Big Data — это разнообразные данные, поступающие в больших объемах и с огромной скоростью. Информации настолько много, что стандартное программное обеспечение не может обработать такой массив. При этом большие данные полезны — их можно использовать для решения разных задач.
Разбираем на примерах, что такое Big Data и как работают с такими массивами. Наш эксперт Егор Ермилов, Big Data Scientist (ведущий аналитик данных) образовательной платформы «ИнтернетУрок», рассказывает, как собирают большие данные, где их используют и в чем отличие Big Data от Data science.
Нет времени читать статью? Найдите ее в нашем телеграм-канале и сохраните себе в «Избранном» на будущее.
Что такое Big Data?
Пользователи постоянно генерируют данные: когда совершают покупки, прокладывают маршруты на картах, оставляют поисковые запросы, выходят на пробежку в смарт-часах, публикуют посты в социальных сетях, заказывают еду онлайн и вообще совершают привычные действия. Так получаются большие данные, которые собирают и анализируют разные организации: от производителей машин до социальных служб.
Что такое Big Data
Нет четкой границы, когда данные считаются большими, а когда еще нет. Чаще всего под Big Data имеют в виду терабайты, петабайты и даже зеттабайты информации. К большим данным относится практически любая обезличенная информация о пользователях. Это могут быть:
- пол,
- возраст,
- социальный статус,
- интересы,
- примерный уровень дохода,
- наличие детей и многое другое.
Вычислить конкретного человека в таком массиве данных просто невозможно, да и не нужно. Компании интересуются общими тенденциями, а не отдельными людьми.
Например, Toyota использует большие данные, чтобы предотвратить ситуации, когда водитель случайно нажимает на педаль газа вместо тормоза. Машина анализирует препятствия вокруг и игнорирует нажатие, если определила его как случайное.
Как появились Big Data?
По прогнозам аналитической компании Statista, в 2025 году человечество сгенерирует до 181 зеттабайт данных (1 Збайт = секстиллион байт). Для сравнения в 2020 году было сгенерировано 64,2 Збайта данных.
Гиперрост связан с эволюцией вычислений. Исследовательская компания IDC классифицирует создание и использование данных по трем эпохам:
Данные хранились только в специальных центрах обработки. У машин была малая вычислительная мощность, а использовали данные только для нужд бизнеса
Центры обработки стали не только хранить данные, но и распределять их по сети к конечным устройствам, например компьютерам. Пользователи получили возможность сохранять информацию и управлять ей — так появилась индустрия цифровых развлечений, включающая музыку, фильмы и игры
2000 — настоящее время
Из конкретных физических устройств данные переместились в облачные хранилища — это стало возможным благодаря распространению широкополосной связи и быстрых
сетей. Теперь доступ к данным имеет любой человек с любого устройства
Что такое Big Data за 6 минут
Где используют Big Data?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Большие данные можно использовать везде, но на практике их применяют там, где одновременно есть:
- большой объем данных,
- значимая польза от использования данных,
- средства на поддержание инфраструктуры и специалистов по Big Data.
Чаще всего полноценную Big Data инфраструктуру можно встретить:
- в финансовых организациях — банки и платёжные системы;
- телекоммуникациях — компании мобильной связи;
- транспорте и логистике — авиакомпании и железные дороги.
Иногда Big Data встречается и в науке, например в большой адронном коллайдере.
Примеры использования Big Data
Amazon
Amazon хранит большие данные о клиентах, чтобы адаптировать рекомендации под запросы покупателей. Если добавить что-то в корзину, платформа порекомендует товары, которые часто берут вместе с этим продуктом. Компания генерирует 35% годовых продаж, используя этот метод.
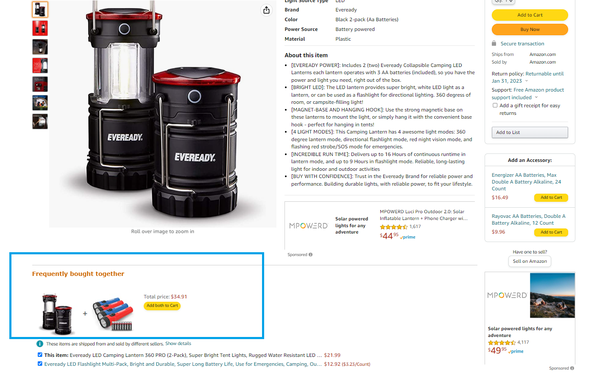
Amazon предлагает товары, которые чаще всего покупают с рассматриваемым товаром. Изображение: Amazon
Apple
Анализируя большие данные, Apple может узнать, как люди используют приложения в реальной жизни, Это позволяет изменять дизайн и начинку программ в соответствии с предпочтениями клиентов.
