Когда элемент, определяющий значение InputOutputSpecification, готов к запуску выполнения посредством элементов Потока операций или События, на которое должна последовать реакция, входы заполняются данными, поступающими от соответствующих элементов, например, Объектов данных или свойств. Для отображения таких назначений служит Ассоциация данных.
Значение каждого их указанных элементов InputSet вычисляется согласно порядку, в котором эти элементы расположены в InputOutputSpecification.
Входные данные, на которые ссылается элемент InputSet, будут вычислены в случае, если они верны.
Все ассоциации данных будут вычислены в том случае, если они указывают вход данных в качестве цели. Если один из источников какой-либо ассоциации данных является недоступным, то значение InputSet также становится недоступным; при этом вычисляется значение следующего элемента InputSet.
Первый элемент InputSet, в котором все входные данные доступны для ассоциаций данных, используется для запуска выполнения Действия. Если же значения всех этих элементов недоступны, выполнение Действия не начнется до тех пор, пока не будет выполнено данное условие.
Значение слова семантика. Что такое семантика.
Данная спецификация не содержит информацию о том, когда и как часто должно проверяться это условие. Выполнение не будет осуществляться до тех пор, пока источники ассоциаций данных не станут доступны, после чего произойдет повторное вычисление значений элементов InputSets.
Если в состав Потока операций включено Событие, реагирующее на триггер или определяющее результат, семантика исполнения для данных будет отличаться.
Если запущено определяющее результат Событие, то будут задействованы все элементы DataInputAssociation данного События; при этом произойдет наполнение входов данного События данными. Затем элементы DataInput копируются в объекты, запущенные вышеуказанным Событием (Сообщением, Сигналом и т.д.). Поскольку для События не определены элемены InputSets, то и выполнение никогда не будет ждать удовлетворения каких-либо условий.
Если запущено реагирующее на триггер Событие, то выходы данного События заполняются объектом, запустившим данное Событие; при этом задействованы все элементы DataOutputAssociations События. Элементы OutputSets для этого События не определяются.
Для того, чтобы сделать возможным запуск Процесса посредством Действия Вызов и Потока сообщений, Стартовое и Конечное события используются одинаково.
При использовании Стартового события входные данные содержащего его Процесса доступны элементам DataOutputAssociations События как цели. Таким образом, входы Процесса могут быть заполнены элементами, запустившими Стартовое событие.
При использовании Конечного события выходные данные содержащего его Процесса доступны элементам DataInputAssociations События как источники. Таким образом, результирующие элементы Конечного события в качестве источников могут использовать входные данные Процесса.
Если хотя бы один раз элемент InputSet стал доступным, то происходит выполнение всех Ассоциаций данных, целью которых является любые входные данные элемента InputSet. Благодаря этому, заполняются входы для данных Действия, при этом само Действие начинает выполняться. Когда выполнение Действия завершается, то происходит выполнение всех Ассоциаций данных, источниками которых являются любые выходные данные элемента OutputSet. Благодаря этому, значения выходных данных копируются обратно в элемент, содержащий данные (Объект данных, свойства и т.д.)
Дедукция 7. Синтаксис и семантика
Семантика исполнения для DataAssociation
Выполнение любого объекта Ассоциации данных ДОЛЖНО БЫТЬ произведено в соответствии со следующей семантикой исполнения:
- Если Ассоциация данных определяет выражение трансформации, то данное выражение вычисляется, а результат копируется в элемент targetRef. Благодаря этим действия, предыдущее значение этого элемента полностью заменяется.
- Для каждого элемента назначения необходимо выполнять следующие действия:
- Вычислить выражение «from» и получать *source value*.
- Вычислить выражение «to» и получать * target element *. В качестве элемента * target element * может использоваться любой соответствующий элемент или подчиненный ему элемент (например, Объект данных или подчиненный ему элемент).
- Скопировать *source value* в *target element*.
- Если в Ассоциации данных отсутствуют выражение трансформации либо элементы назначения, то:
- Скопировать значение элемента «sourceRef» Ассоциации данных в элемент «targetRef». В данном случае доступен лишь элемент sourceRef.
