше значения средней недельной продажи, необходимо отреагировать подготовкой заказа на поставку. Обычно этот подход в том или ином виде реализован в компаниях (пусть даже просто на бумаге), но нельзя допускать, чтобы это был единственный из доступных подходов к анализу данных.
Второй вариант применения систем отчетности — обработка нерегламентированных запросов. Когда ЛПР хочет проверить какую-либо мысль (гипотезу), ему необходимо получить пищу для размышлений, подтверждающую либо опровергающую идею. Идеи, как известно, приходят спонтанно, а потому невозможно точно предсказать, какого рода информация потребуется. Это означает, что необходим инструмент, позволяющий быстро и в удобном виде нужную информацию получить. Извлеченные данные обычно представляются либо в виде таблиц, либо в виде графиков и диаграмм, хотя возможны и другие представления.
Механизм OLAP
Хотя для построения систем отчетности можно применять различные подходы, самый распространенный на сегодня — это OLAP. Основной его идеей является представление информации в виде многомерных кубов, где оси являют собой измерения (например, время, продукты, клиенты), а в ячейках помещаются показатели (сумма продаж, средняя цена закупки). Пользователь манипулирует измерениями и получает информацию в нужном разрезе.
Благодаря простоте понимания и наглядности OLAP получил широкое распространение в качестве механизма анализа данных, но необходимо понимать, что его возможности в области более глубокого анализа — например, прогнозирования — крайне ограничены. Основной проблемой при решении задач прогнозирования является вовсе не возможность извлечения интересующих данных в виде таблиц и диаграмм, а построение адекватной модели.
Если модель есть, дальше все достаточно просто: на ее вход подается новая информация, пропускается через нее, а результат — это и есть прогноз. Но вот собственно построение такой модели является совершенно нетривиальной задачей! Конечно, можно заложить в систему несколько готовых простых моделей, например, линейную регрессию или что-то аналогичное.
Довольно часто именно так и поступают, но, увы, это проблему не решает, поскольку реальные задачи почти всегда выходят за рамки простых моделей. А, следовательно, будут обнаружены только явные зависимости, ценность которых незначительна, либо прогноз будет слишком грубым, что тоже совершенно неинтересно.
Приведу пример: если при анализе курса акций на фондовом рынке вы будете исходить из простого предположения, что завтра акции будут стоить столько же, сколько и сегодня, то в 90% случаев вы угадаете. Но насколько ценны такие знания? Интерес для брокеров представляют только оставшиеся 10%. Примитивные модели в большинстве случаев дают результат примерно того же уровня.
Собственно, задача построения прогнозов и тому подобные вещи выходят за рамки механизмов систем отчетности, поэтому и не стоит ждать от OLAP положительных результатов в этом направлении. Для решения задач более глубокого анализа применяется совершенно другой набор технологий, объединенных под названием Knowledge Discovery in Databases.
Knowledge Discovery in Databases
KDD — это процесс поиска полезных знаний в «сырых данных». KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining (DM), постобработки данных, интерпретации полученных результатов.
Привлекательность этого подхода заключается в том, что, вне зависимости от предметной области, мы применяем одни и те же операции:
- Извлечь данные. В нашем случае для этого нужен семантический слой.
- Очистить данные. Применение для анализа «грязных» данных может полностью свести на нет применяемые в дальнейшем механизмы анализа.
- Трансформировать данные. Различные методы анализа требуют данных, подготовленных в специальном виде. Например, где-то в качестве входов может использоваться только цифровая информация.
- Провести собственно анализ — Data Mining.
- Интерпретировать полученные результаты.
Этот процесс повторяется итеративно, и, по сути, это все, что необходимо сделать, чтобы автоматизировать процесс извлечения знаний. Дальнейшие шаги уже делает эксперт, он же ЛПР.
Data Mining — метод обнаружения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных для интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. DM обеспечивает решение всего шести задач — классификация, кластеризация, регрессия, ассоциация, последовательность и отклонения.
- Классификация — это отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
- Кластеризация — это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность объектов. Объекты внутри кластера должны быть «похожими» друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация.
- Регрессия , в том числе задачи прогнозирования . Установление функциональной зависимости между зависимыми и независимыми переменными.
