Доступность (Availability) — способность конфигурационной единицы или услуги выполнять согласованную функцию, когда это требуется. Доступность определяется через надежность , сопровождаемость, обслуживаемость, производительность и безопасность .
Управление доступностью(Availability Management) — процесс, отвечающий за определение , анализ , планирование, измерение и улучшение всех аспектов доступности услуги. Управление доступностью отвечает за то, чтобы вся инфраструктура , процессы, средства, роли и т.д. соответствовали согласованным Целевым показателям уровня услуги в части Доступности[1].
Главной целью Управления доступностью является гарантия того, что уровень доступности услуг эффективен по затратам и соответствует текущим или будущим потребностям бизнеса. Промежуточными целями процесса являются:
- формирование Плана управления доступностью. План управления доступностью(Availability Plan) — план, обеспечивающий эффективное по затратам выполнение текущих и будущих требований доступности к услуге[1];
- предоставление рекомендации и руководства для других областей бизнеса и IT по всем вопросам, связанным с доступностью;
- обеспечение того, чтобы услуги достигали установленных целевых показателей в контексте доступности, путем управления услугами и ресурсами;
- содействие в диагностировании и разрешении проблем, связанных с доступностью;
- оценка влияния изменений на План управления доступностью;
- обеспечение того, что проактивные средства для улучшения доступности внедрены там, где это экономически оправдано.
Процесс Управления доступностью должен включать в себя следующие деятельности:
Функция Service Desk [ПРО ITSM]
- мониторинг всех аспектов, связанных с доступностью и надежностью услуг и поддерживающих компонентов;
- управление набором методов, техник и вычислений, необходимых для ведения отчетности и проведения замеров;
- содействие в оценке рисков и управленческой деятельности;
- сбор результатов измерений и анализа, формирование регулярных и специальных (для единичных случаев) отчетов о доступности услуг и их компонентов;
- понимание текущих и будущих потребностей бизнеса в доступности услуг и их компонентов;
- влияние на проектирование услуг с целью их максимального соответствия потребностям бизнеса;
- формирование Плана управления доступностью, который позволит поставщику услуг поддерживать и улучшать уровень доступности предоставляемых услуг в соответствии с целевыми показателями, оговоренными в SLA. Он также поможет в планировании и прогнозировании уровней доступности, которые могут потребоваться в будущем.
- управление расписанием тестов всех компонентов на предмет доступности;
- содействие в идентификации и разрешении всех проблем и вопросов, связанных с недоступностью услуг и их компонентов.
- проактивное улучшение доступности услуг там, где это экономически эффективно и соответствует потребностям бизнеса[10].
Удовлетворенность заказчиков во многом зависит от доступности услуг, поэтому процесс Управления доступностью принимает особое значение . Так же, как Управление мощностями, Управление доступностью должно присутствовать на всех этапах жизненного цикла услуги.
Поговорим об ITIL и ITSM. Часть 1
Управление доступностью включает в себя проактивные и реактивные действия (рис. 5.6).
Рис. 5.6. Процесс Управления доступностью
Реактивные действия заключаются в мониторинге, измерении, анализе, формировании отчетов и обзоров обо всех аспектах, связанных с доступностью. Они гарантируют то, что целевые показатели доступности достигнуты и измерены.
Проактивные действия заключаются в формировании рекомендаций, планов, документов для проектирования и критериев для новых или измененных услуг. Сюда также входят действия по постоянному улучшению услуг и уменьшению рисков там, где это экономически оправдано.
Управление доступностью состоит из двух взаимосвязанных уровней:
- доступность услуг — включает в себя все вопросы, связанные с доступностью и недоступностью услуг, а также влияние доступности (или недоступности) отдельных компонентов на доступность услуг в целом.
- доступность компонентов — включает в себя все вопросы, связанные с доступностью и недоступностью компонентов.
