CRISP-DM (CRoss Industry Standard Process for Data Mining) наиболее распространенная и популярная методология ведения проектов интеллектуального анализа данных [1] . Опросы, проводившиеся в 2002, 2004 и 2007 годах, показывают, что эта методология часто применяется исследователями данных. [1] [1] [1]
Зачем нужна методология?
Проекты анализа данных должны:
- надежно исполняться испытанными средствами с предсказуемыми результатом (Reliable);
- быть повторяемыми, особенно людьми с малым опытом в анализе данных (Repeatable).
Следование методике дает нам:
- Средства для сохранения опыта проектов, накопленный опыт позволяет нам успешно повторять проекты;
- Упрощение планирования и управления проектами, известная и привычная последовательность действий и набор необходимых артефактов;
- Простоту включения в работу новых членов команды, уменьшение зависимости от «звезд».
Инструменты методологии
Иерархическая декомпозиция
Основная статья: CRISP-DM/Hierarchical breakdown
Применение общей модели в конкретном проекте
Основная статья: CRISP-DM/Generic model mapping
База знаний
Основная статья: CRISP-DM/Knowledge base
(TODO: рекомендации по накоплению базы знаний)
В базе знаний сохраняются хорошо зарекомендовавшие себя методы для последующего применения в других проектах.
Основные этапы проекта
CRISP-DM разбивает процесс анализа данных на шесть основных этапов [1] :
Понимание бизнеса (Business Understanding)
Основная статья: CRISP-DM/Business Understanding
Первая фаза процесса направлена на определение целей проекта и требований со стороны бизнеса. Затем эти знания конвертируются в постановку задачи интеллектуального анализа данных и предварительный план достижения целей проекта.
- Определить бизнес цели
- Оценить ситуацию
- Определить цели анализа данных
- Составить план проекта
Понимание данных (Data Understanding)
Основная статья: CRISP-DM/Data Understanding
Вторая фаза начинается со сбора данных и ставит целью познакомиться с данными как можно ближе. Для этого необходимо выявить проблемы с качеством данных такие как ошибки или пропуски, понять что за данные имеются в наличии, попробовать отыскать интересные наборы данных или сформировать гипотезы о наличии скрытых закономерностей в данных.
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
Подготовка данных (Data Preparation)
Основная статья: CRISP-DM/Data Preparation
Фаза подготовки данных ставит целью получить итоговый набор данных, которые будут использоваться при моделировании, из исходных разнородных и разноформатных данных. Задачи подготовки данных могут выполняться много раз без какого-либо наперед заданного порядка. Они включают в себя отбор таблиц, записей и атрибутов, а также конвертацию и очистку данных для моделирования.
- Отобрать данные
- Очистить данные
- Сделать производные данные
- Объединить данные
- Привести данные в нужный формат
Моделирование (Modeling)
Основная статья: CRISP-DM/Modeling
В этой фазе к данным применяются разнообразные методики моделирования, строятся модели и их параметры настраиваются на оптимальные значения. Обычно для решения любой задачи анализа данных существует несколько различных подходов. Некоторые подходы накладывают особые требования на представление данных. Таким образом часто бывает нужен возврат на шаг назад к фазе подготовки данных.
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
Оценка (Evaluation)
Основная статья: CRISP-DM/Evaluation
На этом этапе проекта уже построена модель и получены количественные оценки её качества. Перед тем, как внедрять эту модель, необходимо убедиться, что мы достигли всех поставленных бизнес-целей. Основной целью этапа является поиск важных бизнес-задач, которым не было уделено должного внимания.
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
Развертывание (Deployment)
Основная статья: CRISP-DM/Deployment
В зависимости от требований фаза развертывания может быть простой, например, составление финального отчета, или сложной, например, автоматизация процесса анализа данных для решения бизнес-задач. Обычно развертывание — это забота клиента. Однако, даже если аналитик не принимает участие в развертывании, важно дать понять клиенту, что ему нужно сделать для того, чтобы начать использовать полученные модели.