- Ассоциация — выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
- Последовательные шаблоны — установление закономерностей между связанными во времени событиями. Например, после события X через определенное время произойдет событие Y.
- Анализ отклонений — выявление наиболее нехарактерных шаблонов.
И снова человек
Интерпретация результатов компьютерной обработки возлагается на человека. Различные методы дают различную пищу для размышлений: в самом простом случае это таблицы и диаграммы, а в более сложном — модели и правила. Полностью исключить участие человека нельзя, ведь тот или иной результат не имеет никакого значения, пока не будет применен к конкретной предметной области.
Но зато существует возможность тиражировать знания . Например, ЛПР при помощи какого-либо метода определил, какие показатели влияют на кредитоспособность покупателей, и представил это в виде правила. Правило можно внести в систему выдачи кредитов и таким образом значительно снизить кредитные риски, поставив их оценки на поток. При этом от человека, занимающегося собственно выпиской документов, не требуется глубокого понимания причин того или иного вывода. Фактически, это перенос методов, когда-то примененных в промышленности, в область управления знаниями. Основная идея — переход от разовых и неунифицированных методов к конвейерным.
Сами задачи и методы их решения не зависят от инструментария — можно применять все что угодно, начиная от классических статистических методов и заканчивая самообучающимися алгоритмами. Практически все реальные бизнес-задачи — прогнозирование, сегментация рынка, оценка риском, оценка эффективности рекламных кампаний, оценка конкурентных преимуществ и множество других — сводятся к описанным выше и решаются одним из указанных выше методов (или их комбинацией).
На практике под системой анализа бизнес-информации чаще всего понимается только OLAP, чего совершенно недостаточно для полноценного анализа. Под толстым слоем рекламных лозунгов находится всего лишь система построения отчетов. Эффектные описания того или иного инструмента анализа скрывают суть, но достаточно отталкиваться от предложенной схемы, и вы будете понимать действительное положение вещей. Лишь имея в распоряжении инструмент, решающий весь приведенный список задач, можно говорить, что вне зависимости от природы исследуемых объектов вы готовы справиться с любой задачей бизнес-анализа и выжать из данных максимум полезной информации, которая, собственно, и называется знаниями.
Аналитический пакет Deductor от BaseGroup Labs представляет собой достаточно последовательную реализацию всей этой схемы. По сути, Deductor — это не набор программ, реализующих ту или иную технологию, а пакет, поддерживающий процесс анализа данных. Если рассматривать его именно в таком ракурсе, понятно, почему в него включен тот или иной модуль.
Пакет состоит из пяти интегрированных между собой модулей:
- Cube Analyzer — OLAP-модель
- RawData Analyzer — предобработка данных
- Tree Analyzer — деревья решений
- Neural Analyzer — нейронные сети
- SOMap Analyzer — самоорганизующиеся карты
Для решения задач построения систем отчетности применяется программа Cube Analyzer. Это OLAP модуль, построенный на основе оригинального высокопроизводительного ядра. Программист один раз настраивает систему шаблонов, которые и реализуют семантический слой, а далее пользователь в мастере построения кубов указывает, что он хочет получить, выбирая измерения, срезы, факты.
И получает результат в виде таблиц и диаграмм с возможностью произвольного манипулирования данными. Таким образом обрабатываются нерегламентированные запросы. Любой из настроенных запросов пользователь может сохранить под определенным именем и в дальнейшем получать результат просто выбором того или иного отчета из списка. Так реализуется получение регулярных отчетов.
Результаты извлечения можно просмотреть в виде обычной таблицы, кросс-таблицы и диаграммы. Остальные механизмы обработки реализованы в других приложениях пакета. Т.к. основной идеей является возможность «рассмотреть данные» с разных сторон, в систему встроены механизмы импорта таблиц в различные форматы и обмена данными между приложениями пакета Deductor.
Для решения задач KDD применяется набор их 4-х приложений. RawData Analyzer — предобработка и очистка данных, Tree Analyzer — классификация, Neural Analyzer — регрессия и классификация, SOMap Analyzer — кластеризация. Все приложения получают данные из разнородных источников при помощи единого мастера подключений, реализующего семантический слой. Во всех приложения пакета включена возможность обмена данными, благодаря чему легко обеспечивается перенос информации между каждым этапом обработки. В основном упор сделан на самообучающиеся алгоритмы, т.к. такой подход гораздо гибче классических статистический методов и ниже планка необходимых знаний, которую нужно преодолеть, чтобы начать ими пользоваться.