Управление доступностью основано на мониторинге, анализе, измерении и формировании отчетов о следующих компонентах:
- Доступность — способность услуги, компонента или конфигурационной единицы выполнять согласованную функцию тогда, когда это требуется. Обычно измеряется в процентах по следующей формуле: Доступность(%)=(Согласованное время предоставления услуги-Время простоя)/Согласованное время предоставления услуги*100
Естественно, время простоя включается в расчет при наличии простоя. Если его не было, то доступность услуги будет стопроцентная.
- Среднее время между инцидентами (Mean Time Between Service Incidents или MTBSI) — это среднее время от момента сбоя системы или услуги до следующего сбоя[1]. Надежность(MTBSI в часах)=Время доступности в часах/Количество сбоев
Надежность( MTBF в часах) = (Время доступности в часах — Общее время простоя в часах)/Количество сбоев
Пример. Пусть услуга, которая используется 7 дней в неделю 24 часа в сутки, проработала 7010 часов. За это время было 2 сбоя. Простой в результате первого сбоя был 10 часов, в результате второго — 5 часов.
Доступность=(7010-(5+10))/7010*100=99,78 %
Надежность(MTBSI)=7010/2=3505
Надежность( MTBF )=(7010-(5+10))/2=3497.5 часов
Сопровождаемость(MTRS)=(5+10)/2=7.5 часов
увеличить изображение
Рис. 5.7. Термины Доступности и их взаимосвязь
В контексте процессов Проектирования вводится также термин Критичная бизнес-функция (Vital Business Function или VBF) — функция в бизнес-процессе, критичная для успеха Бизнеса[1]. Чем выше критичность функции для бизнеса, тем большую надежность и доступность в отношении нее необходимо обеспечить. Некоторые VBF требуют особого подхода при проектировании обслуживающих их услуг:
- высокая доступность — характеристика услуги, отражающая то, что последствия сбоев компонентов услуги минимизированы и/или незаметны для пользователей.
- устойчивость к сбоям — способность услуги, компонента или конфигурационной единицы продолжать работу после сбоя какой-то составляющей.
- непрерывная эксплуатация — подход к проектированию, направленный на устранение плановых простоев услуг. Отдельная конфигурационная единица может быть отключена, в то время как услуга останется доступной.
- непрерывная доступность — подход к проектированию, направленный на достижение 100% доступности. Непрерывно доступная услуга не имеет планового или внепланового простоя.
Входами процесса Управления доступностью являются:
- информация от бизнеса — стратегия, планы и бюджет организации, ее текущие и будущие требования, в том числе требования к доступности новых или измененных услуг;
- информация от Анализа влияния на бизнес, в том числе определение перечня VBF;
- информация от проведенных ранее анализа рисков и оценки;
- информация об услугах от Портфеля услуг и Каталога услуг; от SLM , в том числе целевые показатели услуг из SLA и SLR ;
- финансовая информация от Управления финансами — стоимость предоставления услуг и затраты на ресурсы;
- информация о релизах и изменениях от процессов Управления изменениями и Управления релизами, в частности расписания релизов и изменений;
- информация от Управления конфигурациями о связях бизнеса с услугами, вспомогательными услугами и технологиями.
- целевые показатели услуг из SLA, SLR , OLA и других контрактов.
- информация о компонентах — доступность, надежность и сопровождаемость компонентов, которые лежат в основе услуг;
- информация о технологиях — топология и связи компонентов, а также возможности новых технологий
- информация о производительности в прошлом;
- информация о случаях недоступности и сбоях.