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
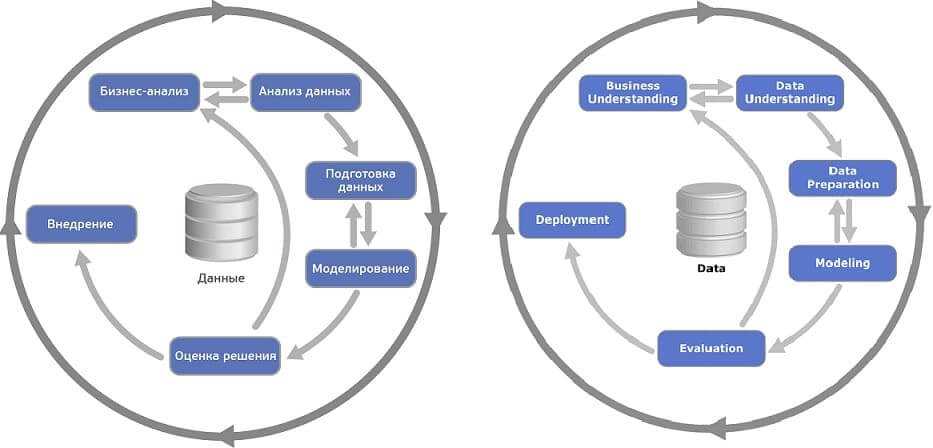
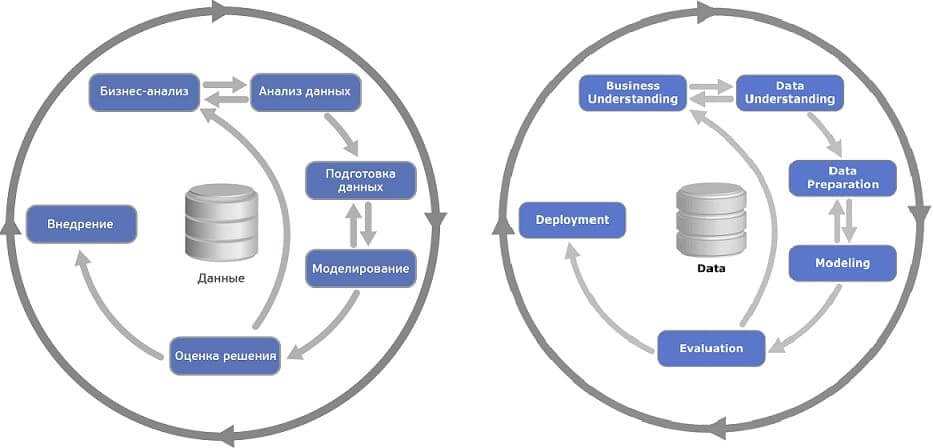
Перемещение вперед и назад между фазами — обычное дело. В зависимости от результата фазы или её подзадачи принимается решение, в какую фазу переходить дальше. Стрелками обозначены наиболее важные и частые переходы между фазами.
Внешний круг символизирует циклическую природу анализа данных. Процесс анализа данных продолжается и после развертывания решения. Знания, полученные во время процесса, могут породить новые более тонкие вопросы бизнеса. Последующий процесс анализа данных выгодно проводить, используя знания, полученные ранее. [1]
История
Идея CRISP-DM зародилась в 1996. В 1997 была начата разработка проекта в Европейском Содружестве под эгидой фонда ESPRIT (European Strategic Program on Research in Information Technology). Проект возглавили четыре компании: ISL, NCR Corporation, Daimler-Benz и OHRA.
Эти компании объединили свой опыт в проекте. ISL впоследствии была поглощена SPSS Inc. на тот момент имела программный продукт для анализа данных Clementine. Компьютерный гигант NCR Corporation, породивший Teradata — СУБД для хранения сверхбольших данных, имел штат консультантов и собственное программное обеспечение по анализу данных. В Daimler-Benz была большая команда интеллектуального анализа данных для удовлетворения нужд собственного бизнеса. Страховая компания OHRA начала исследовать потенциал интеллектуального анализа данных.
Первая версия методологии была выпущена CRISP-DM 1.0 в 1999.