Источник: old.computerra.ru
Анализ бизнес информации — основные принципы
Об анализе информации в последнее время говорят так много и столько всего, что можно окончательно запутаться в проблеме. Это хорошо, что многие обращают внимание на такую актуальную тему. Плохо только то, что под этим термином каждый понимает то, что ему нужно, часто не имея общей картины по проблеме.
Фрагментарность в таком подходе является причиной непонимания того, что происходит и что делать. Все состоит из кусков, слабо связанных между собой и не имеющих общего стержня. Наверняка, вы часто слышали фразу «лоскутная автоматизация». С этой проблемой уже неоднократно сталкивались многие и могут подтвердить, что основная проблема при таком подходе состоит в том, что практически никогда невозможно увидеть картину в целом. С анализом ситуация аналогичная.
Для того чтобы было понятно место и назначение каждого механизма анализа, давайте рассмотрим все это целиком. Будет отталкиваться от того, как человек принимает решения, поскольку объяснить, как рождается мысль, мы не в состоянии, сконцентрируемся на том, как можно в этом процессе использовать информационные технологии.
Первый вариант – лицо, принимающее решение (ЛПР), использует компьютер только как средство извлечения данных, а выводы делает уже самостоятельно. Для решения такого рода задач используются системы отчетности, многомерный анализ данных, диаграммы и прочие способы визуализации. Второй вариант: программа не только извлекает данные, но и проводит различного рода предобработку, например, очистку, сглаживание и прочее. А к обработанным таким образом данным применяет математические методы анализа – кластеризацию, классификацию, регрессию и т.д. В этом случае ЛПР получает не сырые, а прошедшие серьезную обработку данные, т.е. человек уже работает с моделями, подготовленными компьютером.
Благодаря тому, что в первом случае практически все, что связано собственно с механизмами принятия решений, возлагается на человека, проблема с подбором адекватной модели и выбором методов обработки выносится за пределы механизмов анализа, т. е. базой для принятия решения является либо инструкция (например, каким образом можно реализовать механизмы реагирования на отклонения), либо интуиция. В некоторых случаях этого вполне достаточно, но если ЛПР интересуют знания, находящиеся достаточно глубоко, если так можно выразиться, то просто механизмы извлечения данных тут не помогут.
Необходима более серьезная обработка. Это и есть тот самый второй случай. Все применяемые механизмы предобработки и анализа позволяют ЛПР работать на более высоком уровне. Первый вариант подходит для решения тактических и оперативных задач, а второй – для тиражирования знаний и решения стратегических проблем.
Идеальным случаем была бы возможность применять оба подхода к анализу. Они позволяют покрыть почти все потребности организации в анализе бизнес информации. Варьируя методики в зависимости от задач, мы будем иметь возможность в любом случае выжать максимум из имеющейся информации.
Общая схема работы приведена ниже.
Часто при описании того или иного продукта, анализирующего бизнес информацию, применяют термины типа риск-менеджмент, прогнозирование, сегментация рынка… Но в действительности решения каждой из этих задач сводятся к применению одного из описанных ниже методов анализа. Например, прогнозирование – это задача регрессии, сегментация рынка – это кластеризация, управление рисками – это комбинация кластеризации и классификации, возможны и другие методы. Поэтому данный набор технологий позволяет решать большинство бизнес задач. Фактически, они являются атомарными (базовыми) элементами, из которых собирается решение той или иной задачи.
Теперь опишем отдельно каждый фрагмент схемы.
В качестве первичного источника данных должны выступать базы данных систем управления предприятием, офисные документы, Интернет, потому что необходимо использовать все сведения, которые могут пригодиться для принятия решения. Причем речь идет не только о внутренней для организации информации, но и о внешних данных (макроэкономические показатели, конкурентная среда, демографические данные и т.п.).
