Помимо информационных услуг, компонентами процесса являются и другие данные, используемые для описания инфраструктуры бизнес-процессов. 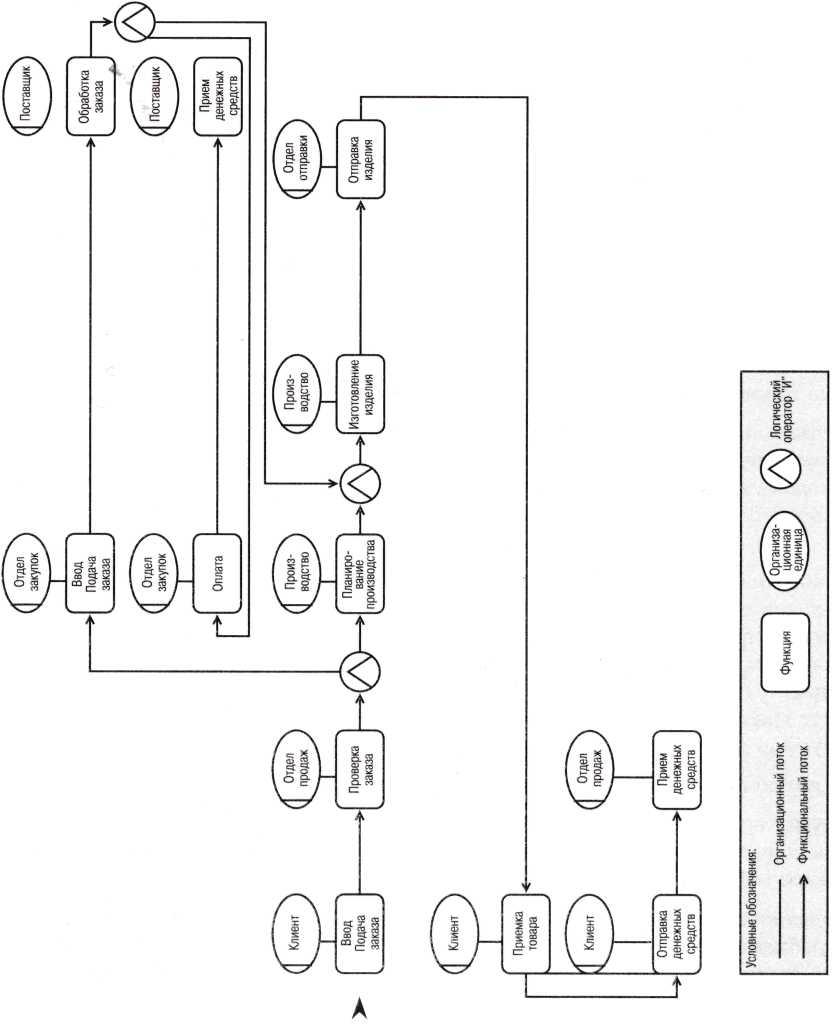 Рис. 3. Поток функций в бизнес-процессе «обработка заказа»
Рис. 3. Поток функций в бизнес-процессе «обработка заказа» 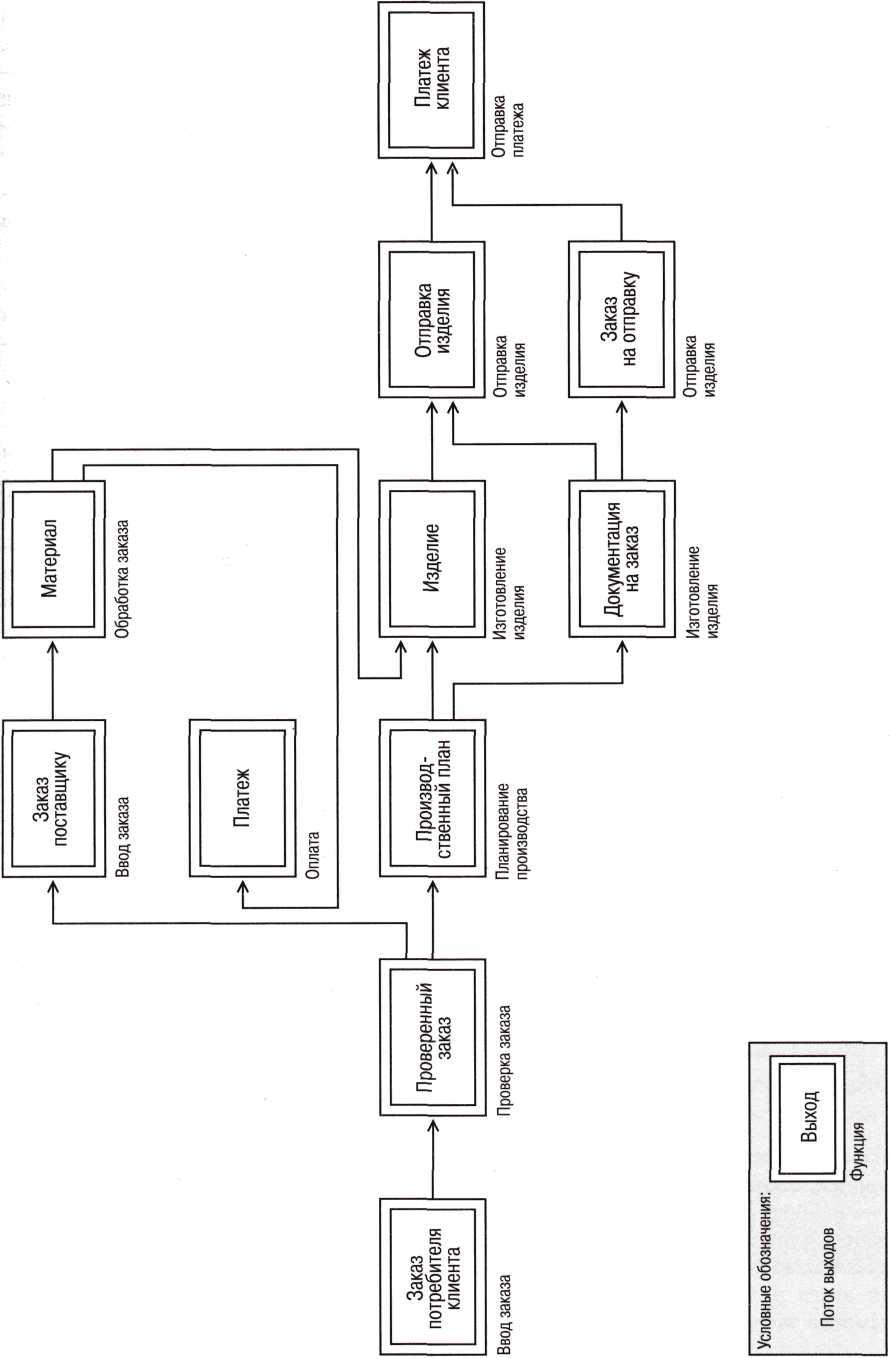 Рис. 4. Поток выходов в бизнес-процессе «обработка заказа» На рис.
Рис. 4. Поток выходов в бизнес-процессе «обработка заказа» На рис.
5 представлены информационные объекты бизнес-процесса и данные, которыми они обмениваются. Объекты, отнесенные к разряду информационных услуг, обведены двойной рамкой. Показаны также информационные объекты, описывающие контекстную среду бизнес-процесса, например, данные, касающиеся поставщиков, изделий или графиков работы.
Эти данные необходимы для создания информационных услуг. Например, при проверке заказов проверяется кредитоспособность заказчика и наличие материально-производственных запасов. Каждый информационный объект имеет свое имя. Ему можно присвоить и другие атрибуты, но для экономии места они здесь опущены.
Анна Вичугова . Практическое использование DFD: как описать движение данных в бизнес-процессах?
Функции процесса, работающие с информационными объектами, являются частью объектов, предоставляющих информационные услуги. Можно соотнести функции и с другими информационными объектами, однако это будут уже подфункции по отношению к функциям процесса, рассматривавшимся до сих пор, поэтому на рис. 5 они не показаны.
Например, детальную функцию «проверка кредитоспособности» можно соотнести с информационным объектом КЛИЕНТ в рамках функции процесса «проверка заказа». Поскольку поток данных активизируется функциями, связанными с информационными объектами, функциональный поток на рис. 5 более или менее просматривается. Однако если один информационный объект обрабатывается несколькими функциями или если одна функция требует нескольких потоков данных, то однозначно проследить функциональный процесс невозможно.
Б.1.5. Объединенная модель бизнес-процесса
Ни один из представленных здесь потоков (организационный, функциональный, выходной и информационный) не позволяет смоделировать бизнес-процесс полностью. Следовательно, необходимо собрать все описания воедино. Для этого нужно взять за основу одно из описаний, а затем интегрировать его с остальными.