Еще один пример использования больших данных — это часы Apple Watch. Их носят постоянно, и компания собирает данные о действиях клиентов в течение дня. Эта информация может быть использована для лечения и профилактики болезней, а также для создания мобильных приложений, связанных со здоровьем.

Apple собирает данные о действиях клиентов в течение дня через Apple Watch. Изображение: Tim Foster для Unsplash
Visa
Visa использует большие данные, чтобы выявить мошеннические транзакции. При каждой покупке компания сохраняет такие данные, как местонахождение продавца, сумма транзакции, время суток и сотни других атрибутов. Эти данные сравниваются с прошлым поведением покупателя, и программное обеспечение Visa отправляет в банк оценку о законности покупки. Затем банк может использовать информацию, чтобы быстро принять или отклонить транзакцию.
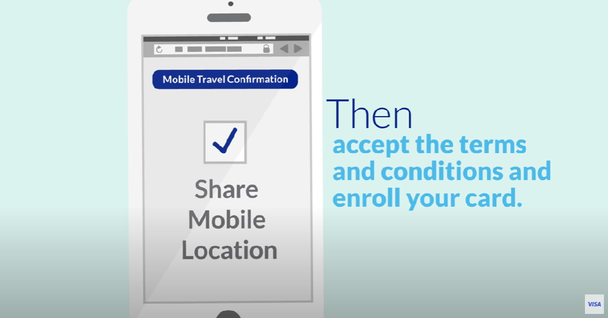
Visa предлагает пользователям функцию отслеживания местоположения через приложение в телефоне, что особенно актуально при путешествиях. Изображение: Youtube
Аэропорт Дубая
В аэропорту Дубая установлено около 1000 датчиков, используемых для определения пассажиропотока и длины очереди. Полученная информация позволяет персоналу аэропорта решать, как расставить приоритеты в обслуживании. Например, какой самолет должен пристыковываться ближе всего к прибытию и сколько сотрудников требуется на иммиграционных стойках.

Big Data в аэропорту — это пассажиропоток, длина очередей, информация о рейсах, количестве самолетов и сотрудников аэропорта. Изображение: Chris Leipelt для Unsplash
ATT блокирует нежелательные звонки от роботов. Системы ежедневно фильтруют миллиарды записей в поисках шаблонов и подозрительных признаков. Затем обнаруженные аномалии проверяют, чтобы избежать приостановки законных вызовов. Так компании удалось заблокировать 6 500 000 000 звонков от роботов.Как собирают и хранят Big Data?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Можно выделить три эволюционных этапа развития инструментов обработки данных:
- Данных немного. Для их обработки применяются простые инструменты на компьютере аналитиков, например Excel, Python, R. Хранятся данные в виде текстовых и Excel файлов и передаются по электронной почте.
- Данных уже больше. Они обрабатываются на отдельном сервере с бо́льшим количеством оперативной памяти и более мощным процессором. Хранятся в специализированных базах данных, куда имеют доступ разные пользователи.
- Big Data. Уже не хватает мощностей одного большого сервера. Для обработки и хранения требуется параллельные вычисления и кластер из многих серверов.
Область применения во всех трёх случаях может быть одинаковой: от аналитических отчетов до моделей машинного обучения.
В чем отличие Big Data и Data Science?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Data Science — наука о данных. Она нужна, чтобы учиться извлекать из данных пользу для бизнеса.
Big Data — это такое состояние, когда накоплен большой объём данных и с ним нужно как-то работать. А традиционные инструменты уже не справляются.
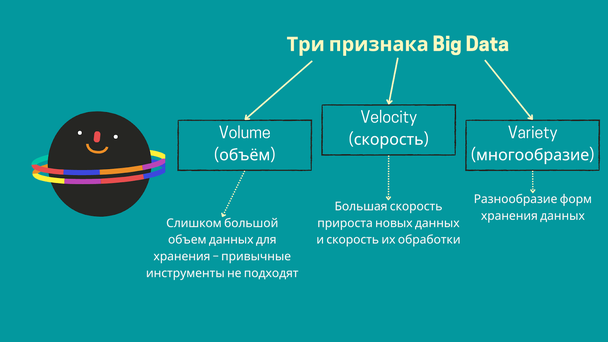
Нет однозначного представления о том, где лежит граница между «еще не big data» и «уже big data». Но традиционно выделяют три V или три основных признака больших данных:
- Volume (объем). Привычные инструменты не могут хранить большой объём данных. Речь идет уже о терабайтах данных, которые не вмещаются в традиционные базы и тем более в Excel-файлы.
- Velocity (скорость). Имеется в виду как скорость прироста новых данных, так и необходимая скорость обработки. Раньше хватало работы аналитика и ручной обработки Excel в течение пары дней. Теперь бизнесу нужно видеть отчёты, формирующиеся в режиме реального времени.
- Variety (многообразие). Это значит разнообразие форм хранения данных. Нужно уметь хранить и анализировать не только табличные данные, но и, например, фото-, видео- и аудио- данные.