В июле 2006 консорциум анонсировал желание начать работу над второй версией CRISP-DM. 26 сентября 2006, инициативная группа CRISP-DM собрались для обсуждения потенциальных улучшений в CRISP-DM 2.0 и последующего плана работ. Однако, этим начинаниям не суждено было быть завершенными. С начала 2007 года инициативная группа больше не собиралась, вебсайт CRISP не обновлялся и не появлялось какой-либо новой информации.
Преимущества методологии
- Пригодна для любой индустрии.
- Можно использовать любые инструменты.
- Близка по духу к KDD Process Model.
- Делает основной упор на интеллектуальном анализе данных.
Ссылки
Сноски
Смотри также
- Численные методы обучения по прецедентам
- Автоматизация и стандартизация научных исследований
- Отчет о выполнении исследовательского проекта
Источник: www.machinelearning.ru
Цикл работы с данными
Digital-Content-Files.jpg Цикл работы с данными этапы и виды работ, которые необходимо проделать, чтобы получить новую информацию на их основе 200 Данные и их применение Начальная Полезно IT/soft Да Данные (раздел) Цифровая экономика (раздел) Базовые понятия (раздел) Межотраслевое (раздел) Базовые информационные технологии (раздел) Системы баз данных (раздел) 4 Цикл работы с данными
Цикл работы с данными
этапы и виды работ, которые необходимо проделать, чтобы получить новую информацию на их основе


Рекомендовано





Направление исследований
Один из подходов работы с данными – это методология исследования данных CRISP, которая включает в себя шесть этапов: понимание бизнеса, начальное изучение данных, подготовка данных, моделирование, оценка решения и внедрение.
Цикл работы с данными по методологии CRISP
CRISP-DM (Cross-Industry Standard Process for Data Mining — межотраслевой стандартный процесс для исследования данных) — это проверенная в промышленности и наиболее распространённая методология по исследованию данных.
Данная схема включает в себя шесть этапов
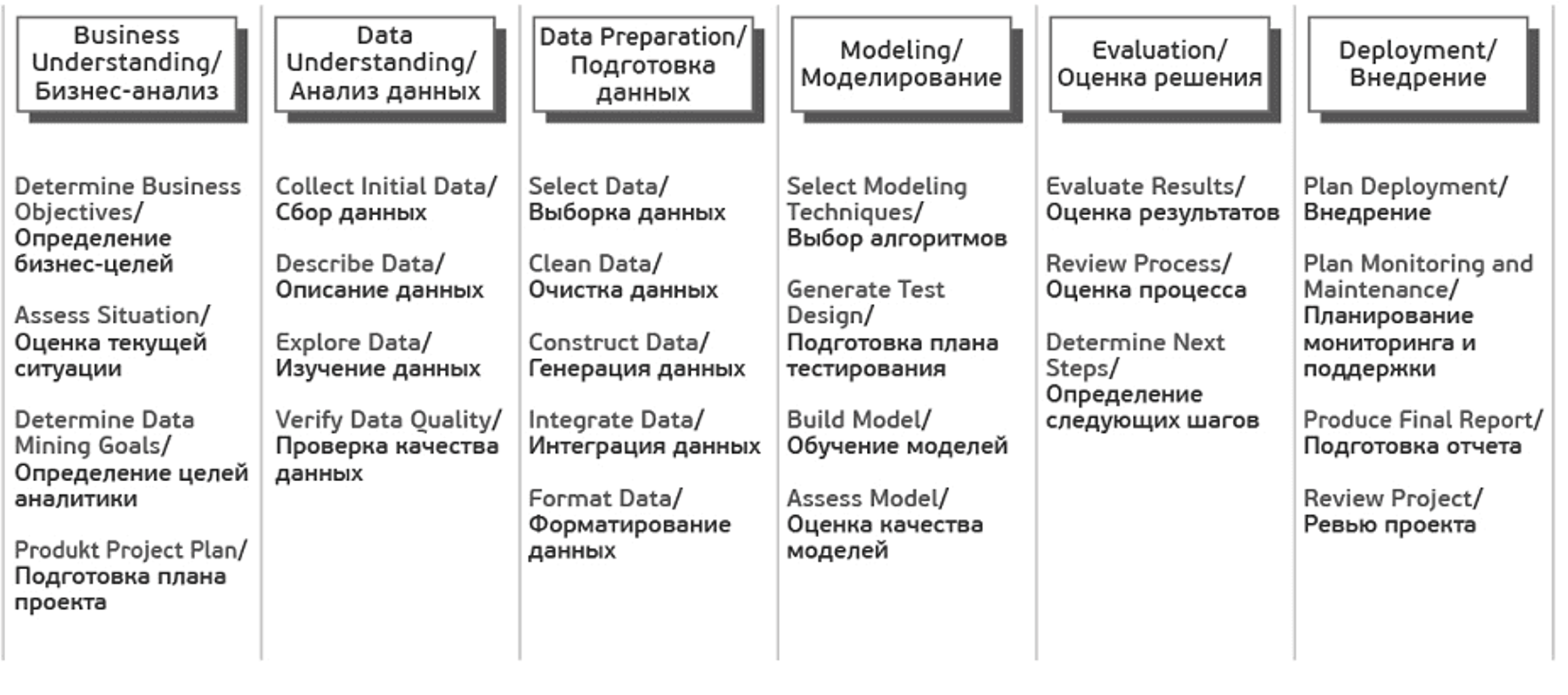
Понимание бизнеса (Business Understanding) – на первом этапе работы с данными вам нужно понять, зачем вам собирать и анализировать данные, а также какие данные вам необходимы. Определение целей и предварительные гипотезы на данных затем лягут в основу вашего проекта.
Задачи фазы Business Understanding:
- Определить цели вашей организации
- Оценить текущую ситуацию
- Определить цели анализа данных
- Составить план проекта