10.3.3 Использование данных в выражениях XPath
Механизм расширения BPMN позволяет использовать различные языки выражений и запросов. Данный раздел посвящен описанию использования XPath в BPMN: в нем представлен механизм доступа к Объектам данных, свойствам и другим атрибутам экземпляров через использование выражений XPath.
В языке выражений доступность подразумевает основанную на информации возможность доступа Действий, содержащих выражение. Все элементы, доступные из содержащего их элемента выражения XPath, ДОЛЖНЫ БЫТЬ доступны для XPath-процессора.
В BPMN Объекты данных и Свойства указываются посредством элемента ItemDefinition. Связь с XPath предполагает, что элемент ItemDefinition является либо сложным XSD типом, либо XSD элементом. Если используется XSD элемент, то он ДОЛЖЕН БЫТЬ заявлен как одноблочная (with a single member node) узловая переменная (node-set XPath variable). Если используется сложный XSD тип, то он ДОЛЖЕН БЫТЬ заявлен как одноблочная переменная node-set, содержащая безымянный элемент документа, в котором хранится текущее значение Объекта данных или Свойства BPMN.
Доступ к Объектам данных BPMN
Таблица 10.65 содержит информацию о функциях XPath, используемых для получения доступа к Объектам данных BPMN. Параметр processName указывает Процесс и имеет тип string (ОБЯЗАТЕЛЬНО literal string).
Таблица 10.65 – Функция расширения XPath для Объектов данных
Функция расширения XPath
Описание/использование
Element getDataObject (‘processName’, ‘dataObject- Name’)
Данная функция возвращает значение представленного Объекта данных. Параметр processName является опциональным. В случае, если он опущен, то Процесс, содержащий Действие с выражением, допускается. Для получения доступа к Объектам данных, указанным в родительском процессе, ДОЛЖЕН БЫТЬ использован параметр processName. В других ситуациях он ДОЛЖЕН БЫТЬ опущен.
Поскольку возврат отказа функциями XPath 1.0 не поддерживается, в случае ошибки возвращается пустой набор узлов.
Доступ к входам и выходам данных BPMN
Таблица 10.66 содержит информацию о функциях XPath, используемых для получения доступа к входам и выходам данных BPMN. Параметр dataInputName указывает вход данных и имеет тип string.
Таблица 10.66 – Функция расширения XPath для входа и выхода данных
Функция расширения XPath
Описание/использование
Element getDataInput (‘dataInputName’)
Данная функция возвращает значение представленного входа для данных.
Element getDataOutput (‘dataOutput- Name’)
Данная функция возвращает значение выхода для данных.
Доступ к Свойствам BPMN
Таблица 10.67 содержит информацию о функциях XPath, используемых для получения доступа к свойствам BPMN.
Параметр processName указывает Процесс и имеет тип string. Параметр propertyName указывает свойство и имеет тип string. Параметр activityName указывает Действие и имеет тип string. Параметр eventName указывает Событие и имеет тип string (ОБЯЗАТЕЛЬНО literal string). Функция расширения XPath возвращает значение представленного свойства.
Поскольку возврат отказа функциями XPath 1.0 не поддерживается, в случае ошибки возвращается пустой набор узлов.
Таблица 10.67 – Функция расширения XPath для входа и выхода данных
Функция расширения XPath
Описание/использование
Element getProcessProperty (‘processName’, ‘propertyName’)
Данная функция возвращает значение представленного свойства Процесса. Параметр processName является опциональным. В случае, если он опущен, то Процесс, содержащий Действие с выражением, допускается. Для получения доступа к свойствам, указанным в родительском процессе, ДОЛЖЕН БЫТЬ использован параметр processName. В других ситуациях он ДОЛЖЕН БЫТЬ опущен.
Element getActivityProperty (‘activityName’, ‘propertyName’)
Данная функция возвращает значение представленное свойство Действия.
Element getEventProperty ‘eventName’, ‘propertyName’)
Данная функция возвращает значение представленное свойство События.
Доступ к атрибутам экземпляров BPMN
Таблица 10.68 содержит информацию о функциях XPath, используемых для получения доступа к атрибутам экземпляров BPMN.