Поскольку к определению бизнес-процесса ближе всего подходит поток функций, его мы и возьмем за отправную точку (рис. 6). Позже, при рассмотрении объектно-ориентированных методов, будет показано, как можно использовать в этой роли информационные потоки. Чтобы иметь возможность различать связи между объектами, представим потоки в диаграмме разными линиями.
Наличие стрелок, соответствующих потокам функций и выходов, может показаться избыточным, но они не всегда идут параллельно. После функции «обработка заказа» выполнение функции «изготовление изделия» активизируется поставщиком. Одновременно услуги поставщика оплачиваются отделом закупок, хотя первая функция фактически не имеет физического выхода. Информационные объекты, обозначенные как услуги, не привязываются к функциям в качестве информационных объектов. Если потоки (например, выходов и функций) идут параллельно, описание процесса можно рационализировать, опустив один из них.
Анна Вичугова — Практическое использование DFD: как описать движение данных в бизнес-процессах?
Источник: studfile.net
Диаграмма потоков данных
Диаграмма потоков данных — это визуальное представление перемещения данных в пределах процесса или системы. Такие диаграммы помогают совершенствовать внутренние процессы и системы и определять правильный путь для ключевых разделов вашего бизнеса.
Создать диаграмму потоков данных →
50M пользователей по всему миру доверяют Miro




Что такое диаграмма потоков данных?
Диаграмма потоков данных отображает последовательность данных, акторов и этапов в пределах процесса или системы. Для ее построения используется набор специальных символов, каждый из которых представляет разные этапы и лица, необходимые для надлежащего выполнения процесса. Такая диаграмма может быть простой или сложной — в зависимости от представляемой системы, но самым простым способом ее создания является использование конструктора диаграмм потоков данных . Диаграммы потоков данных чаще всего используются для наглядного представления потоков данных в информационных системах компаний. В представленном ниже примере диаграммы потоков данных показано, что подобные диаграммы иллюстрируют процесс обработки данных в системе с использованием набора входных и выходных переменных.
Как подсказывает название, диаграммы потоков данных предназначены для графического представления данных и информации. Это отличает их от диаграмм рабочего процесса или блок-схем процесса , которые могут отображать любой другой процесс или систему в компании. Совет: отличить блок-схему процесса и диаграмму потоков данных можно, обратив внимание на назначение стрелок. Стрелки на блок-схеме процесса указывают на последовательность событий, тогда как стрелки на диаграмме потоков данных — на перемещение данных. Диаграммы потоков данных помогают компаниям и предпринимателям понять, откуда поступают данные, как они обрабатываются в системе и куда передаются после обработки.
Преимущества диаграмм потоков данных
Диаграмма потоков данных представляет собой графическое отображение функций и процессов в системе, что помогает понять принципы сбора, хранения и обработки информации. Такое наглядное представление является отличным коммуникационным инструментом, который пользователь и разработчик системы могут использовать для обмена мнениями. Вот более подробное описание некоторых преимуществ диаграмм потоков данных.
Определение границ
Построение диаграммы потоков данных помогает описать и разметить границы в системе. Без диаграммы потоков данных компании может быть сложно понять, где начинается и заканчивается система. Определение конкретных границ позволяет четко очертить систему.
Улучшение обмена информацией
Схема потоков данных облегчает графическую коммуникацию между разработчиками и пользователями системы. Это может помочь инженерам и разработчикам понять потребности и запросы пользователя.
Эффективный инструмент визуализации
Представление сложной структуры данных в виде простой диаграммы потоков данных упрощает интерпретацию схемы. Диаграммы потоков данных помогают командам визуализировать данные и этапы программно-системных процессов. Визуализация крайне важна для понятного объяснения и лучшего запоминания процессов.
Представление логики
Диаграммы потоков данных отражают логику перемещения данных внутри системы. Без логического обоснования и понимания участники проекта, не обладающие техническими знаниями, могут не понимать, как входные данные становятся выходными данными.
Символика диаграмм потоков данных
Существует набор стандартизованных символов для иллюстрации компонентов диаграммы потоков данных. Использование этих единых условных обозначений позволяет всем членам команды без труда читать и понимать любые такие диаграммы.
Внешний объект
Внешние объекты — это акторы, источники, приемники и ограничители. Эти существующие за пределами системы компоненты отправляют данные в систему или получают их из нее. Как правило, внешние объекты — это источники и пункты назначения входных и выходных данных системы.