Выходами процесса Управления доступностью являются:
- Система управления доступностью (Availability Management Information System или AMIS) — виртуальный репозиторий для всех данных, находящихся под контролем Управления доступности[1]. Обычно это физически распределенное хранилище;
- План управления доступностью;
- критерии для проектирования доступности, предлагаемые целевые показатели;
- отчеты о доступности, надежности и сопровождаемости услуг в контексте достижения ими целевых показателей;
- отчеты о доступности, надежности и сопровождаемости компонентов в контексте достижения ими целевых показателей;
- пересмотренный обзор рисков, обновление списка рисков;
- требования к мониторингу, управлению и отчетности в отношении услуг, которые гарантируют, что любые отклонения в доступности, надежности и сопровождаемости будут обнаружены и устранены;
- расписание проведения тестирования доступности, надежности и сопровождаемости;
- расписание для планового и реактивного обслуживания услуг и их компонентов;
- формирование Ожидаемого простоя услуги. Ожидаемый простой услуги (Projected Service Outage или PSO) — документ, определяющий влияние спланированных изменений, деятельности по обслуживанию и планов тестирования на согласованный Уровень услуг[1];
- детальное описание проактивных технологий, которые будут использованы для улучшения надежности и доступности
- действия по совершенствованию услуг для включения в SIP.
Для оценки эффективности процесса Управления доступностью можно использовать множество ключевых показателей производительности, например:
- Управление доступностью и надежностью услуг:
- процентное уменьшение недоступности услуг и их компонентов
- процентное увеличение надежности услуг и их компонентов
- эффективный пересмотр SLA, OLA и других основополагающих контрактов и договоров;
- процентное улучшение конечной доступности услуг;
- процентное уменьшение количества сбоев и их влияния;
- улучшение MTBF ;
- улучшение MTBSI;
- улучшение MTRS.
- процентное уменьшение недоступности услуг;
- процентное уменьшение стоимости простоя для бизнеса;
- процентное уменьшение сбоев во время, критичное для бизнеса;
- процентное увеличение удовлетворенности бизнеса.
- процентное уменьшение стоимости недоступности;
- своевременное завершение Анализа рисков и обзора системы;
- своевременно завершение анализа рисков «затраты-выгоды»;
- процентное уменьшение сбоев компонентов и услуг третьих сторон;
- сокращение времени на проведение Анализа рисков;
- сокращение времени на проведение анализа системы на надежность;
- сокращение времени на формирование Плана управления доступностью;
- своевременное формирование управленческих отчетов.
Управление доступностью должно формировать и управлять AMIS . AMIS является центральным репозитарием для хранения всей информации, документов, метрик и т.п., необходимых для осуществления Управления доступностью.
Рекомендуется формировать План управления доступностью на срок один-два года, с детализацией на первые полгода. План должен регулярно пересматриваться и обновляться.
Основным риском для процесса Управления доступностью, также как и для предыдущих процессов, является недостаточность или неточность информации, поступающей от бизнеса и IT.
Источник: intuit.ru
Граница между доступностью и непрерывностью

Граница между двумя процессами – управление доступностью и управление непрерывностью ИТ-услуг – неочевидна, и часто вызывает сложности, особенно у тех, кто только знакомится с ITIL. Действительно, процессы используют схожие техники. В основе обоих процессов лежит понятие риска: мы должны идентифицировать нежелательные события, угрожающие вывести из строя услуги, затем думать, как с этим справляться. И в том, и в другом случае требуется понимание критических бизнес-функций (VBF) и анализ влияния отказов услуг/систем на бизнес-процессы (BIA). Оба процесса , в конечном счете, решают задачу обеспечения устойчивости организации к отказам.
Так ли важно разделять эти процессы? На прошедшем недавно курсе PPO мы с группой составили небольшую табличку, иллюстрирующую различия, которую я с незначительными правками привожу здесь:
Управление доступностью (AVA)
Управление непрерывностью (CONT)
Фокус на рисках с высокой вероятностью
Фокус на рисках с высоким ущербом (ЧС, disasters)
Снижает вероятность наступления нежелательных событий
Снижает ущерб от наступления нежелательных событий
Акцент на технических решениях
Акцент на организационных мерах
Не является частью корпоративной функции
Часто является частью корпоративной функции
MTRS, MTBF, MTBSI
CONT не интересуют незначительные и короткие сбои, не имеющие серьезного влияния на бизнес. В охват CONT попадают риски, связанные со значительным ущербом независимо от вероятности их наступления. Это часто ЧС, disasters, такие как пожары, затопления, отключения электричества, недоступность ЦОДа или целых площадок и т.д. Несмотря на то, что AVA не забывает о негативном влиянии отказов на бизнес-процессы, в процессе также рассматриваются незначительные прерывания отдельных компонентов.