Параметр processName указывает Процесс и имеет тип тип string. Параметр attributeName указывает атрибут экземпляра и имеет тип string. Параметр activityName указывает Действие и имеет тип string (ОБЯЗАТЕЛЬНО literal string).
Эти функции возвращают значение представленного экземпляра Действия. Поскольку возврат отказа функциями XPath 1.0 не поддерживается, в случае ошибки возвращается пустой набор узлов.
Таблица 10.68 – Функции расширения XPath для атрибутов экземпляров
Функция расширения XPath
Описание/использование
Element getProcessInstanceAttribute (‘processName’,‘attributeName’)
Данная функция возвращает значение представленного атрибута экземпляра Процесса. Параметр processName является опциональным. В случае, если он опущен, то Процесс, содержащий Действие с выражением, допускается. Для получения доступа к атрибутам родительского процесса, указанным в родительском процессе, ДОЛЖЕН БЫТЬ использован параметр processName. В других ситуациях он ДОЛЖЕН БЫТЬ опущен.
Element getChoreographyInstance- Attribute (‘attributeName’)
Данная функция возвращает значение представленного атрибута экземпляра Хореографии.
Element getActivityInstanceAttribute (‘activityName’, ‘attributeName’)
Данная функция возвращает значение атрибута экземпляра Действия. Примерами такого Действия могут служить Пользовательская задача и цикл.
10.3.4 Представление XML-схемы для Данных
Таблица 10.69 – XML–схема для элемента Assignment
name=»assignment» type =»tAssignment» />
name=»tAssignment»>
name=»from» type =»tExpression» minOccurs =»1″ maxOccurs =»1″/>
name=»to» type =»tExpression» minOccurs =»1″ maxOccurs =»1″/>
Таблица 10.70 – XML–схема для элемента DataAssociation
Таблица 10.71 – XML–схема для элемента DataInput
Таблица 10.72 – XML–схема для элемента DataInputAssociation
Таблица 10.73 – XML–схема для элемента DataObject
name=»dataObject» type =»tDataObject» />
name=»tDataObject»>
base=»tFlowElement»>
ref=»dataState» minOccurs =»0″ maxOccurs =»1″/>
name=»itemSubjectRef» type =»xsd:QName»/>
name=»isCollection» type =»xsd:boolean»/>
Таблица 10.74 – XML–схема для элемента DataState
Таблица 10.75 – XML–схема для элемента DataOutput
Таблица 10.76 – XML–схема для элемента DataOutputAssociation
Таблица 10.77 – XML–схема для элемента InputOutputSpecification
Таблица 10.78 – XML–схема для элемента InputSet
minOccurs=»0″ maxOccurs=»unbounded»/>
minOccurs=»0″ maxOccurs=»unbounded»/>
minOccurs=»0″ maxOccurs=»unbounded»/>
minOccurs=»0″ maxOccurs=»unbounded»/>
Таблица 10.79 – XML–схема для элемента OutputSet
minOccurs=»0″ maxOccurs=»unbounded»/>
minOccurs=»0″ maxOccurs=»unbounded»/>
minOccurs=»0″ maxOccurs=»unbounded»/>
minOccurs=»0″ maxOccurs=»unbounded»/>
Таблица 10.80 – XML–схема для элемента Property
- Область действия документа
- Соответствие требованиям спецификации
- Нормативные ссылки
- Термины и определения
- Символы
- Дополнительная информация
- Общее представление
- Элементы BPMN
- Типы Диаграмм Бизнес-процессов (BPMN Diagram Types)
- Структура нотации BPMN
- Шлюзы (Gateways)
- Общие элементы (Common Elements)
- Обмен Сообщениями (Conversations)
- Взаимодействие (Collaboration)
- Процесс
- Процесс. Распределение ресурсов
- Процесс. Участие людей
- Процесс. Подпроцесс
- Процесс. Действие Вызов
- Процесс. Представление XML-схемы для Действий
- Процесс.Компоненты и Данные
- Процесс. Семантика исполнения для данных
- Процесс. Событие
- Процесс. Конечное событие
- Процесс. Элементы EventDefinition
- Процесс. Обработка Событий
- Процесс. Представление XML-схемы для пакета События
- Процесс. Шлюзы
- Процесс. Компенсация
- Процесс. Экземпляры Процесса, Немоделируемые Действия и Публичный Процесс
Источник: www.elma-bpm.ru
Исполняемая семантика бизнес-процессов
Такой вычислитель в англоязычной литературе обычно называют Workflow Engine (WE). Он полезен по следующим причинам.