Хотя в хранилище данных не реализуются технологии анализа, оно является той базой, на которой нужно строить аналитическую систему. В отсутствие хранилища данных на сбор и систематизацию необходимой для анализа информации будет уходить большая часть времени, что в значительной степени сведет на нет все достоинства анализа. Ведь одним из ключевых показателей любой аналитической системы является возможность быстро получить результат.
Следующим элементом схемы является семантический слой. Вне зависимости от того, каким образом будет анализироваться информация, необходимо, чтобы она была понятна ЛПР, поскольку в большинстве случаев анализируемые данных располагаются в различных базах данных, а ЛПР не должен вникать в нюансы работы с СУБД, то требуется создать некий механизм, трансформирующий термины предметной области в вызовы механизмов доступа к БД. Эту задачу и выполняет семантический слой. Желательно, чтобы он был один для всех приложений анализа, таким образом легче применять к задаче различные подходы.
Системы отчетности предназначены для того, чтобы дать ответ на вопрос «что происходит». Первый вариант его использования: регулярные отчеты используются для контроля оперативной ситуации и анализа отклонений.
Например, система ежедневно готовит отчеты об остатках продукции на складе, и когда его значение меньше средней недельной продажи, необходимо реагировать на это подготовкой заказа на поставку, т. е. в большинстве случаев это стандартизированные бизнес операции. Чаще всего некоторые элементы этого подхода в том или ином виде реализованы в компаниях (пусть даже просто на бумаге), однако нельзя допускать, чтобы это был единственный из доступных подходов к анализу данных. Второй вариант применения систем отчетности: обработка нерегламентированных запросов. Когда ЛПР хочет проверить какую-либо мысль (гипотезу), ему необходимо получить пищу для размышлений подтверждающую либо опровергающую идею, т. к. эти мысли приходят спонтанно, и отсутствует точное представление о том, какого рода информация потребуется, необходим инструмент, позволяющий быстро и в удобном виде эту информацию получить. Извлеченные данные обычно представляются либо в виде таблиц, либо в виде графиков и диаграмм, хотя возможны и другие представления.
Хотя для построения систем отчетности можно применять различные подходы, самый распространенный на сегодня – это механизм OLAP. Основной идеей является представление информации в виде многомерных кубов, где оси представляют собой измерения (например, время, продукты, клиенты), а в ячейках помещаются показатели (например, сумма продаж, средняя цена закупки). Пользователь манипулирует измерениями и получает информацию в нужном разрезе.
Благодаря простоте понимания OLAP получил широкое распространение в качестве механизма анализа данных, но необходимо понимать, что его возможности в области более глубокого анализа, например, прогнозирования, крайне ограничены. Основной проблемой при решении, задач прогнозирования является вовсе не возможность извлечения интересующих данных в виде таблиц и диаграмм, а построение адекватной модели.
Дальше все достаточно просто. На вход имеющейся модели подается новая информация, пропускается через нее, а результат и есть прогноз. Но построение модели является совершенно нетривиальной задачей.
Конечно, можно заложить в систему несколько готовых и простых моделей, например, линейную регрессию или что-то аналогичное, довольно часто именно так и поступают, но это проблему не решает. Реальные задачи почти всегда выходят за рамки таких простых моделей.
А следовательно, такая модель будет обнаруживать только явные зависимости, ценность обнаружения которых незначительна, что и так хорошо известно и так, или будут строить слишком грубые прогнозы, что тоже совершенно неинтересно. Например, если вы будете при анализе курса акций на фондовом рынке исходить из простого предположения, что завтра акции будут стоить столько же, сколько и сегодня, то в 90% случаев вы угадаете. И насколько ценны такие знания? Интерес для брокеров представляют только оставшиеся 10%. Примитивные модели в большинстве случаев дают результат примерно того же уровня.
Правильным подходом к построению моделей является их пошаговое улучшение. Начав с первой, относительно грубой модели, необходимо по мере накопления новых данных и применения модели на практике улучшать ее. Собственно задача построения прогнозов и тому подобные вещи выходят за рамки механизмов систем отчетности, поэтому и не стоит ждать в этом направлении положительных результатов при применении OLAP. Для решения задач более глубокого анализа применяется совершенно другой набор технологий, объединенных под названием Knowledge Discovery in Databases .