У Big Data такая же область применения, как и у Data Science, но другой набор инструментов. Если нужно проанализировать, как вели себя пользователи прошлый месяц — это в раздел аналитики больших данных. Если нужно на основе накопленных данных предсказать, как поведут себя пользователи в следующем месяце — это в раздел машинного обучения. Всё это позволяет делать выводы из накопленных данных, предсказывать состояние дел на будущее и принимать решения.
Какие технологии Big Data есть?
Технологии больших данных — это программы, которые предназначены для анализа, обработки и извлечения информации из больших наборов данных со сложной структурой. Они нужны, когда традиционных технологий недостаточно.
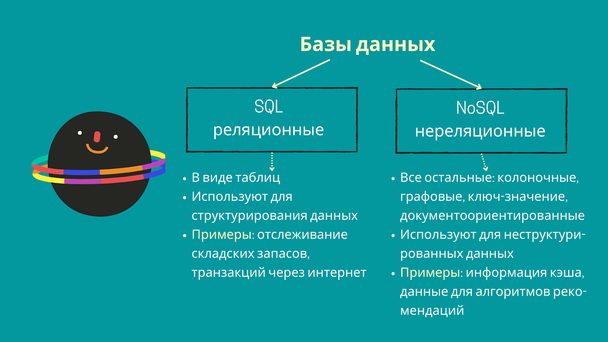
SQL и NoSQL
Базы данных бывают двух типов:
- Реляционные, где информация представлена в виде таблиц. Для работы с ними используют язык запросов SQL.
- Нереляционные — все остальные базы, в которых информация представлена по-другому, например в виде графов или коллекции документов. Для работы с ними используют язык запросов NoSQL.
NoSQL более гибкие и позволяют решать больше задач, например, они подходят, чтобы хранить данные кэша или информацию для алгоритмов рекомендаций. Нереляционные базы используют, когда нужны масштабы и быстрота обработки, — как в случае с большими данными.
MapReduce
Это модель данных и алгоритм, которые нужны для больших вычислений, где нужно задействовать несколько компьютеров параллельно. MapReduce может обрабатывать десятки петабайт данных в день (1 Петабайт = 1 024 Терабайт). Сначала информация фильтруется по условиям запроса, а затем распределяется между компьютерами, каждый из которых рассчитывает свои блоки данных и передает результаты.
MapReduce используют для создания поискового индекса, выявления спама в почте, оптимизации рекламы. Самая популярная программа, работающая по алгоритму MapReduce, — это Hadoop.
Скриншот с сайта Hadoop
R
Это язык программирования, предназначенный для обработки данных — на нем даже строят машинное обучение и нейросети. R помогает анализировать данные из разных источников и полезен при работе со статистикой.
Как Big Data помогает бизнесу?
Отвечает Егор Ермилов, Big Data Scientist образовательной платформы «ИнтернетУрок»
Data Science, как и Big Data, позволяет компаниям выработать так называемый подход, основанный на данных (data-driven approach). Это такой подход к управлению, при котором решения принимаются, опираясь на анализ данных и математику. А интуиция и личный опыт отходят на второй план.
Раньше, например, выбирая между вариантами А и Б, решение принимали на основе прошлого опыта менеджеров, их здравого смысла и интуиции. Анализ больших данных сейчас может цифрами показать разницу между А и Б — это позволяет принять более объективное решение.
Наука о данных также может учесть уже накопленный опыт принятия решений: как со стороны руководства компаний, так и со стороны клиентов. Обученная математическая модель позволяет принимать рутинные решения без участия человека, при этом гораздо быстрее и точнее.
Пример таких решений:
- Когда лучше устроить распродажу?
- Какую установить скидку на разные категории товаров?
- Какой товар предложить купить?
- Какие клиенты больше склонны купить товар или услугу?
Кто такой Big Data аналитик?
Big Data аналитик — это специалист по анализу больших данных, который собирает их в базы, изучает и делает выводы. Этот человек должен извлечь информацию, которая поможет компании принять стратегически верные решения. Big Data аналитики нужны компаниям, куда поступают большие объемы данных: в IT-секторе, у мобильных операторов, в банках и государственных организациях.
Обучение на Big Data аналитика
В России пока нет отдельного бакалавриата по специальности Big Data аналитик, но для старта в профессии подойдут направления подготовки, связанные с IT, математикой и компьютерными науками. Например, прикладная информатика или программная инженерия. В Высшей школе экономики есть англоязычная магистерская программа «Бизнес-аналитика и системы больших данных» — она подойдет тем, кто хочет углубить свои знания после бакалавриата.