- WE может вести параллельно несколько таких бизнес-процессов во времени. Это важно, так как работа с одним клиентом может откладываться, и нужно запоминать не только данные клиента, но также и состояние, в котором она отложена, чтобы при получении соответствующего события корректно возобновить работу — открыть перед продавцом-дизайнером нужные диалоговые окна, загрузить туда нужные данные и т. д.
- При переходе на следующий шаг WE, согласно спецификации бизнес-процесса, проверяет, что все условия завершения предыдущего шага были правильно выполнены. Разумеется, WE не может исправлять орфографические ошибки в выходных документах, но проверить, что каждый из требуемых документов создан, что все его графы заполнены и т. д., он вполне может, а это уже предотвращает многочисленные ошибки в делопроизводстве (например, продавец-дизайнер не может забыть создать или отдать клиенту список товаров).
- WE интегрирует в одну среду многочисленные программные приложения и базы данных, полезные для работы сотрудников компании.
- WE автоматически может выполнять многие шаги без участия человека, в нашем случае — сохранять и удалять проект, генерировать событие от таймера (по истечении десяти дней) и т. д. Разумеется, далеко не все действия бизнес-процесса могут быть полностью автоматизированы. Например, дизайн-проект создает человек, а не WE.
- Для сложных бизнес-процессов, в которых участвуют многие сотрудники, WE берет на себя все, связанное с коммуникациями — он рассылает необходимые уведомления о начале/конце соответствующего шага, пересылает запросы на данные и сами данные в ответ и т. д. При этом участники такого бизнес-процесса могут находиться в разных частях земного шара. Становится возможной виртуальная компания, для которой неважно, где физически расположены ее отдельные подразделения, — главное, чтобы все они были связаны сетью и компьютерами, оснащенными нужным программным обеспечением.
В итоге, как показано на рис. 9.3, WE оказывается ядром мощной системы автоматизации бизнеса компании. И программа, которую он выполняет, — это спецификация бизнес-процесса.

Рис. 9.3. Схема окружения автоматизированного бизнес-процесса
Рассмотрим, как WE может выполнять фрагмент бизнес-процесса покупки мебели, изображенный на рис. 9.2. Сразу после старта наш процесс начинает деятельность под названием «Создание дизайн-проекта». Например, открывается рабочее окно графического редактора, где создается дизайн-проект (это пример полезного ПО, которое может быть интегрировано с WE ). Выход из этого редактора может осуществляться с сохранением промежуточных результатов — проект еще не готов, процесс продолжает пребывать в состоянии «Создание дизайн-проекта», а продавец-дизайнер вместе с клиентом, например, пошли пить кофе. Второй вариант выхода из редактора — дизайн-проект готов. WEпредлагает продавцу-дизайнеру выбрать один из трех вариантов (в виде окошка со списком выбора):
- клиент готов заплатить;
- клиент заплатит позже;
- от клиента ожидается дополнительная информация.
Продавец-дизайнер выбирает тот ответ, который соответствует ситуации, и WE продолжает исполнять процесс.
Одними из самых распространенных WE являются ERP-системы. Кроме того, существует множество различных workflow-систем, которые умеют выполнять бизнес-процессы, определенные в той или иной формальной нотации, а также имеют различные интерфейсы — пользовательский, административный, программный (для подключения стороннего ПО) и т. д.
Источник: studfile.net
Автоматизации бизнес процессов компании в Trello с использованием технологии семантического моделирования
В последние годы все чаще говорят о Trello, как о прекрасном инструменте для организации и планирования. В нашей компании мы вот уже 3 года используем Trello для планирования многих процессов, начиная с отпусков, командировок и согласования договоров и заканчивая управлением проектами.