Процесс
Компонент «процесс» — это то, что преобразует поступающие данные в пригодные для использования выходные данные.
Хранилище данных
Компонент «хранилище данных» — это то, что обеспечивает хранение данных в системе. Как правило, эти компоненты представляются в виде файлов.
Потоки данных
Компоненты «потоки данных» — это пути, по которым данные перемещаются в системе. На диаграмме эти компоненты, как правило, представляются в виде стрелок и соединительных линий.
Создать диаграмму потоков данных →
Диаграммы потоков данных и UML
Прежде чем рассмотреть типы диаграмм потоков данных, давайте поговорим о том, как эти диаграммы соотносятся с миром унифицированного языка моделирования (UML). Диаграммы UML и диаграммы потоков данных выглядят подобными друг другу, однако между ними есть ряд ключевых отличий.
UML — это язык моделирования, используемый в разработке объектно-ориентированного программного обеспечения. Так, разработчики программного обеспечения используют язык UML для подробного описания процесса и разъяснения того, как выполняется разработка программного обеспечения. Существует 14 официальных типов диаграмм UML.
Диаграммы потоков данных, с другой стороны, отображают перемещение данных внутри системы. Они могут напоминать диаграммы UML, однако не служат для подробного описания программной логики. При использовании UML диаграмма деятельности может быть более полезной по сравнению с диаграммой потоков данных. Это обусловлено тем, что диаграмма потоков данных — это графическое представление перемещения данных в пределах системы. В шаблоне UML-диаграммы деятельности последовательность действий отображается аналогично пути перемещения данных в системе.
Уровни диаграмм потоков данных
Диаграммы потоков данных имеют многоуровневую организацию. Каждый уровень диаграммы уходит глубже и становится более сложным, поскольку отражает конкретный фрагмент системы или данных. Уровни диаграммы потоков данных обычно обозначаются от Уровня 0 до Уровня 2, а в некоторых особенно сложных системах диаграмма может уходить на еще более низкий Уровень 3. Уровень детализации, который вы хотите проанализировать, определяет глубину диаграммы.
Уровень 0 диаграммы потоков данных
Уровень 0 обычно является контекстным уровнем диаграммы потоков данных . Это диаграмма отражает общую картину и не содержит какой-либо конкретной части системы. Уровень 0 представляет собой простую схему потоков данных, используемую для формирования общего представления о системе, размещения ее в контексте и отображения единственного процесса высокого уровня.
Уровень 1 диаграммы потоков данных
Уровень 1 предполагает более высокую степень детализации и специализации схемы. На Уровне 1 обозначаются основные функции в рамках процесса или системы. Именно на Уровне 1 диаграммы потоков данных конкретные разделы обзорного Уровня 0 начинают детализироваться и поясняться.
Уровень 2 диаграммы потоков данных
Уровень 2 уходит еще глубже: его используют для отображения и анализа конкретных разделов диаграммы Уровня 1. Чем ниже уровни, тем больше текстовой информации появляется на диаграмме. По этой причине многие разработчики систем предпочитают не уходить ниже Уровня 2. Однако в случае некоторых очень сложных систем может возникнуть необходимость углубиться еще на один или два уровня.
Типы диаграмм потоков данных
Диаграммы потоков данных делятся на две категории в зависимости от типа визуализируемых потоков. Диаграмма потоков данных может быть логической либо физической. Каждый подтип имеет свое назначение и свои преимущества.
Логическая диаграмма потоков данных
Логические диаграммы потоков данных в большей степени обращены на деятельность и процессы внутри компании. Они отвечают на вопрос «Что?» и представляют его графически. Логические диаграммы потоков данных демонстрируют, чем занимается компания, что она предоставляет и к чему стремится.
Они описывают деловые мероприятия, а также информацию и данные, необходимые для проведения этих мероприятий. Логическая диаграмма потоков данных полезна тем, что отображает деловой процесс. Она помогает понять типы имеющихся и желаемых функциональных возможностей компании.
Физическая диаграмма потоков данных
Физическая диаграмма потоков данных графически представляет реализацию бизнес-систем. В противоположность вопросу «Что?», она отвечает на вопрос «Как?». Физическая диаграмма показывает, как данные перемещаются в пределах системы и как система функционирует. Диаграмма потоков данных этого типа включает такие элементы, как файлы, программное и аппаратное обеспечение системы.