Другой вариант обучения — курсы. Чтобы получить представление о работе с Big Data, можно воспользоваться бесплатными программами:
- курс университета МИСиС «Введение в инженерию больших данных»;
- курс Санкт-Петербургского Политехнического университета «Наука о данных и аналитика больших объемов данных»;
- курс университета ИТМО «Обработка и анализ больших данных».
Анализу больших данных обучают также онлайн-школы вроде GeekBrains, Нетологии и Яндекс.Практикума.
Сколько зарабатывает Big Data аналитик?
Зарплата аналитика больших данных в России зависит от уровня компетенций:
60 000–100 000 руб.
Middle (опытный специалист)
100 000–330 000 руб.
Senior (профессионал, способный решить любую задачу)
150 000–400 000 руб.
В США, по данным сайта по поиску вакансий Indeed, зарплата начинающего Big Data аналитика в среднем составляет $4 800 в месяц, а аналитик с опытом работы от 3 лет получает $5 369. Вот компании США, которые платят Big Data аналитикам больше остальных:
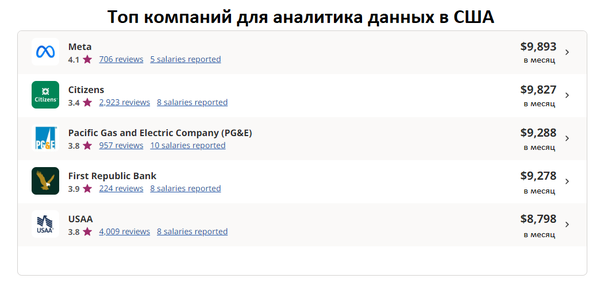
Скриншот с сайта Indeed
Чем Big Data аналитик отличается от бизнес-аналитика?
Big Data аналитик и бизнес-аналитик интерпретируют данные и делают выводы на их основе. Но это разные профессии с такими ключевыми отличиями:
Big Data аналитик
Бизнес-аналитик
Анализирует широкий спектр данных, поступающих из разных источников
Фокусируется на финансовой и операционной аналитике бизнеса
Работает со структурированными и неструктурированными данными
В основном анализирует структурированные данные
Из-за большого количества данных на каждом этапе работы использует технологии, основную аналитическую работу выполняют машины
Самостоятельно просматривает данные и делает из них выводы
Обладает инженерными навыками в области хранилищ данных
Основной навык — знание бизнеса, предметной области и статистики
Что такое Big Data анализ: техники и методы
Анализ Big Data — это сбор, хранение и анализ большого количества информации, которая поступает из разных источников. Вот какие техники и методы в этом помогают.
Data mining
Поиск важных данных среди огромного массива накопившейся информации — по сути, это превращение необработанных данных во что-то полезное. Эту технологию используют, чтобы найти неизвестные ранее закономерности между данными. Например, маркетплейсам Data mining помогает выявить взаимосвязи между покупками и подстроить рекомендации под пользователя.
Машинное обучение
Это искусственный интеллект, который обучается на массивах данных и принимает решения, анализируя схожие задачи. Впоследствии он выявляет закономерности, учится на прошлом опыте и генерируют новые решения.
Нейронные сети
Один из видов машинного обучения — искусственный интеллект, который имитирует, как нейроны человеческого мозга передают сигналы. Нейросетям дают огромный массив правильно решенных задач, и те на их основе принимают решения. Другой алгоритм говорит, правильно ли принято решение, — со временем результаты становятся все более точными. На нейросетях работают голосовые помощники и чат-боты.
Краудсорсинг
С английского краудсорсинг дословно переводится как «использование ресурсов толпы». Это явление, когда для решения проблемы привлекают внешних исполнителей, добровольцев. Например, Microsoft предлагает тысячам пользователей отправлять отчеты об ошибках в компанию — эта стратегия позволяет быстро выявить баги и исправить их в обновлении.
Имитационное моделирование
Имитационное моделирование — это построение точных компьютерных моделей на основе Big Data, которые затем испытывают и делают прогнозы. На основе имитационного моделирования можно изучить поведение покупателей в зависимости от меняющихся обстоятельств.
Интересная статистика о Big Data
- В 2020 году человечество сгенерировало 64,2 Збайта данных. К 2021 году из них сохранилось только 2%.
- По состоянию на 2022 год, 90% мировых данных было создано за предыдущие два года.
- В 2022 году больше всего центров обработки данных находится в США — 2 701 центр. В России их только 172.
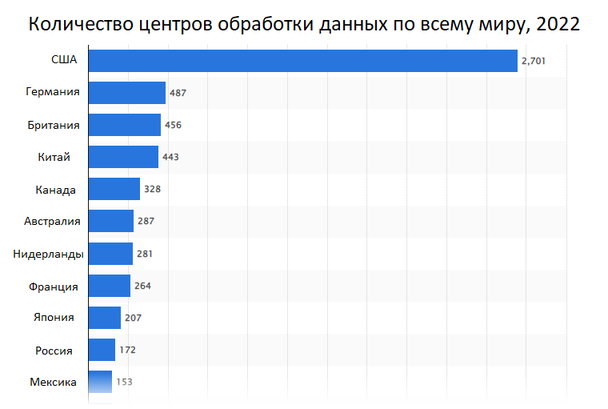
Составлено по материалам Statista
- 92,1% самых крупных компаний США получают отдачу от инвестиций в работу с данными и искусственным интеллектом.
- К 2024 году соотношение между уникальными и скопированными данными составит 1:10. Это значит, что на каждый уникальный файл будет приходиться 10 неуникальных.
Источник: lpgenerator.ru
Big Data: что такое большие данные и где они применяются
В статье расскажем о характеристиках и классификации больших данных, методах обработки и хранения, областях применения и возможностях работы с Big Data, которые дает Selectel.

Big Data простыми словами — структурированные, частично структурированные или неструктурированные большие массивы данных. В статье мы расскажем о характеристиках и классификации больших данных, методах обработки и хранения, областях применения и возможностях работы с Big Data, которые дает Selectel.
Характеристики больших данных
Несмотря на актуальность для многих сфер, границы термина размыты и могут отличаться в зависимости от конкретной задачи. Тем не менее существуют три основных признака, определенные еще в 2001 году Meta Group. Они получили аббревиатуру VVV:
Volume. Объем данных чаще всего измеряется терабайтами, петабайтами и даже эксабайтами. Нет точного понимания, с какого объема данные становятся «большими». Существуют задачи, когда информация занимает меньше терабайта, но из-за неоднородной структуры их обработка требует мощности кластера из пяти серверов.
Velocity. Скорость прироста и обработки данных. Яркий пример — новые данные для анализа появляются с каждым сеансом пользователя «ВКонтакте». Подобные потоки информации требуют высокоскоростной обработки. Если для обработки данных достаточно одной машины, это не Big Data.
Число серверов в кластере всегда превышает единицу.
Variety. Разнообразие данных. Даже если информации очень много, но она имеет четкую и ясную структуру — это не Big Data. Возвращаясь к примеру с «ВКонтакте», биографии пользователей соцсети структурированные и легко поддаются анализу. А вот данные о реакциях на посты или времени, проведенном в приложении, не имеют точной структуры.
И еще два V
В дальнейшем появилась интерпретация c «пятью V»:
Viability. Жизнеспособность данных. При большом разнообразии данных и переменных, необходимо проверять их значимость при построении модели прогнозирования. Например, факторы предсказывающие склонность потребителя к покупке: упоминания товара в соцсетях, геолокация, доступность товара, время суток, портрет покупателя.
Value. Ценность данных. После подтверждения жизнеспособности специалисты Big Data изучают взаимосвязи данных. Например, поставщик услуг может попытаться сократить отток клиентов, анализируя продолжительность звонков в колл-центр. После оценки дополнительных переменных прогнозная модель становится сложнее и эффективнее. Пример итогового вывода — повышенную склонность к оттоку в течение 45 дней после своего дня рождения демонстрируют клиенты попадающие в категории:
- геопозиция — юго-запад России с теплой погодой,
- образование — степень бакалавра,
- имущество — владельцы автомобилей 2012 года выпуска или более ранних моделей,
- кредитная история без просрочек.
Классификация данных
Структурированные данные. Как правило, хранятся в реляционных базах данных. Упорядочивают данные на уровне таблиц — например, Excel. От информации, которую можно анализировать в самом Excel, Big Data отличается большим объемом.
Частично структурированные. Данные не подходят для таблиц, но могут быть иерархически систематизированы. Под такую характеристику подходят текстовые документы или файлы с записями о событиях.
Неструктурированные. Не обладают организованной структурой: аудио- и видеоматериалы, фото и другие изображения.
Источники данных
- Генерируемые людьми социальные данные, главные источники которых — соцсети, веб, GPS-данные о перемещениях. Также специалисты Big Data используют статистические показатели городов и стран: рождаемость, смертность, уровень жизни и любую другую информацию, отражающую показатели жизни людей.
- Транзакционная информация появляется при любых денежных операциях и взаимодействии с банкоматами: переводы, покупки, поставки.
- Источником машинных данных служат смартфоны, IoT-гаджеты, автомобили и другая техника, датчики, системы слежения и спутники.
Как данные забирают из источника
Начальная стадия — Data Cleaning — выявление, очистка и исправление ошибок, нерелевантной информации и несоответствий данных. Процесс позволяет оценить косвенные показатели, погрешности, пропущенные значения и отклонения. Как правило, во время извлечения данные преобразуются. Специалисты Big Data добавляют дополнительные метаданные, временные метки или геолокационные данные.
Существует два подхода к извлечению структурированных данных:
- Полное извлечение, при котором нет потребности отслеживать изменения. Процесс проще, но нагрузка на систему выше.