Knowledge Discovery in Databases (KDD) – это процесс преобразования данных в знания. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining (DM), постобработки данных, интерпретации полученных результатов. Data Mining – это процесс обнаружения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных для интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Привлекательность этого подхода заключается в том, что вне зависимости от предметной области мы применяем одни и те же операции:
- Извлечь данные. В нашем случае для этого нужен семантический слой.
- Очистить данные. Применение для анализа «грязных» данных может полностью свести на нет применяемые в дальнейшем механизмы анализа.
- Трансформировать данные. Различные методы анализа требуют данных, подготовленных в специальном виде. Например, где-то в качестве входов может использоваться только цифровая информация.
- Провести, собственно, анализ – Data Mining.
- Интерпретировать полученные результаты.
Это процесс повторяется итеративно.
Data Mining, в свою очередь, обеспечивает решение всего 6 задач – классификация, кластеризация, регрессия, ассоциация, последовательность и анализ отклонений.
Это все, что необходимо сделать, чтобы автоматизировать процесс извлечения знаний. Дальнейшие шаги уже делает эксперт, он же ЛПР.
Интерпретация результатов компьютерной обработки возлагается на человека. Просто различные методы дают различную пищу для размышлений. В самом простом случае – это таблицы и диаграммы, а в более сложном – модели и правила.
Полностью исключить участие человека невозможно, т.к. тот или иной результат не имеет никакого значения, пока не будет применен к конкретной предметной области. Однако имеется возможность тиражировать знания. Например, ЛПР при помощи какого-либо метода определил, какие показатели влияют на кредитоспособность покупателей, и представил это в виде правила.
Правило можно внести в систему выдачи кредитов и таким образом значительно снизить кредитные риски, поставив их оценки на поток. При этом от человека, занимающегося собственно выпиской документов, не требуется глубокого понимания причин того или иного вывода. Фактически это перенос методов, когда-то примененных в промышленности, в область управления знаниями. Основная идея – переход от разовых и не унифицированных методов к конвейерным.
Все, о чем говорилось выше, только названия задач. И для решения каждой из них можно применять различные методики, начиная от классических статистических методов и кончая самообучающимися алгоритмами. Реальные бизнес задачи решаются практически всегда одним из указанных выше методов или их комбинацией. Практически все задачи – прогнозирование, сегментация рынка, оценка риском, оценка эффективности рекламных кампаний, оценка конкурентных преимуществ и множество других – сводятся к описанным выше. Поэтому, имея в распоряжении инструмент, решающий приведенный список задач, можно говорить, что вы готовы решить любую задачу бизнес анализа.
Если вы обратили внимание, мы нигде не упоминали о том, какой инструмент будет использоваться для анализа, какие технологии, т.к. сами задачи и методы их решения не зависят от инструментария. Это всего лишь описание грамотного подхода к проблеме. Можно использовать все, что угодно, важно только, чтобы был покрыт весь список задач.
В этом случае можно говорить о том, что имеется действительно полнофункциональное решение. Очень часто в качестве «полнофункционального решения задач бизнес анализа» предлагаются механизмы, покрывающие только незначительную часть задач. Чаще всего под системой анализа бизнес информации понимается только OLAP, чего совершенно недостаточно для полноценного анализа. Под толстым слоем рекламных лозунгов находится всего лишь система построения отчетов. Эффектные описания того или иного инструмента анализа скрывают суть, но достаточно отталкиваться от предложенной схемы, и вы будете понимать действительное положение вещей.