Планирование доступности направлено на соответствие текущим и будущим согласованным требованиям заказчиков и недопущение отклонений. Мы ищем и устраняем единые точки отказа, предпринимаемые меры, как правило, носят проактивный характер и снижают вероятность наступления нежелательных событий. CONT рассматривает наступление нежелательных событий как факт, к которому нужно подойти во всеоружии. Резервные площадки, переход на альтернативные способы предоставления услуги, процедуры восстановления – все это позволяет снизить ущерб, но никак не влияет на вероятность происшествия.
Назначение AVA: обеспечение того, что уровень доступности предоставляемых услуг соответствует текущим и будущим согласованным требованиям заказчиков при разумном уровне затрат. Мы пытаемся достичь максимального уровня доступности при имеющихся ресурсах, оптимизируем. CONT, не забывая, конечно, об экономической оправданности мер, почти всегда создает избыточность (резервные площадки, подменный фонд оборудования, соглашения на предоставление мощностей в случае ЧС). Задачи – явно конфликтующие, и на определенном масштабе не совмещаемые в одной голове.
Процессы используют разные метрики. В AVA – это:
- MTRS – среднее время восстановления услуги.
- MTBF – среднее время между сбоями (от возобновления работы после сбоя до следующего сбоя).
- MTBSI – среднее время между инцидентами (от сбоя до следующего сбоя).
Очевидно, что при достаточно высоких средних значениях возможен длительный разовый простой, в течение которого бизнес понесет значительный ущерб. CONT вводит:
- RTO (recovery time objective) – целевое время восстановления. За какое время после сбоя мы должны возобновить предоставление услуги.
- RPO (recovery point objective) – целевая точка восстановления. ЧС часто приводят к полному отказу или даже разрушению систем и потери данных. В зависимости от того, потеря данных за какой период критична для бизнеса, мы понимаем, какую частоту и способ резервного копирования должны выбрать.
AVA работает со статистикой, анализирует тенденции, CONT озабочен тем, как не допустить значительные разовые простои.
Несмотря на все различия, ISO 20000 эти два процесса объединяет, а MOF4 идет еще дальше и вводит функцию надежности, в которой учтены все четыре аспекта гарантии (доступность, мощность, безопасность, непрерывность).
Что вы думаете о границе между управлением доступностью и управлением непрерывностью? Какой подход ближе: объединять/разделять? Может быть, есть практический опыт реализации этих процессов.
Также по теме:
- Граница между постоянным совершенствованием и управлением проблемами
- Ключевые практики управления доступностью и непрерывностью
- Граница между изменением и проектом
- Где граница между изменениями и «просто работой»?
- Нужен ли процесс управления доступностью?
Источник: cleverics.ru
управлению инцидентами ITIL
Получите представление об основных понятиях управления инцидентами ITIL, соответствующих рабочих процессах, а также ознакомьтесь с советами и рекомендациями в этой области.

Управление инцидентами
- Определения
- Рабочий процесс
- Роли и области ответственности
- КПЭ
- Советы и рекомендации
- Список функций
Другие понятия ITIL
- Управление проблемами
- Управление изменениями
- Управление активами
- Идентификация инцидента
- Регистрация инцидента
- Классификация инцидента
- Закрытие инцидента
- Правила эскалации инцидентов
- Управление инцидентами
- Присвоение приоритета инциденту
- Отчет об инцидентах
- Предоставление решения по инциденту
Дата последнего обновления: September 19, 2019
Управление ИТ-инцидентами – это один из основных процессов в работе службы поддержки. В этом руководстве представлены основные сведения об управлении инцидентами, его компонентах, ролях и областях ответственности, а также о том, как управление согласуется с другими компонентами работы службы поддержки.
Ниже перечислены темы, рассматриваемые в рамках данного руководства.
- Определение инцидента
- Жизненный цикл/схема управления инцидентами ITIL
- Роли и области ответственности в управлении инцидентами
- Ключевые показатели эффективности управления инцидентами
- Преимущества управления инцидентами
- Рекомендации по управлению инцидентами
- Список функций программного обеспечения для управления инцидентами
- Различия между управлением инцидентами и управлением проблемами
- Различия между управлением инцидентами и управлением изменениями
- Различия между управлением инцидентами и управлением активами
- Глоссарий терминов ITIL по управлению инцидентами
Управление инцидентами
Что такое ИТ-инцидент?
ИТ-инцидент – это нарушение в работе ИТ-служб организации, которое оказывает влияние как на отдельного пользователя, так и на организацию в целом. Если говорить кратко, инцидент – это любая ситуация, которая прерывает бесперебойную работу бизнеса.
Что такое управление ИТ-инцидентами?
Управление инцидентами представляет собой процесс управления нарушениями в работе ИТ-служб и восстановления их работоспособности в течение срока, который указан в соглашении об уровне обслуживания (SLA).
Область управления инцидентами начинается с момента сообщения конечным пользователем о проблеме и заканчивается устранением проблемы специалистом службы поддержки.
Этапы управления инцидентами
Организовав управление инцидентами надлежащим образом, можно оптимизировать сбор информации об инцидентах и упорядочить ее, избавившись от путаницы в переписке по электронной почте. Специалисты службы поддержки могут опубликовать соответствующие формы на портале самообслуживания для пользователей, чтобы обеспечить своевременный сбор всей необходимой информации при создании заявки.
Следующий этап управления инцидентами подразумевает классификацию инцидента и присвоение ему приоритета. Это не только помогает сортировать поступающие заявки, но и гарантирует переадресацию заявки тем специалистам, которые обладают всеми необходимыми знаниями и навыками для устранения проблемы. Благодаря классификации инцидентов к инцидентам применяются наиболее подходящие SLA, а конечные пользователи могут узнать о приоритете своих обращений. После того как инциденту присвоены класс и приоритет, технические специалисты могут выполнить диагностику и предоставить конечному пользователю соответствующее решение.
При наличии соответствующих процессов автоматизации управление инцидентами позволяет специалистам службы поддержки отслеживать соблюдение SLA. Также можно настроить уведомление технических специалистов о нарушении SLA; технические специалисты также могут эскалировать нарушения SLA, настроив автоматическую эскалацию, когда это применимо к инциденту. После диагностики проблемы технический специалист предлагает конечному пользователю решение, которое последний может проверить. Данный многоэтапный процесс обеспечивает оперативное устранение ИТ-проблем, которые оказывают влияние на бесперебойную работу бизнеса.
Классификация ИТ-инцидентов
Существуют различные способы классификации инцидентов в ИТ-среде. К факторам, влияющим на классификацию, относятся срочность и степень влияния инцидента на каждого пользователя в отдельности и бизнес в целом. Классификация ИТ-инцидентов помогает в определении инцидентов и их переадресации соответствующим техническим специалистам, что позволяет сэкономить время и усилия.
Например, по степени влияния инцидентов на бизнес и срочности их можно классифицировать как серьезные или незначительные. Обычно к серьезным инцидентам относят проблемы, которые оказывают влияние на работу критически важных служб, что влияет на функционирование всей организации в целом. Такие инциденты подлежат немедленному устранению. Незначительные инциденты обычно затрагивают одного пользователя или определенный отдел. Также в отношении таких инцидентов могут иметься задокументированные решения.
Что происходит, когда в организации отсутствует управление ИТ-инцидентами?