Начальное изучение данных (Data Understanding) – на втором этапе работы с данными вам нужно оценить качество ваших данных: насколько данные полные, есть ли в них ошибки, пробелы и пропуски. Нужно понять, какими сведениями вы обладаете, сформулировать к ним вопросы и итоговые гипотезы о скрытых закономерностях
Задачи фазы Data Understanding:
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
Подготовка данных (Data Preparation) – на этом этапе вам нужно сформировать итоговый набор данных для анализа, “очистить” данные, привести их в единых формат из исходных разнородных и разноформатных данных.
Задачи фазы Data Preparation могут выполняться много раз без какого-то заранее определенного порядка:
- Отобрать данные (таблицы, записи и атрибуты)
- Очистить данные, в т.ч. выполнить их конвертацию и подготовку к моделированию
- Сделать производные данные
- Объединить данные
- Привести данные в нужный формат
Моделирование (Modeling) – на этом этапе вам нужно выбрать методику, каким образом анализировать данные, построить модель анализа. Модель должна отражать весь их процесс анализа (что вы хотите выяснить с помощью анализа данных, какие данные вы используете, как они организованы, как они обработаны, и так далее). У вас может возникнуть необходимость вернуться к фазе подготовки данных, так как разные методы анализа требуют различных форматов данных. Задачи фазы Modeling:
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
Оценка (Evaluation) – определение, удалось ли достигнуть целей с помощью разработанной модели и полученных результатов анализа. Данный этап позволяет понять, действительно ли те шаги, которые вы запланировали, позволяют получить те результаты, которые вы хотели. На данном этапе могут быть выявлены более важные задачи организации, которые не были учтены. Задачи фазы Evaluation:
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
Внедрение (Deployment) – этот этап может быть простым или сложным, в зависимости от целей организации. Обычно это — разработка и внедрение решений на основе анализа данных. Это может быть как составление отчета, так и автоматизация процессов для решения ваших целей. Задачи фазы Deployment:
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
Рассмотрим подробнее некоторые аспекты этапов подготовки и моделирования данных, инструменты подготовки данных и способы их моделирования
Сбор данных
Важный вопрос на этом этапе — поиск данных. Согласно И.В. Бегтину поиск данных осуществляется по следующей схеме:
- формулировка запроса — что ищем;
- запрос консультаций с целью помощи в поиске источников поиска;
- самостоятельный поиск;
- запрос и получение данных.
Хранение данных
Хранение данных — это процесс обеспечения доступности, целостности, защищенности данных. Данные можно хранить разным способом:
- твердотельный съемный или несъемный носитель — нужен доступ к самому носителю или устройству, в которое он помещается, для получения данных;
- сервера баз данных;
- облачное хранилище данных — доступ к данным возможен из любой локации и др.
Выбор способа хранения данных зависит от объема данных, необходимой скорости доступа к ней, частоте обновлений данных, количества лиц, которым будет разрешен доступ к данным, стоимости хранения нужного объема данных.
Основной формой хранения данных является база данных. С помощью СУБД можно получить доступ к данным, записать их, переместить, изменить, удалить.

Обработка данных
Под обработкой данных понимается определенная последовательность операций с данными, выполненных для получения новой информации путем пересмотра и уточнения имеющейся результатов анализа данных, вычислений и пр. На первом этапе осуществляется первичная обработка данных — приведение данных к единому формату, выделение общих признаков, структурирование данных. Затем выбирается наиболее актуальная для решения задачи модель работы:
- точечная обработка активных задач — операции только с выбранными категориями;
- потоковая обработка в реальном времени — операции с большим объемом данных, поступающих непрерывно, в процессе чего результаты анализа меняются каждый раз когда поступают новые данные;
- пакетная обработка исторических данных — обработка данных, накопленных за определенный срок.
В зависимости от выбранной модели, решаемой задачи подбираются технологии, тип базы данных, которые будут наиболее эффективны в конкретном случае. К процедурам обработки данных относятся: создание данных, модификация данных, поиск информации, принятие решений, создание отчетов, создание документов, повышение безопасности данных.
При обработке данных обращают внимание на их качество. Выделяют чистые и грязные данные. Грязные данные отличает наличие обработки, дополнительной, не связанных с первоначальными данными, информации, недостаток первичных данных. Все это мешает полному анализу данных, так как грязные данные уже содержат в себе некоторые критерии анализа, “обнулить” значение которых нельзя.
Визуализация данных
Визуализация данных — процесс представления данных в агрегированном, понятном для восприятия человеком виде. Визуализация может быть презентационной — готовой для демонстрации аудитории, исследовательской — готовой для получения некоторых промежуточных результатов обработки данных. Визуализация может быть использована на всех этапах работы с данными: визуализация результатов первичной обработки, визуализация промежуточных результатов, визуализация окончательных результатов.
В связи с объемом анализируемых данных визуализация – это необходимый способ оформления данных в понятный человеку вид. Поэтому инструменты визуализации важны в работе с данными.
Вид визуализации данных:
- Графики: линейный, график рассеивания и др.
- Диаграммы: столбиковая, круговая, гистограмма, кольцевая, лепестковая, облако тегов и др.
- Инфографика.
- Схемы.
- Презентации.
- Карты: фотографическая, географическая, дорожная, тематическая, картограмма.
- Дашборды.
- Иллюстрации.
Выводы
- Методология исследования данных CRISP включается шесть этапов: понимание бизнеса, начальное изучение данных, подготовка данных, моделирование, оценка решения и внедрение.
- Поиск данных включает четыре этапа: формулировка запроса, консультации, самостоятельный поиск, запрос и получение данный
- Хранить данные можно на твердых носителях, серверах или в облачных хранилищах.
- Обработка данных включает в себя: первичную обработку и очистку, выделение общих признаков, уплотнение данных, выбор модели для анализа.
- Анализ данных — совокупность действий исследователя, направленных на получение определенных представлений о характере явления, описываемых этими данными.
- Визуализация данных — процесс представления данных в агрегированном, понятном для восприятия человеком виде.
Источник: cdto.wiki
CRISP-DM
CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных. Это проверенная в промышленности и наиболее распространённая методология, первая версия которой была представлена в Брюсселе в марте 1999 года, а пошаговая инструкция опубликована в 2000 году [1].
CRISP-DM описывает жизненный цикл исследования данных, состоящий из 6 фаз, от постановки задачи с точки зрения бизнеса до внедрения технического решения.
Последовательность между фазами определена не строго, переходы могут повторяться от итерации к итерации [1]. Все фазы CRISP-DM делятся на задачи, по итогам каждой должен быть достигнут конкретный результат [2].
Рассмотрим подробнее фазы жизненного цикла исследования данных по CRISP-DM [3]:
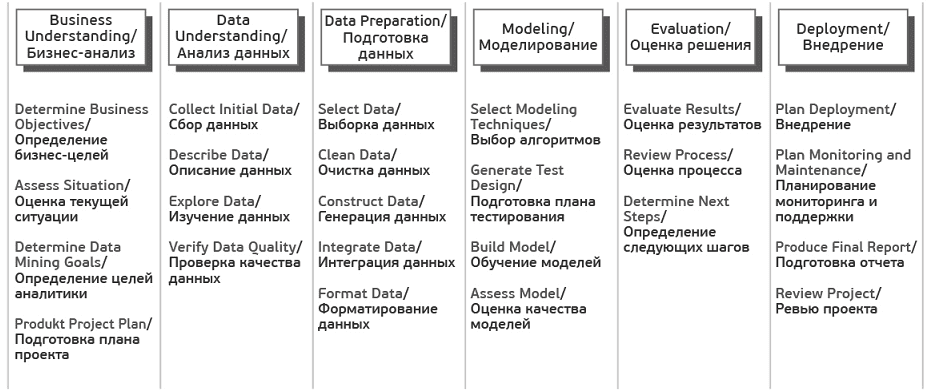
- Понимание бизнеса (Business Understanding) – определение целей проекта и требований со стороны бизнеса. Затем эти знания конвертируются в постановку задачи интеллектуального анализа данных и предварительный план достижения целей проекта. Задачи фазы Business Understanding:
- Определить бизнес-цели
- Оценить ситуацию
- Определить цели анализа данных
- Составить план проекта
- Начальное изучение данных (Data Understanding) – сбор данных и знакомство с информацией, выявление проблем с качеством данных (ошибки или пропуски). Необходимо понять, какие сведения имеются, попробовать отыскать интересные наборы данных или сформировать гипотезы о наличии в них скрытых закономерностей. Задачи фазы Data Understanding:
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
- Подготовка данных (Data Preparation) – получение итогового набора данных, которые будут использоваться при моделировании, из исходных разнородных и разноформатных данных. Задачи фазы Data Preparation могут выполняться много раз без какого-то заранее определенного порядка:
- Отобрать данные (таблицы, записи и атрибуты)
- Очистить данные, в т.ч. выполнить их конвертацию и подготовку к моделированию
- Сделать производные данные
- Объединить данные
- Привести данные в нужный формат
- Моделирование (Modeling) – в этой фазе к данным применяются разнообразные методики моделирования, строятся модели и их параметры настраиваются на оптимальные значения. Обычно для решения любой задачи анализа данных существует несколько различных подходов. Некоторые подходы накладывают особые требования на представление данных. Таким образом часто бывает нужен возврат на шаг назад к фазе подготовки данных. Задачи фазы Modeling:
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
- Оценка (Evaluation) – анализ количественных характеристик качества модели, подтверждение или опровержение того, что, благодаря построенной модели все бизнес-цели достигнуты. Основной целью этапа является поиск важных бизнес-задач, которым не было уделено должного внимания. Задачи фазы Evaluation:
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
- Внедрение (Deployment) – в зависимости от требований фаза развертывания может быть простой (составление финального отчета) или сложной, например, автоматизация процесса анализа данных для решения бизнес-задач. Обычно развертывание — это внедрение полученных моделей в прикладную сферу. Задачи фазыDeployment:
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
CRISP-DM является одним из важнейших понятий для технологий больших данных (Big Data), которое на практике используется аналитиками и исследователями данных (data scientist), для любой задачи и в каждой прикладной отрасли [2].
Источники
- https://ru.wikipedia.org/wiki/CRISP-DM
- https://habr.com/ru/company/lanit/blog/328858/
- http://www.machinelearning.ru/wiki/index.php?title=Crisp-dm
Источник: bigdataschool.ru