Источник: basegroup.ru
2. Схема анализа бизнес-информации
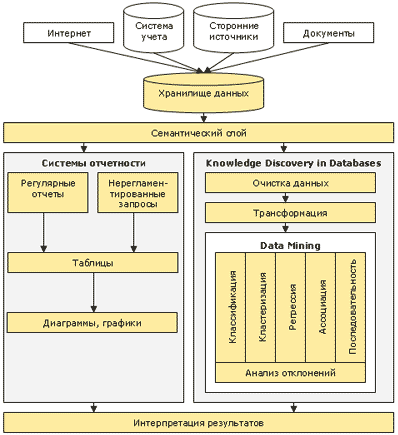
Общая схема анализа бизнес-информации приведена на рис.6.2. Рис.6.2. Общая схема анализа бизнес-информации Часто при описании того или иного продукта, анализирующего бизнес-информацию, применяют термины: риск-менеджмент, прогнозирование, сегментация рынка. Но в действительности решения каждой из этих задач сводятся к применению одного из описанных ниже методов анализа. Например, прогнозирование – это задача регрессии, сегментация рынка – это кластеризация, управление рисками – это комбинация кластеризации и классификации, возможно, и других методов. Поэтому данный набор технологий позволяет решать большинство бизнес-задач. Фактически они являются атомарными (базовыми) элементами, из которых собирается решение той или иной задачи. Опишем отдельно каждый фрагмент схемы. В качестве первичного источника данных должны выступать базы данных систем управления предприятием, офисные документы, Internet. Необходимо использовать все сведения, которые могут пригодиться для принятия решения. Причем речь идет не только о внутренней для организации информации, но и о внешних данных (макроэкономические показатели, конкурентная среда, демографические данные и т.п.). Хотя в хранилище данных не реализуются технологии анализа, оно является той базой, на которой нужно строить аналитическую систему. При отсутствии хранилища данных на сбор и систематизацию необходимой для анализа информации будет уходить большая часть времени, что в значительной степени сведет на нет все достоинства анализа. Ведь одним из ключевых показателей любой аналитической системы является возможность быстро получить результат. Следующим элементом схемы является семантический слой. Вне зависимости от того, каким образом будет анализироваться информация, необходимо, чтобы она была понятна ЛПР. Так как в большинстве случаев анализируемые данные располагаются в различных базах данных, а ЛПР не должен вникать в нюансы работы с СУБД, то требуется создать некий механизм, трансформирующий термины предметной области в вызовы механизмов доступа к БД. Эту задачу и выполняет семантический слой. Желательно, чтобы он был один для всех приложений анализа, таким образом легче применять к задаче различные подходы. Системы отчетности предназначены для того, чтобы дать ответ на вопрос: «Что происходит?». Первый вариант его использования – регулярные отчеты для контроля оперативной ситуации и анализа отклонений. Например, система ежедневно готовит отчеты об остатках продукции на складе, и когда его значение меньше средней недельной продажи, необходимо реагировать на это подготовкой заказа на поставку, т.е. в большинстве случаев – это стандартизированные бизнес-операции. Второй вариант применения систем отчетности – обработка нерегламентированных запросов. Когда ЛПР хочет проверить какую-либо мысль (гипотезу), ему необходимо получить пищу для размышлений, подтверждающую либо опровергающую идею. Так как эти мысли приходят спонтанно и отсутствует точное представление о том, какого рода информация потребуется, необходим инструмент, позволяющий быстро и в удобном виде эту информацию получить. Извлеченные данные обычно представляются либо в виде таблиц, либо в виде графиков и диаграмм, но возможны и другие представления. Хотя для построения систем отчетности можно применять различные подходы, самый распространенный на сегодня – это механизм OLAP. Основной идеей является представление информации в виде многомерных кубов, где оси представляют собой измерения (например, время, продукты, клиенты), а в ячейках помещаются показатели (например, сумма продаж, средняя цена закупки). Пользователь манипулирует измерениями и получает информацию в нужном разрезе. Благодаря простоте понимания OLAP получил широкое распространение в качестве механизма анализа данных, но необходимо учитывать, что его возможности в области более глубокого анализа, например прогнозирования, крайне ограничены. Основной проблемой при решении задач прогнозирования является вовсе не возможность извлечения интересующих данных в виде таблиц и диаграмм, а построение адекватной модели. На вход имеющейся модели подается новая информация, пропускается через нее, результат – это и есть прогноз. Но построение модели является совершенно нетривиальной задачей. Конечно, можно заложить в систему несколько готовых и простых моделей, например линейную регрессию или что-то аналогичное (довольно часто именно так и поступают), но это проблему не решает. Реальные задачи почти всегда выходят за рамки таких простых моделей. А следовательно, такая модель будет обнаруживать только явные зависимости, ценность обнаружения которых незначительна (все известно и так). Или будут строиться слишком грубые прогнозы. Например, если при анализе курса акций на фондовом рынке исходить из простого предположения, что завтра акции будут стоить столько же, сколько и сегодня, то в 90 % это угадывается. Насколько ценны такие знания? Интерес для брокеров представляют только оставшиеся 10 %. Примитивные модели в большинстве случаев дают результат примерно того же уровня. Правильным подходом к построению моделей является их пошаговое улучшение. Начав с первой, относительно грубой модели, необходимо по мере накопления новых данных и применения модели на практике улучшать ее. Собственно, задача построения прогнозов выходит за рамки механизмов систем отчетности, поэтому и не стоит ждать в этом направлении положительных результатов при применении OLAP. Для решения задач более глубокого анализа применяются совершенно другие технологии, объединенные под названием Knowledge Discovery in Databases . Knowledge Discovery in Databases (KDD) – это процесс поиска полезных знаний в «сырых» данных. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining (DM), постобработки данных, интерпретации полученных результатов. Data Mining – это процесс обнаружения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Привлекательность этого подхода заключается в том, что вне зависимости от предметной области мы применяем одни и те же операции:
- Извлечь данные. В нашем случае для этого нужен семантический слой.
- Очистить данные. Применение для анализа «грязных» данных может полностью свести на нет применяемые в дальнейшем механизмы анализа.
- Трансформировать данные. Различные методы анализа требуют данных, подготовленных в специальном виде. Например, где-то в качестве входов может использоваться только цифровая информация.
- Провести собственно анализ – Data Mining.
- Интерпретировать полученные результаты.
Этот процесс повторяется итеративно. Data Mining, в свою очередь, обеспечивает решение всего 6 задач – классификация, кластеризация, регрессия, ассоциация, последовательность и анализ отклонений. Это все, что необходимо сделать, чтобы автоматизировать процесс извлечения знаний. Дальнейшие шаги уже делает эксперт, он же ЛПР. Интерпретация результатов компьютерной обработки возлагается на человека. Разные методы дают различную пищу для размышлений. В самом простом случае – это таблицы и диаграммы, а в более сложном – модели и правила. Полностью исключить участие человека невозможно, так как тот или иной результат не имеет никакого значения, пока не будет применен к конкретной предметной области. Однако имеется возможность тиражировать знания. Например, ЛПР при помощи какого-либо метода определил, какие показатели влияют на кредитоспособность покупателей, и представил это в виде правила. Правило можно внести в систему выдачи кредитов и таким образом значительно снизить кредитные риски, поставив их оценки на поток. При этом от человека, занимающегося собственно выпиской документов, не требуется глубокого понимания причин того или иного вывода. Фактически – это перенос методов, когда-то примененных в промышленности, в область управления знаниями. Основная идея – переход от разовых и неунифицированных методов к конвейерным. Все, о чем говорилось выше, это только названия задач. И для решения каждой из них можно применять различные методики, начиная от классических статистических методов и кончая самообучающимися алгоритмами. Реальные бизнес-задачи решаются практически всегда одним из указанных выше методов или их комбинацией. Практически все задачи – прогнозирование, сегментация рынка, оценка рисков, оценка эффективности рекламных кампаний, оценка конкурентных преимуществ и множество других – сводятся к описанным выше. Поэтому, если в системе реализован инструментарий, решающий для приведенного списка задач, можно говорить о возможности решить любую задачу бизнес-анализа. Задачи бизнес-анализа и методы их решения не зависят от инструментария. Приведенная выше схема анализа дает лишь целостное представление о проблеме и путях ее решения и может быть реализована на различных программных платформах. Очень часто в качестве «полнофункционального решения задач бизнес-анализа» предлагаются механизмы, покрывающие только незначительную часть задач. Чаще всего под системой анализа бизнес-информации понимается только OLAP, чего совершенно недостаточно для полноценного анализа. Под толстым слоем рекламных лозунгов находится лишь система построения отчетов. Контрольные вопросы и задания к теме 6
- Какие виды деятельности можно выделить, какие задачи обработки информации в них решаются?
- Какое место занимает анализ в обработке информации?
- Охарактеризуйте систему отчетности схемы анализа и приведите примеры отчетов в организации или предприятии.
- Как можно использовать механизм OLAP для системы отчетности?
- Какие операции обработки данных выполняются при анализе?
- Приведите примеры применения аналитических методов в решении задач управления производством.
- Какие технологии поиска знаний могут применяться при анализе?
Источник: studfile.net