Управление инцидентами затрагивает каждый аспект инцидента на протяжении всего его жизненного цикла. Управление инцидентами ускоряет процесс предоставления решения и обеспечивает прозрачность управления заявками. Без управления инцидентами обработка заявок может оказаться достаточно сложной задачей. Вот некоторые из основным проблем, с которыми можно столкнуться:
- Недостаточная прозрачность сведений о статусе заявки и ожидаемых сроках для конечных пользователей.
- Ненадлежащее протоколирование предыдущих инцидентов.
- Невозможность задокументировать решения для повторяющихся или схожих проблем.
- Более высокий риск возникновения простоев в работе, особенно при возникновении серьезных инцидентов.
- Увеличенные сроки предоставления решения.
- Недостаток возможностей для создания отчетов.
- Снижение уровня удовлетворенности клиентов.
Хотите оптимизировать управление инцидентами в своей организации?
Кто использует управление ИТ-инцидентами?
Управление инцидентами широко применяется службами ИТ-поддержки по всему миру. Обычно служба поддержки является единой точкой обращения конечных пользователей для сообщения о проблемах в отдел управления ИТ-инфраструктурой.
Жизненный цикл управления ИТ-инцидентами
Процесс управления инцидентами включает следующие этапы:
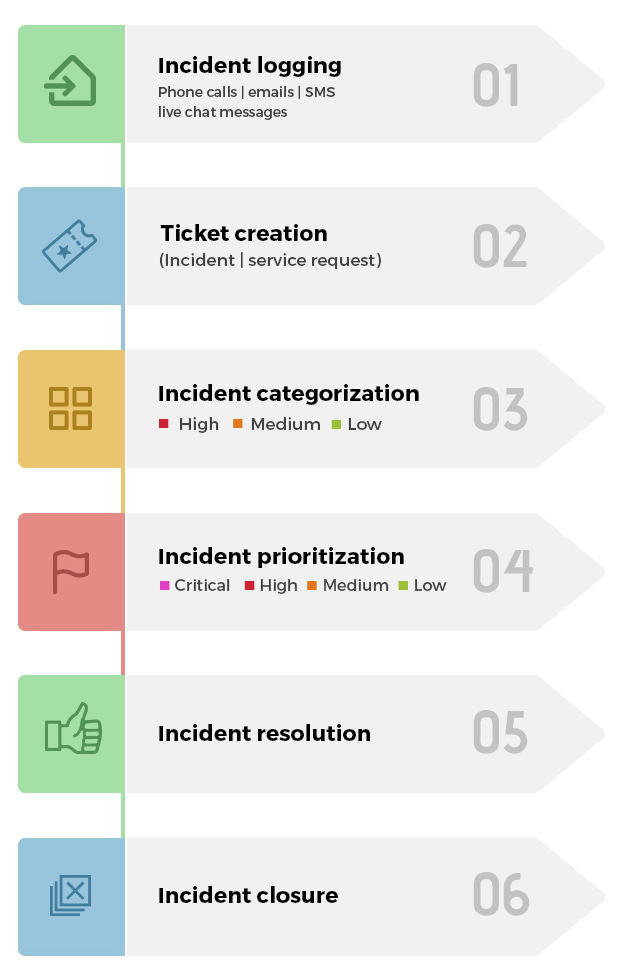
- Этап 1 : Регистрация инцидента.
- Этап 2 : Классификация инцидента.
- Этап 3 : Присвоение приоритета инциденту.
- Этап 4 : Назначение инцидента.
- Этап 5 : Создание задач и управление ими.
- Этап 6 : Управление SLA и эскалация.
- Этап 7 : Предоставление решения по инциденту.
- Этап 8 : Закрытие инцидента.
Жизненный цикл управления инцидентами
В зависимости от типа инцидента эти процессы могут быть простыми или сложными; помимо основного процесса, указанного выше, они также могут включать несколько рабочих процессов и задач.
Регистрация инцидента
Классификация инцидента
Присвоение приоритета инциденту
- Критический
- Высокий
- Средний
- Низкий
Источник: www.manageengine.com