- Инкрементное извлечение. Изменения в исходных данных отслеживают с момента последнего успешного извлечения. Для этого создают таблицы изменений или проверяют временные метки. Многие хранилища имеют встроенную функцию захвата данных об изменениях (CDC), которая позволяет сохранить состояния данных. Логика для инкрементального извлечения более сложная, но нагрузка на систему снижается.
При работе с неструктурированными данными большая часть времени уйдет на подготовку к извлечению. Данные очищают от лишних пробелов и символов, удаляют дубликаты результатов и определяют способ обработки недостающих значений.
Подходы к хранению Big Data
Для хранения обычно организуют хранилища данных (Data Warehouse) или озера (Data Lake). Data Warehouse использует принцип ETL (Extract, Transform, Load) — сначала идет извлечение, далее преобразование, потом загрузка. Data Lake отличается методом ELT (Extract, Load, Transform) — сначала загрузка, следом преобразование данных.
Существуют три главных принципа хранения Big Data:
Горизонтальное масштабирование. Система должна иметь возможность расширяться. Если объем данных вырос — необходимо увеличить мощность кластера путем добавления серверов.
Отказоустойчивость. Для обработки требуются большие вычислительные мощности, что повышает вероятность сбоев. Большие данные должны обрабатываться непрерывно в режиме реального времени.
Локальность. В кластерах применяется принцип локальности данных — обработка и хранение происходит на одной машине. Такой подход минимизирует расходы мощностей на передачу информации между серверами.
Анализ больших данных: от web mining до визуализации аналитики
Интеллектуальный анализ данных представляет из себя совокупность подходов к классификации, моделированию и прогнозированию.
Анализ может включать в себя добычу различных видов информации, будь то текст, изображения, аудио- и видеоданные. Отдельно выделяют web mining и social media mining, работающие с интернетом и соцсетями. Для работы с реляционными базами данных используется язык программирования SQL, подходящий для создания, изменения и извлечения хранимых данных.
Нейронные сети. Обученная нейросеть может обрабатывать огромные объемы данных с большой скоростью и точностью. Чтобы использовать нейросеть в анализе, ее необходимо обучить.
Машинное обучение — наука о том, как обучить ИИ самостоятельной работе и расширению своих знаний и возможностей. Сфера ML изучает, как создавать системы, которые автономно улучшаются с приобретением опыта. Алгоритмы машинного обучения обобщают уже имеющиеся примеры для выполнения более сложных задач. С помощью этой технологии искусственный интеллект проводит анализ, строит прогнозы, воспроизводит и улучшает модели.
После анализа данные представляют в виде аналитического отчета с предложениями о возможных решениях. Методы перевода больших данных в читаемую форму называются Business intelligence. Главный инструмент BI — дашборды, интерпретация и визуализация аналитики в виде изображений и диаграмм. Дашборды помогают фокусировать внимание на KPI, создавать бизнес-модели и отслеживать результаты принятых решений.
Эта обратная связь и дает возможности для роста бизнеса, которые можно получить с помощью Big Data. Неочевидные раньше закономерности способствуют улучшению бизнес-процессов и росту прибыли.
Работайте с Big Data на инфраструктуре Selectel
От серверов с мощными GPU до полноценной платформы обработки данных.
Инструменты для обработки больших данных
Один из способов распределенных вычислений — разработанный Google метод параллельной обработки MapReduce. Фреймворк организовывает данные в виде записей. Функции работают независимо и параллельно, что обеспечивает соблюдение принципа горизонтальной масштабируемости. Обработка происходит в три стадии:
- Map. Функцию определяет пользователь, map служит начальной обработке и фильтрации. Функция применима к одной входной записи, она выдает множество пар ключ-значение. Применяется на том же сервере, на котором хранятся данные, что соответствует принципу локальности.
- Shuffle. Вывод map разбирается по «корзинам». Каждая соответствует одному ключу вывода первой стадии, происходит параллельная сортировка. «Корзины» служат входом для третьей стадии.
- Reduce. Каждая «корзина» со значениями попадает на вход функции reduce. Ее задает пользователь и вычисляет финальный результат для каждой «корзины». Множество всех значений функции reduce становится финальным результатом.
Для разработки и выполнения программ, работающих на кластерах любых размеров, используется набор утилит, библиотек и фреймворк Hadoop. ПО Apache Software Foundation работает с открытым исходным кодом и служит для хранения, планирования и совместной работы с данными. Об истории и структуре проекта Hadoop можно почитать в отдельном материале.
Apache Spark — open-source фреймворк, входящий в экосистему Hadoop, используется для кластерных вычислений. Набор библиотек Apache Spark выполняет вычисления в оперативной памяти, что заметно ускоряет решение многих задач и подходит для машинного обучения.
NoSQL — тип нереляционных СУБД. Хранение и поиск данных моделируется отличными от табличных отношений средствами. Для хранения информации не требуется заранее заданная схема данных. Главное преимущество подобного подхода — любые данные можно быстро помещать и извлекать из хранилища. Термин расшифровывается как «Not Only SQL».
Примеры подобных СУБД
Все базы данных относятся к «семейству» Amazon:
- DynamoDB — управляемая бессерверная БД на основе пар «ключ-значение», созданная для запуска высокопроизводительных приложений в любом масштабе, подходит для IoT, игровых и рекламных приложений.
- DocumentDB — документная БД, создана для работы в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем.
- Neptune — управляемый сервис графовых баз данных. Упрощает разработку приложений, работающих с наборами сложносвязанных данных. Подходит для работы с рекомендательными сервисами, соцсетями, системами выявления мошенничества.
Самые популярные языки программирования для работы с Big Data
- R. Язык используется для обработки данных, сбора статистики и работы с графикой. Загружаемые модули связывают R с GUI-фреймворками и позволяют разрабатывать утилиты анализа с графическим интерфейсом. Графика может быть экспортирована в популярные форматы и использована для презентаций. Статистика отображается в виде графиков и диаграмм.
- Scala. Нативный язык для Apache Spark, используется для анализа данных. Проекты Apache Software Foundation, Spark и Kafka, написаны в основном на Scala.
- Python. Обладает готовыми библиотеками для работы с AI, ML и другими методами статистических вычислений: TensorFlow, PyTorch, SKlearn, Matplotlib, Scipy, Pandas. Для обработки и хранения данных существуют API в большинстве фреймворков: Apache Kafka, Spark, Hadoop.
Про то, как устроен и работает брокер сообщений Apache Kafka мы писали в отдельной статье.
Примеры использования аналитики на основе Big Data: бизнес, IT, медиа
Большие данные используют для разработки IT-продуктов. Например, в Netflix прогнозируют потребительский спрос с помощью предиктивных моделей для новых функций онлайн-кинотеатра. Специалисты стриминговой платформы классифицируют ключевые атрибуты популярности фильмов и сериалов, анализируют коммерческий успех продуктов и фич. На этом построена ключевая особенность подобных сервисов — рекомендательные системы, предсказывающие интересы пользователей.
В геймдеве используют большие данные для вычисления предпочтений игроков и анализа поведения в видеоиграх. Подобные исследования помогают совершенствовать игровой опыт и схемы монетизации.
Для любого крупного производства Big Data позволяет анализировать доходы и обратную связь от заказчиков, детализировать сведения о цепочках производства и логистике. Подобные факторы улучшают прогноз спроса, сокращают расходы и простои.
Big Data помогает со слабоструктурированными данными о запчастях и оборудовании. Записи в журналах и сведения с датчиков могут быть индикаторами скорой поломки. Если ее вовремя предсказать, это повысит функциональность, срок работы и эффективность обслуживания техники.
В сфере торговли анализ больших данных дает глубокие знания о моделях поведения клиентов. Аналитика информации из соцсетей и веб-сайтов улучшает качество сервиса, повышает лояльность и решает проблему оттока покупателей.
В медицине Big Data поможет с анализом статистики использования лекарств, эффективности предоставляемых услуг, с организацией работы с пациентами.
В банках используют распределенные вычисления для работы с транзакционной информацией, что полезно для выявления мошенничества и улучшения работы сервисов.
Госструктуры анализируют большие данные для повышения безопасности граждан и совершенствования городской инфраструктуры, улучшения работы сфер ЖКХ и общественного транспорта.
Это лишь часть сфер, где растет востребованность аналитики больших данных. В интересантах не только технические направления, но и медиа, маркетинг, социология, сфера найма, недвижимость.
Управление большими данными — кто занимается
Люди, работающие с большими данными, разделяются по многим специальностям:
- аналитик Big Data,
- дата-инженер,
- Data Scientist,
- ML-специалист и др.
Учитывая высокий спрос, для работы в сфере требуются специалисты разных компетенций. Например, существует направление data storytelling — умение эффективно донести до аудитории информацию из набора данных с помощью повествования и визуализации. Для понимания контекста используются сюжетные линии и персонажи, графики и диаграммы, изображения и видео.
Рассказы о данных используют внутри компании, чтобы на основе представленной информации донести до сотрудников необходимость улучшения продукта. Другое применение — презентация потенциальным клиентам аргументов в пользу покупки продукта.
Источник: selectel.ru
Что такое большие данные и для чего они нужны
Большие данные – направление, о котором все говорят, но мало кто хорошо в нём разбирается. Гиганты электронной коммерции, промышленные компании и информационные корпорации инвестируют в эту технологию миллиарды. Что же такое Big Data, какие перспективы они предлагают и где используются?
Что такое большие данные

Большие данные – современное технологическое направление, связанное с обработкой крупных массивов данных, которые постоянно растут. Big Data – это сама информация, методы её обработки и аналитики. Перспективы, которые может принести Big Data интересны бизнесу, маркетингу, науке и государству.
В первую очередь большие данные – это всё-таки информация. Настолько большая, что ей сложно оперировать с помощью обычных программных средств. Она бывает структурированной (обработанной), и неструктурированной (разрозненной). Вот некоторые её примеры:
• Данные с сейсмологических станций по всей Земле.
• База пользовательских аккаунтов Facebook.
• Геолокационная информация всех фотографий, выложенных за сегодня в Instagram.
• Базы данных операторов мобильной связи.
Для Big Data разрабатываются свои алгоритмы, программные инструменты и даже машины. Чтобы придумать средство обработки, постоянно растущей информации, необходимо создавать новые, инновационные решения. Именно поэтому большие данные стали отдельным направлением в технологической сфере.
VVV — признаки больших данных

Чтобы уменьшить размытость определений в сфере Big Data, разработаны признаки, которым они должны соответствовать. Все начинаются с буквы V, поэтому система носит название VVV:
• Volume – объём. Объём информации измерим.
• Velocity – скорость. Объём информации не статичен – он постоянно увеличивается, и инструменты обработки должны это учитывать.
• Variety – многообразие. Информация не обязана иметь один формат. Она может быть неструктурированной, частично или полностью структурированной.
К этим трём принципам, с развитием отрасли, добавляются дополнительные V. Например, veracity – достоверность, value – ценность или viability – жизнеспособность.
Но для понимания достаточно первых трёх: большие данные измеримые, прирастающие и неоднообразные.
Для чего необходимы большие данные

Главная цель работы с большими данными – обуздать их (проанализировать) и направить. Человечество научилось производить и извлекать огромные массивы информации, а с их управлением ещё есть проблемы.
Прямо сейчас большие данные помогают в решении таких задач:
• повышение производительности труда;
• точная реклама и оптимизация продаж;
• прогнозирование ситуаций на внутренних и глобальных рынках;
• совершенствование товаров и услуг;
• улучшение логистики;
• качественное таргетирование клиентов в любой сфере бизнеса.
Большие данные делают услуги удобнее и выгоднее как для продавцов, так и для покупателей. Предприятия могут узнать, какая продукция популярнее, как сформировать ценовую политику, когда лучшее время для продаж, как оптимизировать ресурсы на производстве, чтобы сделать его эффективнее. За счёт этого клиенты получают точное предложение «без воды».

Где используются больше данные

• Облачные хранилища. Хранить всё на локальных компьютерах, дисках и серверах неудобно и затратно. Крупные облачные data-центры становятся надёжным способом хранения информации, доступной в любой момент.
• Блокчейн. Революционная технология, сотрясающая мир в последние годы, упрощает транзакции, делает их безопаснее, а, главное, хорошо справляется с обработкой операций между гигантским количеством контрагентов за счёт своего математического алгоритма.
• Самообслуживание. Роботизация и промышленная автоматизация снижают расходы на ведение бизнеса и уменьшают стоимость товаров или услуг.
• Искусственный интеллект и глубокое обучение. Подражание мышлению головного мозга помогает делать отзывчивые системы, эффективные в науке и бизнесе.
Эти сферы создаются и прогрессируют благодаря сбору и анализу данных. Пионерами в области таких разработок являются: поисковые системы, мобильные операторы, гиганты онлайн-коммерции, банки.
Big Data будет неотъемлемой частью Индустрии 4.0 и интернета вещей, когда сложные системы из огромного числа устройств работают, как единое целое. Вот простые, уже не футуристические, примеры этого:
• Автоматизированный завод сам изменяет линейку продукции, ориентируясь на анализ спроса, поставок, себестоимости и рыночной ситуации.
• Умный дом даёт рекомендации о том, как одеться по погоде и по какому маршруту быстрее всего добраться до работы утром.
• Компания анализирует производство и каналы сбыта с учётом изменений реальной обстановки на рынке.
• Дорожная безопасность повышается за счёт сбора данных о стиле вождения и нарушениях отдельных водителей, а также состояния их машин.
Кто использует большие данные

Наибольший прогресс отрасли наблюдается в США и Европе. Вот крупнейшие иностранные компании и ведомства, которые используют Big Data:
• HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает, что в 10 раз улучшила распознавание мошеннических операций и в 3 раза – защиту от мошенничества в целом.
• Суперкомпьютер Watson, разработанный IBM, анализирует финансовые транзакции в режиме реального времени. Это позволяет сократить частоту ложных срабатываний системы безопасности на 50% и выявить на 15% больше мошеннических действий.
• Procterhttps://invlab.ru/texnologii/bolshie-dannye/» target=»_blank»]invlab.ru[/mask_link]