К сожалению, не все так прекрасно в Trello. На нем нельзя сделать кастомный workflow. То есть нам нужно занять одного сотрудника, который будет в различных досках перетаскивать карточки руками. Как же сделать так, чтобы этого сотрудника можно было перевести на другую, более интересную и творческую работу?
Конечно, скажете вы, можно написать скрипт, который будет делать все это за нас. Но тут возникает проблема. Скрипт может написать только программист или человек, который понимает, как это делать. Поддерживать скрипт придется ему же. Мы нашли более простое и логичное решение — это семантическое моделирование.
Семантическое моделирование позволяет всю логику работы доски в Trello записать на естественном языке.
Согласование командировок и отпусков
Возьмем самый простой процесс: согласование командировок и отпусков. По существующему у нас регламенту, каждый сотрудник, который планирует взять отпуск или отправиться в командировку, публикует заявку в Trello. Заявка попадает в лист raquo.
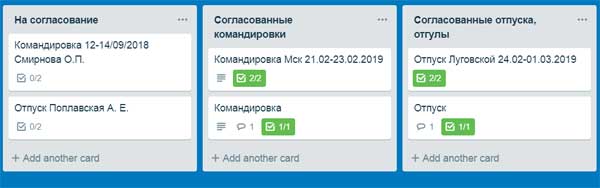
Как только заявка одобрена (фактически это означает, что руководитель сотрудника и/или представитель финансового отдела поставили галочку в нужный checkbox ), ее передвигают в лист raquo. Заявка на отпуск попадает соответственно в raquo и т.д. После этого нужно уведомить сотрудника, что его Заявка согласована.
Допустим, мы хотим автоматизировать этот процесс так, чтобы заявка после согласования перемещалась в нужный лист автоматически, а сотрудник получал уведомление об изменении статуса заявки. Рассмотрим, что нам для этого потребуется.
Необходимые инструменты
Для разработки модели мы выбрали ide от Jetbrains MPS (Meta Programming System). В качестве языка для моделирования используется язык d0SL — Delta0 semantic language, созданный на базе семантических (логических) моделей.
Весь процесс установки Jetbrains MPS и необходимых плагинов полностью описан здесь: https://d0sl.github.io/en/quick/installation/.
Установить готовую модель Trello доски можно по ссылке: https://d0sl.github.io/en/quick/trello/.
Семантическая модель. Что же получилось?
Посмотрим, как выглядит полученная семантическая модель Trello доски. В ней записаны наши правила:
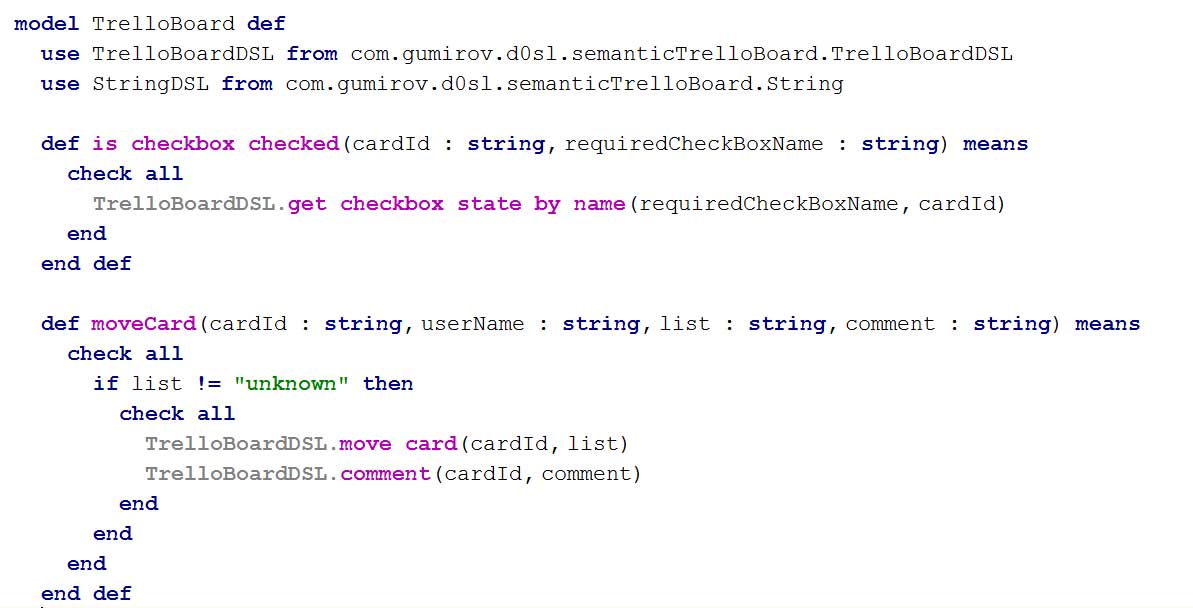
- Is checkbox checked — Проверяет, отмечен ли чекбокс с именем requiredCheckBoxName в карте с id cardId. Таким образом мы сможем проверить, одобрена ли наша Заявка или нет.