Физические и логические диаграммы потоков данных позволяют с разных сторон взглянуть на одни и те же потоки данных. Их можно использовать совместно для целостного понимания всего процесса.
Создать диаграмму потоков данных →
Когда используются диаграммы потоков данных
Диаграммы потоков данных первоначально использовались для демонстрации потоков данных в компьютерной системе. Однако сегодня они используются на разных этапах продумывания идей и разработки в самых разных отраслях. Они особенно полезны компаниям, деятельность которых в значительной степени зависит от данных и информации. Ниже приведены примеры сфер применения диаграмм потоков данных.
Разработка программного обеспечения
Программисты используют схемы потоков данных для разработки основ и архитектуры программного обеспечения, до перехода к этапу написания кода. Такие диаграммы также полезны в качестве инструмента непрерывного системного анализа в целях оценки хода развития и внедрения усовершенствований системы.
Управление предприятием
Руководство должно полностью понимать процессы, обеспечивающие успех компании. Схемы потоков данных являются ценным инструментом планирования Agile-процессов и общего налаживания процессов внутри компании. Они могут использоваться для оптимизации повседневно используемых систем и рабочих процессов компании.
Разработка баз данных
В нашу цифровую эру почти у любого бизнеса есть онлайн-компонент, который полагается на сложную структуру базы данных, хранящей пользовательские данные. Диаграммы потоков данных помогают спланировать и разметить перемещение и хранение данных в онлайн-базах данных. В мире, где критически важны информационная безопасность и защита данных, диаграммы потоков данных помогают определить правильный путь для разработчиков и компаний.
Как создать диаграмму потоков данных
Теперь, имея представление о том, что собой представляют и где используются схемы потоков данных, можно приступать к построению собственной схемы. Ниже приведено удобное пошаговое руководство по созданию комплексной диаграммы потоков данных с помощью предлагаемого Miro шаблона диаграммы потоков данных .
Шаг 1
Начните с сортировки входных и выходных данных. Каждый процесс, который будет отражен на диаграмме, должен иметь как минимум по одному входу и выходу данных. Это обеспечит полноту диаграммы потока данных и отсутствие у нее свободных концов.
Шаг 2
Начните построение диаграммы с Уровня 0, чтобы сформировать общее представление о контексте системы. Такое общее представление позволит оценить необходимость в более подробном отображении системы на более глубоких уровнях.
Шаг 3
Перейдите на Уровень 1. На этом уровне можно добавлять детали к общей структуре. В ходе построения Уровня 1, по мере перевода внимания на отдельные системы в рамках компании, можно добавлять к структуре все больше процессов и этапов. Не забывайте о необходимости использовать описанные выше стандартизованные символы и фигуры диаграмм потоков данных.
Шаг 4
Повторяйте Шаг 3 и переходите к более глубоким уровням каждый раз, когда хотите сосредоточиться на конкретной системе или процессе. Ограничений по количеству добавляемых уровней нет. Но помните: диаграмма должна быть удобной для восприятия. Поделитесь диаграммой с членами команды и предложите им оставлять отзывы, задавать вопросы и выдвигать предложения. Miro позволяет без лишних усилий организовать совместную работу с командой на общем холсте в реальном времени.
Создайте схему потоков данных в Miro
В первый раз создание диаграммы потоков данных может показаться сложным, однако наличие шаблона значительно облегчает задачу. Использование шаблона схемы потоков данных позволит значительно сократить трудоемкие начальные этапы разработки и планирования, чтобы можно было сосредоточиться на создании эффективно работающей диаграммы. Этот простой в использовании шаблон станет надежной основой для добавления информации о проекте и построения диаграммы. Его коммуникативные свойства, такие как возможность делиться с командой и оставлять комментарии, делает его идеальным решением для вашей компании.
Источник: miro.com
Поток данных: назначение, виды, характеристика

Наш мир просто не может обойтись без большого количества данных. Они передаются между различными объектами, и если этого не будет, то это означает только одно – человеческая цивилизация перестала существовать. Поэтому давайте рассмотрим, что собой представляет поток данных, как им можно управлять, где он хранится, каковы его объемы и много другое.
Вводная информация
В первую очередь нам необходимо разобраться с терминологией. Поток данных – это целенаправленное перемещение определенной информации. В качестве конечного пункта назначения могут быть широкие массы населения (телевизор), электронно-вычислительные машины (Интернет), ретранслятор (радиосвязь) и так далее. Различают различные виды потоков данных.
Их классификация может проводиться на основании используемых средств (телефон, Интернет, радиосвязь), мест применения (компания, собрание людей), целевого назначения (гражданские, военные). Если интересует их иерархия, функциональные процессы, связанные элементы, то строится диаграмма потоков данных (ДПД).
Она необходима для отслеживания движений, а также демонстрации того, что каждый процесс при получении определенной входной информации обеспечивает закономерные выходные результаты. Для отображения этого положения можно построить нотации, соответствующие методам Гейна-Сэрсона и Йордона де Марко. В целом модель потоков данных ДПД позволяет разбираться с внешними сущностями, системами и их элементами, процессами, накопителями и потоками. Ее точность зависит от того, насколько достоверна имеющаяся исходная информация. Ибо если она не соответствует действительности, то даже самые совершенные методы не смогут помочь.
О размерах и направлениях

Информационные потоки данных могут быть разного масштаба. Он зависит от множества факторов. Например, взять обычное письмо. Если написать самую что ни есть заурядную фразу: «Сегодня хороший и солнечный день», то занимает она не так уж и много места. Но вот если закодировать ее в двоичный код, понятный компьютеру, то она займет явно не одну строку.
Почему? Для нас фраза «сегодня хороший и солнечный день» закодирована в понятную и не вызывающую вопросов форму. Но вот компьютер воспринимать ее не может. Он реагирует только на определенную последовательность электронных сигналов, каждый из которых отвечает нулю или единице.
То есть, компьютеру воспринять эту информацию невозможно, если она не будет преобразована в понятную ему форму. Поскольку минимальное значение, которым он оперирует, является восьмиразрядный бит, то закодированный данные будут выглядеть таким образом: 0000000 00000001 00000010 00000011… И это только первые четыре символа, которые условно значат «сего».
Поэтому обработка потока данных для него является хотя и возможным, но специфическим занятием. И если бы люди общались таким образом, то не сложно представить, какими бы огромными были бы наши тексты! Но здесь есть и обратная сторона: меньший размер. Что под этим подразумевается?
Дело в том, что компьютеры, несмотря на то что они, на первый взгляд, работают неэффективно, для всех изменений отводят очень мало места. Так, для изменения определенной информации необходимо только целенаправленно поработать с электронами. И содержимое техники будет зависеть от того, на каком месте они находятся.
Благодаря малому размеру, несмотря на кажущуюся неэффективность, компьютер может вместить в себе значительно больше информации, нежели лист или соразмерная жесткому диску книга. В тысячи, а то и миллионы раз! И объем потока данных, которые он может пропускать через себя, вырастает до ошеломительных значений. Так, чтобы просто написать все двоичные операции, осуществленные одним мощным сервером за секунду, у обычного человека могут уйти годы. А ведь там может быть высококачественная графическая эмуляция, множество записей об изменениях на бирже и множество иной информации.
О хранении

Ясное дело, что потоками данных все не ограничивается. Они идут от своих источников к получателям, которые могут просто ознакомиться с ними или даже сохранить их. Если говорить о людях, то важное мы старается сберечь в нашей памяти для воспроизведения в дальнейшем. Хотя это не всегда получается, да и запомниться может что-то нежелательное.
В компьютерных сетях здесь на помощь приходит база данных. Поток информации, передаваемой по каналу, обычно обрабатывается системой управления, которая и решает, что и куда записывать в соответствии с полученными инструкциями.
Такая система, как правило, на порядок более надежная, нежели человеческий мозг, и позволяет уместить много содержимого, легко доступного в любой момент времени. Но и здесь не обойтись без проблем.
В первую очередь не нужно забывать о человеческом факторе: кто-то пропустил инструктаж по безопасности, системный администратор не с должным рвением отнесся к своим обязанностям и все – система вышла из строя. Но может быть и банальная ошибка потока данных: нет нужного узла, не работает шлюз, неправильный формат и кодировка передачи данных, и множество иных. Даже возможен элементарный сбой информационной техники. Например, установлен порог, что на девять миллионов операций, осуществляемых компьютером, должно быть не более одной ошибки выполнения. На практике их частотность значительно меньше, возможно даже достигает значение одно на миллиарды, но, тем не менее, они все же есть.
Анализ
Обычно потоки данных существуют не сами по себе. Кто-то заинтересован в их существовании. И не просто в одном факте, чтобы они были, а еще управлении ними. Но это, как правило, не предоставляется возможным без предшествующего анализа. А для полноценного изучения существующей ситуации одного только изучения сложившегося положения может быть недостаточно.
Поэтому обычно анализируются все система, а не только одни потоки. То есть отдельные элементы, их группы (модули, блоки), взаимосвязи между ними и так далее. Анализ потока данных хоть и является при этом неотъемлемой частью, но в отдельности не проводится из-за того, что полученные результаты являются слишком уж оторванными от целостной картины.
При этом часто осуществляется перестановка сущностей: некоторые внешние рассматриваются как часть системы, а ряд внутренних выносится за рамки интереса. При этом исследование обладает поступательным характером. То есть, оно сначала рассматривается всей системой, потом она разделяет его на составляющие части, и только затем идет определение потоков данных, с которыми приходится иметь дело. После того как все тщательно проанализировано, можно решать вопросы с управлением: куда, что, в каком количестве будет идти. Но это целая наука.
Что собой представляет управление потоком данных?

По сути, это возможность направлять их определенным получателям. Если говорить про отдельных людей, то здесь все очень просто: информация, которая есть у нас, управляется нами же. То есть мы решаем, что говорить, а о чем промолчать.
Управление потоком данных с позиции компьютерной техники – это не так же легко. Почему? Для того чтобы сообщить другому человеку определенную информацию, достаточно открыть рот и напрячь голосовые связки. Но технике такое недоступно. Здесь управление потоком данных является делом сложным.
Вспомним об уже упомянутой заурядной фразе: «Сегодня хороший и солнечный день». Все начинается с ее перевода в двоичный код. Затем необходимо установить связь с маршрутизатором, роутером, коннектором или другим устройством, нацеленным на полученные данных. Имеющуюся информацию необходимо закодировать, чтобы она приняла такую форму, которая может передаваться.
Например, если планируется пересылка файла по мировой Сети из Беларуси в Польшу, то он разбивается на пакеты, которые затем и отправляются. Причем идут не только наши данные, но и множество иных. Ведь средства пересылки и кабели передачи всегда одни и те же.
Укрывающая мир сеть потоков данных позволяет получать информацию чего угодно из любой точки мира (при наличии необходимых средств). Управлять таким массивом – дело проблематичное. Но вот если речь идет об одном предприятии или провайдере, то это уже совсем иное. Но в таких случаях под управлением обычно понимают только то, куда направлять потоки, и нужно ли их пропускать вообще.
Моделирование

Говорить о том, как работает поток передачи данных в теории – это дело несложное. Но не всем может быть понятно, что он собой представляет. Поэтому давайте рассмотрим пример и смоделируем возможные сценарии.
Допустим, что есть определенное предприятие, на котором существуют потоки данных. Они для нас представляют наибольший интерес, но сначала необходимо разобраться с системой. В первую очередь следует вспомнить о внешних сущностях. Они являются материальными объектами или физическим лицами, которые выступают в роли источников или приемников информации.
В качестве примера можно привести склад, клиентов, поставщиков, персонал, заказчиков. Если определенный объект или система определяются как внешняя сущность, то это говорит о том, что они находятся за пределами анализируемой системы. Как уже ранее говорилось, в процессе изучения некоторые из них могут переноситься вовнутрь и наоборот.
На общей схеме ее можно изобразить в виде квадрата. Если строится модель сложной системы, то ее можно представить в самом обобщенном виде или декомпозировать на ряд модулей. Их модуль служит для идентификации. Размещая справочную информацию, лучше ограничиться наименованием, критериями определения, дополнениями и входящими элементами. Также выделяются процессы.
Их работа осуществляется на основе входящих данных, поставляемых потоками. В физической реальности это может быть представлено как обработка получаемой документации, принятие заказов к исполнению, получение новых конструкторских разработок с их последующей реализацией. Все получаемые данные должны использоваться для запуска определенного процесса (производства, контроля, корректировки).
И что же дальше?
Нумерация используется для идентификации. Благодаря ей можно узнать то, какой поток, откуда, зачем и как дошел и запустил определенный процесс. Иногда информация выполняет свою роль, после чего уничтожается. Но это не всегда. Часто она направляется для хранения на накопитель данных.
Под этим подразумевается абстрактное устройство, пригодное для хранения информации, которая может быть в любой момент времени извлечена. Более продвинутая его версия идентифицируется как база данных. Хранящиеся в ней сведения должны соответствовать принятой модели.
На поток данных возлагается определение информации, которая будет передана через конкретное соединение от источника к получателю (приемнику). В физической реальности он может быть представлен в виде электронных сигналов, передаваемых по кабелям, идущими по почте письмами, флешками, лазерными дисками. При построении схематического рисунка для указания направления потока передачи данных используется символ стрелочки. Если они идут в обе стороны, то можно просто провести линию. Или с помощью стрелочек указать, что данные передаются между объектами.
Построение модели

Главная преследуемая цель – это описать систему понятным и ясным языком, уделяя внимание всем уровням детализации, в том числе и при разбивке системы на части с учетом отношений между разными составляющими. На этот случай предусмотрены такие рекомендации:
- Размещать на каждой части не меньше трех и не более семи потоков. Такая верхняя граница установлена в связи с ограничениями возможности одновременного восприятия одним человеком. Ведь если рассматривается сложная система с большим количеством связей, то в ней будет сложно сориентироваться. Нижняя граница установлена, исходя из здравого смысла. Ибо проводить детализацию, на которой будет изображен только один поток данных, нерационально.
- Не загромождать пространство схемы несущественными для данного уровня элементами.
- Декомпозицию потоков следует проводить вместе с процессами. Эти работы должны идти одновременно, а не в порядке очереди.
- Для обозначения следует выделять ясные, отражающие суть имена. Аббревиатуры желательно не использовать.
При изучении потоков следует помнить, что разобраться со всем нахрапом возможно, но лучше сделать все аккуратно и в лучшем виде. Ведь даже если человек, составляющий модель, все понимает, то он ее делает, почти наверняка, не для себя, а для других людей. И если руководитель предприятия не сможет понять, о чем же идет речь, то весь труд будет напрасен.
Специфические моменты моделирования

Если создается сложная система (то есть такая, в которой есть десять и более внешних сущностей), то не лишним будет создать иерархию контекстных диаграмм. При этом на верхушку следует размещать не самый главный поток данных. А что же тогда?
Лучше подойдут подсистемы, в которых есть потоки данных, а также указать на связи между ними. После того как модель создана, ее необходимо верифицировать. Или иными словами – проверить на полноту и согласованность. Так, в завершенной модели все объекты (подсистемы, потоки данных, процессы) должны быть детализированы и подробно описаны. Если были выявлены элементы, в отношении которых эти действия не выполнены, то необходимо вернуться на предыдущие шаги разработки и устранить проблему.
Согласованные модели должны обеспечивать сохранность информации. Иными словами, все поступающие данные считываются, а затем записываются. То есть когда моделируется ситуация на предприятии и если что-то осталось неучтенным, то это говорит о том, что работа выполнена некачественно.
Поэтому чтобы не испытывать подобных разочарований, существенное внимание необходимо уделять подготовке. Нужно перед работой учесть структуру изучаемого объекта, специфику передаваемых в потоках данных и многое другое. Иными словами – следует строить концептуальную модель данных. В таких случаях выделяются связи между сущностями и определяются их характеристики.
При этом если что-то было взято за основу, то это не значит, что необходимо ухватиться и держаться за нее. При возникновении потребности концептуальную модель данных можно уточнить. Ведь главная преследуемая цель – это разобраться с потоками данных, установить, что и как, а не нарисовать красивую картинку и гордиться собой.
Заключение

Безусловно, рассматриваемая тема очень интересна. Одновременно она и очень объемная. Для ее полноценного рассмотрения одной статьи мало. Ведь если говорить про потоки данных, то только простой передачей информации между компьютерными системами и в рамках человеческого общения дело не ограничивается. Здесь можно выделить много интересных направлений.
Взять, к примеру, нейронные сети. Внутри них существует большое количество различных потоков данных, которые нам наблюдать очень сложно. Они обучаются, сопоставляют их, преобразовывают на свое усмотрение. Следует вспомнить еще одну связанную тему – Большие данные. Ведь они формируются благодаря получению различных потоков информации о множестве вещей.
К примеру, социальная сеть отслеживает привязанности человека, чему он ставит отметку «нравится», чтобы формировать список его предпочтений и предлагать более эффективную рекламу. Или рекомендовать вступление в тематическую группу. Как видите, вариантов использования и применения получаемых потоков данных и содержащейся в них информации много.
Источник: fb.ru