- moveCard — Перемещает карту cardId в list и добавляет в Заявку комментарий для пользователя
В модели есть предикат checkBoard, который вызывается для каждой карты в доске. Ему передается идентификатор карты, имя пользователя, совершившего последнюю операцию с картой, лист, из которого карту перемещали и лист, в котором она сейчас находится. Далее в checkBoard мы можем задать правила, по которым мы планируем обрабатывать наши заявки.

Заметим, что cемантическое моделирование позволяет вынести все логические бизнес-правила в один документ и написать эти правила на языке предметной области, «родном языке» для пользователей модели.
Возможность сделать что-либо с картой предоставляет базовая модель TrelloBoard, которая выглядит следующим образом:

Если мы запустим модель, то как только заявка в листе raquo пройдет процесс согласования,

Система переместит ее в соответствующий раздел и уведомит создателя карты об изменении статуса заявки.

Если же заявку, которая не была согласована, попытаться переместить вручную, система отправит ее на место и напишет гневный комментарий.
А что под капотом?
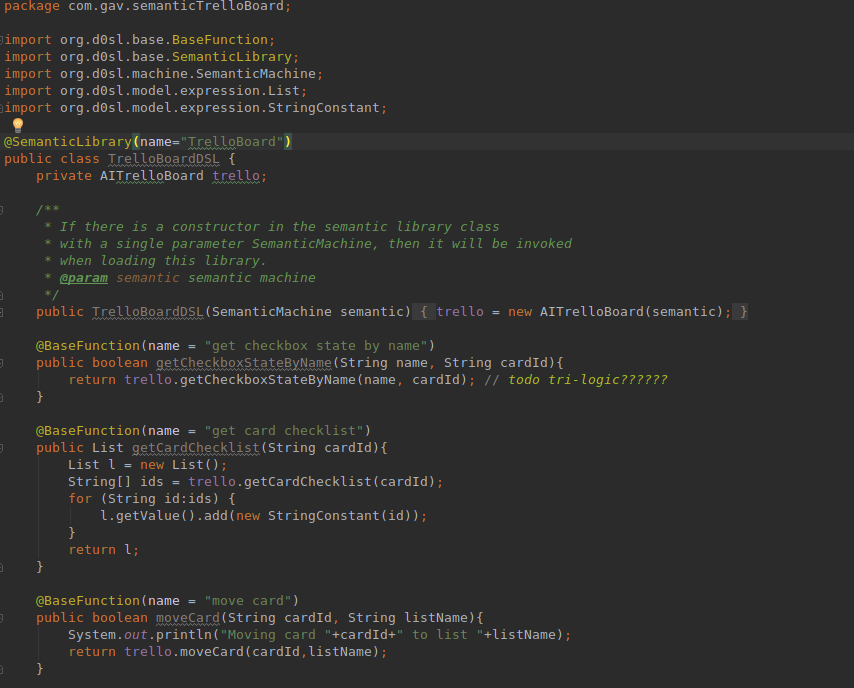
Базовая модель TrelloBoard по сути является интерфейсом, который мы имплементируем в Java (в данном случае в классе com.gav.semanticTrelloBoard.TrelloBoardDSL).
Выглядит это так: