Всем привет! Меня зовут Окунева Полина, я ведущий аналитик компании GlowByte команды Advanced Analytics. Сегодня я хочу рассказать о задаче Uplift-моделирования — частном случае такой большой сферы, как Causal Inference, или причинно-следственный анализ, — и методах её решения. Задачи такого типа важны во многих областях.
Если вы сотрудник, например, продуктовой компании, то причинно-следственный анализ поможет сократить издержки на коммуникации с людьми, на которых она не повлияет. Если вы врач, то такой анализ подскажет, выздоровел пациент благодаря лекарству или из-за удачного стечения обстоятельств.
Какого-то полноценного гайда по продвинутым методам Uplift-моделирования я не встретила ни в русско-, ни даже в англоязычном интернете, поэтому было огромное желание структурировать информацию и поделиться ею с интересующимися.
Я предполагаю, что все, кто зашел на эту страничку, априори знакомы с постановкой задачи Uplift-моделирования и его базовыми методами. Подробно на этих методах останавливаться не будем, т. к. информации о них существует достаточно много. В частности, можно изучить цикл статей от коллег из МТС Туториал по Uplift-моделированию. Часть 1 или перейти на мой доклад в сообществе NoML, где я очень подробно рассказываю про проблематику задачи Uplift-моделирования, методы её решения и затрагиваю тему тестирования моделей.
На текущий момент существует несколько библиотек для Uplift-моделирования как на языке Python, так и на R:
- X-learner;
- Domain Adaptation Learner;
- R-learner;
- DR-learner;
- Doubly Robust Instrumental Variable (DRIV) learner.
- Stable unit treatment value assumption (SUTVA).
- Потенциальный результат от воздействия для любого сэмпла не зависит от воздействий, произведённых на другие сэмплы.
- Не существует различных уровней воздействия, ведущих к различным результатам.
- Ignorability/unconfoundedness
- Для примеров с одинаковым набором фичей распределение по вариантам воздействия T, или тритмента, не зависит от потенциального результата.
- Positivity
- Условная вероятность каждого значения воздействия T строго положительна:
Метод реализован в библиотеке EconML.
Его также можно представить в виде последовательности из трёх шагов:
Шаг 1. Здесь, аналогично X-learner, строим две независимые модели на контрольной и тестовой группах.
Однако, в отличие от X-learner, уже на этом этапе в моделях идёт учёт propensity score в расчете весов каждого сэмпла — модели должны уметь принимать веса на вход.
Для контрольной группы веса рассчитываются по формуле:
Для тестовой:
Хочу обратить внимание на одну важную особенность на примере контрольной группы. Всё, рассказанное мной ниже, очевидно из формулы, но, если не заострить внимание, то можно этот момент пропустить.
Напомню, propensity score model рассчитывает вероятность того, что объект принадлежит к тестовой группе. А теперь посмотрим на формулу (3) и место, где применяются веса — (1). При построении модели на
контрольной
группе больший вес будет отдаваться тем сэмплам, для которых вероятность принадлежать к
тестовой
группе выше. Т. е. больший вес присваивается тем объектам, которые скорее всего лежали бы в противоположной группе.
Ровно такие же рассуждения можно провести для построения модели по данным тестовой группы: больший вес отдается тем элементам, которые наиболее вероятно, опираясь на их фичи, лежали бы в контрольной группе.
Далее всё как в X-learner.
Шаг 2. Считаем разности (Uplift)
Шаг 3. Строим модель прогноза эффекта по ковариатам сэмпла
В итоге видим, что финальная модель прогнозирует на выходе сам Uplift.
R-learner
Прежде чем перейти к самой модели, мы пробежимся немного по теоретической части.
Вначале введём определения двух функций:
— уже знакомая нам propensity score model,
— функция, выражающая математическое ожидание целевой переменной при фиксированных ковариатах для каждого из вариантов воздействий.
Обозначим через
разность между реальным значением, которое мы имеем с эксперимента, и спрогнозированный значением целевой переменной (с учётом описанных выше моделей):
Т. к. предполагается выполнение свойства unconfoundedness (его определение можно найти в начале статьи), то:
Далее введём следующее обозначение:
Отличие между выражениями
и
заключается в следующем: в выражении
используется переменная t — реальный факт воздействия или его отсутствия, в выражении
подставляется результат функции ϵ(x). Т. е., несмотря на то, что объект, например, был в контрольной группе, значение ϵ(x) могло быть близко к 1.
Рассчитаем разность, где выражение для
возьмём из
, а
из
:
Сократив все одинаковые слагаемые, придём к следующему выражению:
Все так же, исходя из допущения unconfoundedness, мы понимаем, что функция
должна быть такой, чтобы минимизировать выражение:
Чтобы оптимизатор мог корректно работать, сделаем функцию выпуклой и не зависящей от знака выражения. Стандартно это делается следующим образом:
Добавив регуляризационный член и перейдя к конкретному решению задачи, имеем выражение:
Теперь перейдём непосредственно к самому алгоритму R-learner, который реализован в CausalML.
Шаг 1. Задача аппроксимации.
Разделяем данные на несколько фолдов и строим функции с кросс-валидацией по всем фолдам.
- На первой части строится модель propensity score model.
- На второй части данные разделяем на подсэмплы — контрольная и тестовая группы, и на каждой из подчастей строится своя прогнозная модель (outcome regression model), которая предсказывает целевую переменную.
- Третья часть на Шаге 1 остается незадействованной
Doubly Robust Instrumental Variable (DRIV) learner
- Eсть возможность управлять данными, и в таком случае подбираются подходящие данные к методу. Например, частным случаем являются A/B тесты, в которых очень важным пунктом является разделение на сопоставимые группы.
- Данными управлять не представляется возможным, и идёт подбор метода к данным. Именно здесь и применяется Uplift-моделирование. Частью таких методов являются те, что были рассмотрены в статье выше. Их ключевой особенностью является участие во всех них propensity score model. Именно с помощью этой функции происходит учёт смещения при определении объекта (в момент эксперимента) к той или иной группе — контрольной или тестовой.
Источник: glowbyteconsulting.com
Главное с секции Trust/Experience/Sales Uplift — новые роли ТВ в омниканальном мире
Что рекламодатели обычно ждут от телевидения? Охваты, построение знания и лояльность аудитории. Однако в последнее время бренды все чаще говорят о том, что ТВ нужен performance. Куда движется рынок, эксперты обсудили на секции НРА, прошедшей в рамках «Дня Бренда»
Модератор: Алексей Толстоган, генеральный директор НРА
- Ольга Рублева, генеральный директор United Partners
- Денис Климанов, директор по стратегическому маркетингу и коммерческой эффективности НПФ «Материа Медика Холдинг»
- Николай Ануфриев, директор по закупкам OMD OM Group
- Сергей Белоглазов, Chief Operation Officer Publicis Groupe Russia
- Дарья Куркина, COO dentsu Russia
Доверие и эмоции
«Для телерекламы этот год обещает стать лучшим за все время существования НРА», — заявил Алексей Толстоган на прошедшей сессии. Телевидение достигло пика доверия у аудитории. Согласно последнему исследованию OMI, 47% опрошенных доверяют ТВ-рекламе нового бренда, и это самый высокий показатель для медиа. При этом у 62% большее доверие вызывает та реклама, которую потребители видели на ТВ и в интернете, а не только в digital-формате.

По словам генерального директора НРА, телереклама — мощный драйвер продаж, который влияет на рост всех метрик. Она обеспечивает значительный вклад в синергию медиамикса в краткосрочной и долгосрочной перспективе, и без ТВ другие каналы в медиамиксе теряют эффективность.
Пандемия запустила тренд на homing — стремление проводить как можно больше времени дома. И хотя локдауны частично закончились, тенденция сохранилась. Вместе с тем выросло потребление видеоконтента и количество платных подписок на сервисы, у многих потребителей их уже больше двух. Люди проводят много времени у экранов, что повышает эффективность ТВ.
Однако реклама должна быть оригинальной. Рынок заполнен одинаковыми брендами, и компаниям пора научиться вдохновлять и вовлекать свою аудиторию, если они хотят драйвить бренд-метрики. Тогда реклама на ТВ будет эффективной — 58% опрошенных признают, что телереклама вызывает у них самые сильные эмоции среди других других медиа.
Омниканальность
«Омниканальность — новая реальность для брендов. Такой подход существенно повышает Lifetime Value и обеспечивает рост всех метрик. Повышается частота физических посещений магазинов, средняя стоимость чека и лояльность клиентов», — отмечает генеральный директор United Partners Ольга Рублева.
Количество цепочек конверсии с привлечением исключительно performance — редкость и составляет не более 1%. Перед совершением целевого действия человек все равно контактирует с брендом множество раз — через телерекламу, OOH, радио и онлайн. При этом покупка контактов на ТВ обойдется дешевле, чем в performance.
Брендам важно выйти в top of mind в своей категории, чтобы не платить за лишний контакт, и телевидение здесь выигрывает из-за низкой стоимости охвата для широких аудиторий. Однако при работе с категориями 25–44 года стоимость ТВ и digital выравнивается.
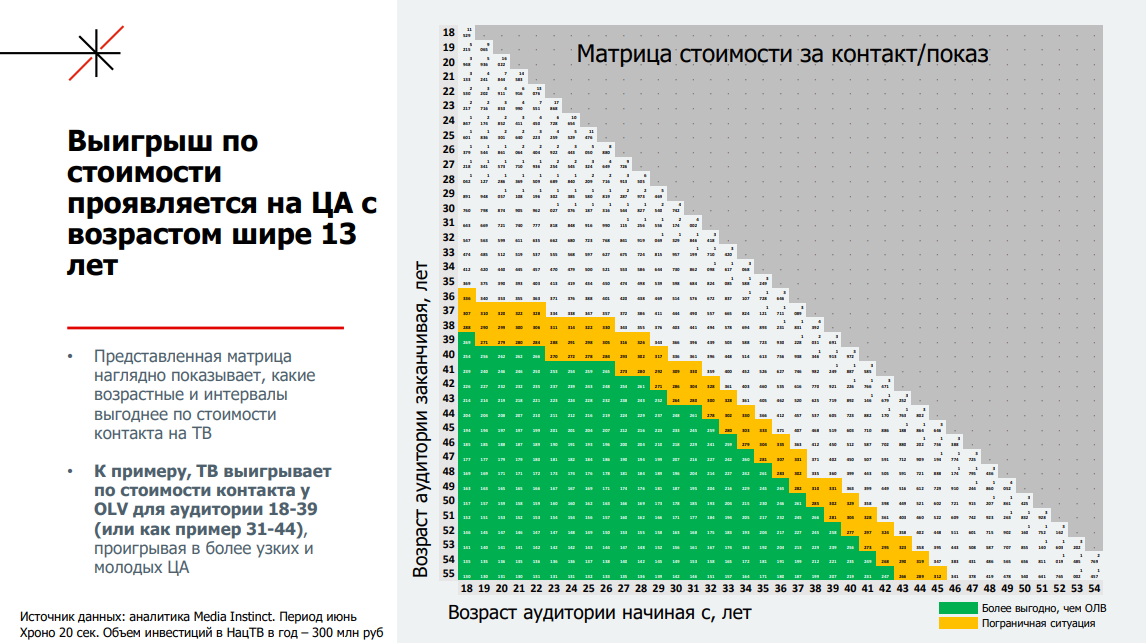
Говоря о преимуществах digital, Ольга Рублева отметила, что наиболее выгодной онлайн-реклама оказывается для узкосегментированной ЦА и при проверке гипотез в формате test and learn.
Кампании only digital имеют смысл при низких бюджетах или желании протестировать рекламный посыл, ведь цена ошибки в онлайне в разы меньше, чем на ТВ.
Клиентоцентричность
В период пандемии изменился баланс сил среди ключевых игроков рекламного рынка. Пандемия внесла коррективы в привычки клиентов, усилив одни бренды и ослабив другие. Сложившийся порядок останется с нами надолго, рассказал Денис Климанов, директор по стратегическому маркетингу и коммерческой эффективности НПФ «Материа Медика Холдинг».
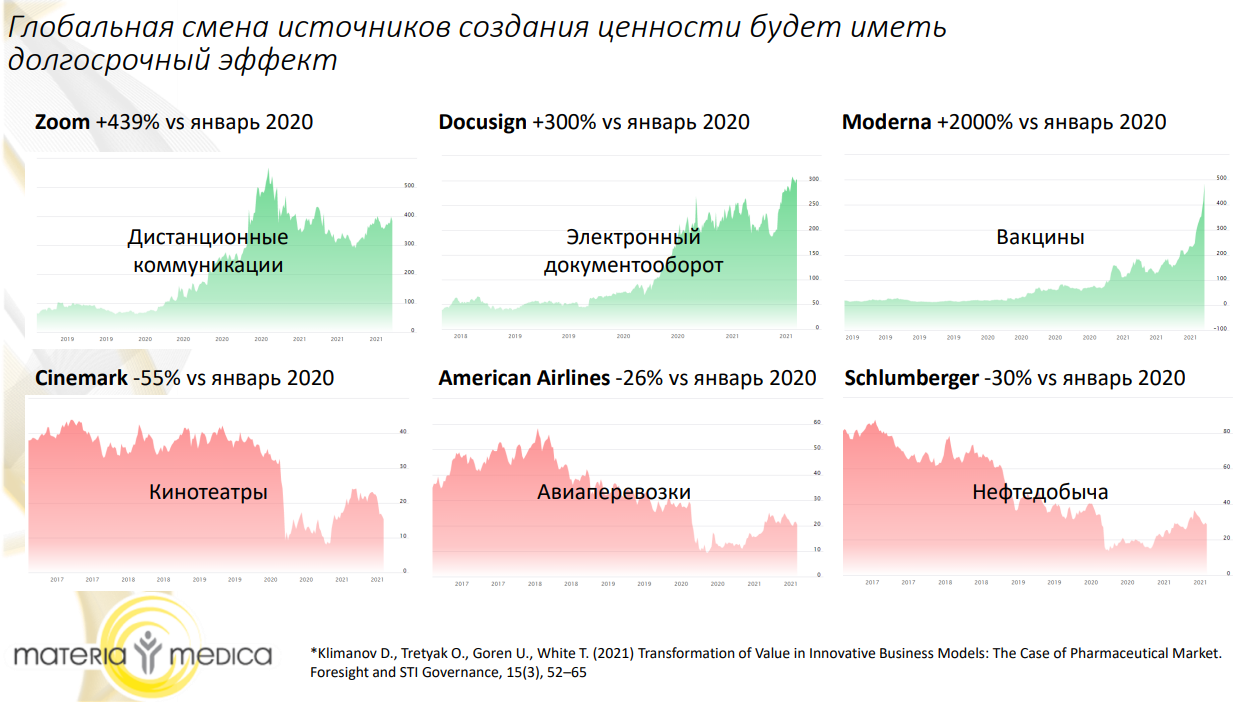
- Клиентоцентричность — это многомерный конструкт, который делится на пять блоков:
Базовые потребности клиентов. В эту группу входит качественная продукция, стабильные поставки, снижение издержек, скорость реакции на изменения и широта ассортимента. - Услуги для создания добавочной ценности. Важно понимать, что уникального делает бренд, что позволит ему выйти на новый уровень взаимодействия с аудиторией. Можно обращаться к новым каналам коммуникации (телемедицина, гибридный Salesforce) , внедрять каналы e-commerce и клиентские сервисы.
- Актуализация потребностей клиентов. Нужно держать руку на пульсе и понимать, что требуется каждой группе клиентов в конкретный момент.
- Фокус на «правильных» клиентах. Особое внимание стоит уделять клиентам, которые увеличивают свой вес на рынке. Брендам нужно обращаться к новым группам клиентов, чтобы усилиться в сравнении с конкурентами или старой версией самих себя.
- Организационная трансформация. Чтобы стать успешным, надо пробовать новое. «Материа Медика Холдинг» разрабатывает центр клиентского опыта, чтобы лучше понимать нужды всех клиентов и использовать это в своей бизнес-стратегии.
Если говорить конкретнее про рынок фармы, то здесь существует четыре фактора успеха: продукт, коммуникационные активы, активация в торговых точках и выбор медиастратегии.
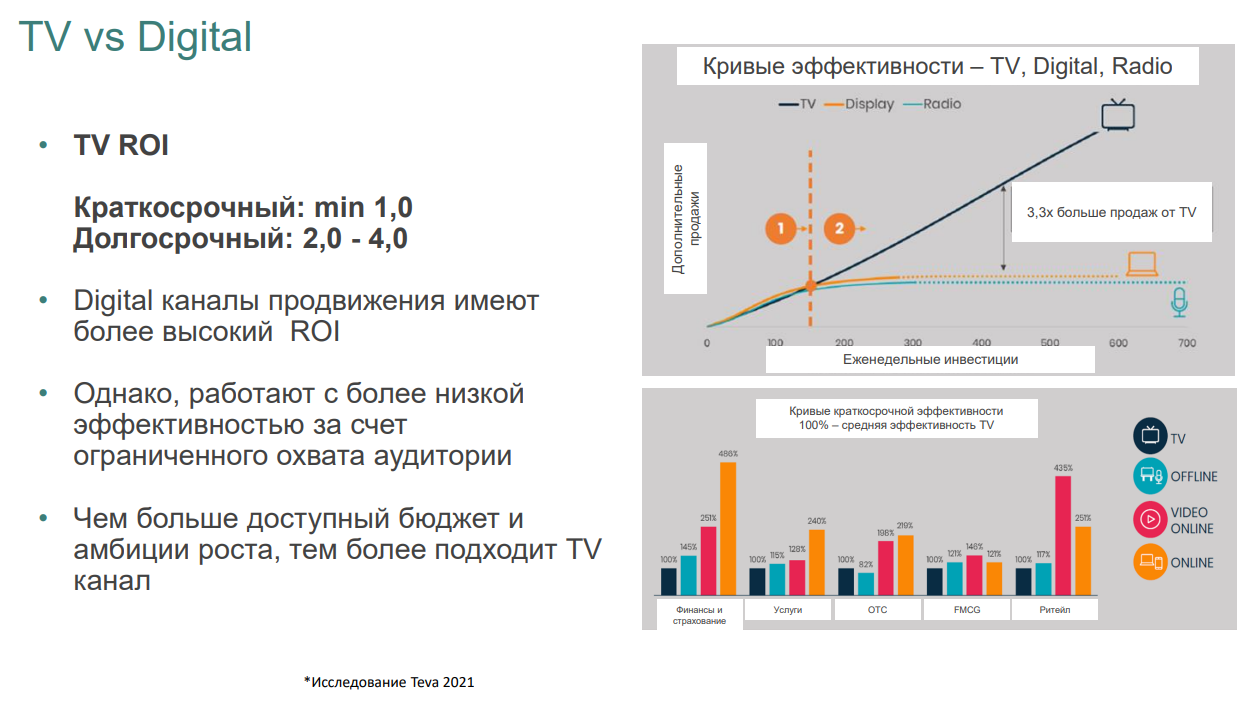
ТВ до сих пор играет ключевую роль в продвижении фармы, поскольку он работает на широкую аудиторию. Digital-каналы имеют более высокий ROI, однако они менее эффективны из-за ограниченного охвата. Чем больше бюджет и планы роста, тем больше вам подходит ТВ.
Content is the King
Важно разделять YouTube и digital, заявляет директор по закупкам OMD OM Group Николай Ануфриев. По мнению эксперта, YouTube превратился в органическую часть телевидения.
Невозможно отрицать пользу digital, но мировой тренд все равно движется в сторону телесмотрения. Тем более что digital в России так и не стал чем-то глобальным, потому что требует усилий. Чтобы скачать кино с торрента, не обойтись без VPN, а конечному потребителю лень этим заниматься. ТВ привлекает людей простотой использования — он не требует знания техники, достаточно нажимать кнопки на пульте.
Нужна единая видеопанель
Оптимальное количество каналов в медиамиксе нужно рассчитывать математически. Именно поэтому Chief Operation Officer Publicis Groupe Russia Сергей Белоглазов выступает за преобразование телевизионной панели в видеопанель, чтобы везде измерять видеовпечатления, не ограничиваясь только линейным телевидением или онлайн-видео. Performance-составляющая тоже добавляется математически.
Сентябрьский опрос в PACE показал, что у 20% респондентов не сформировалась привязанность к брендам. Потребители в возрасте 18–24 года чаще отмечают, что товары выглядят одинаковыми. Кроме того, молодым людям важно, чтобы бренд разделял их ценности, — вес этого атрибута доходит до 29% по всем товарным категориям. Зато тесты на животных, нарушение этики, прав человека и законодательства могут заставить их переключиться на другой бренд.

Один из способов роста ROI целого микса — это сокращение пути потребителя до покупки или конкретного действия, замечает Алексей Толстоган. В этом может помочь эффективный подход к телевизионному планированию. По данным GfK, более половины потребителей хотят получать персональную коммуникацию.
Телевидение приближается к digital
Использование имеющегося массива данных порождает много этических проблем. Недопустимо обращаться к непроверенной информации, считает COO dentsu Russia Дарья Куркина.
Существует множество легальных инструментов, которые позволяют повысить эффективность коммуникации, не переступая законных границ.
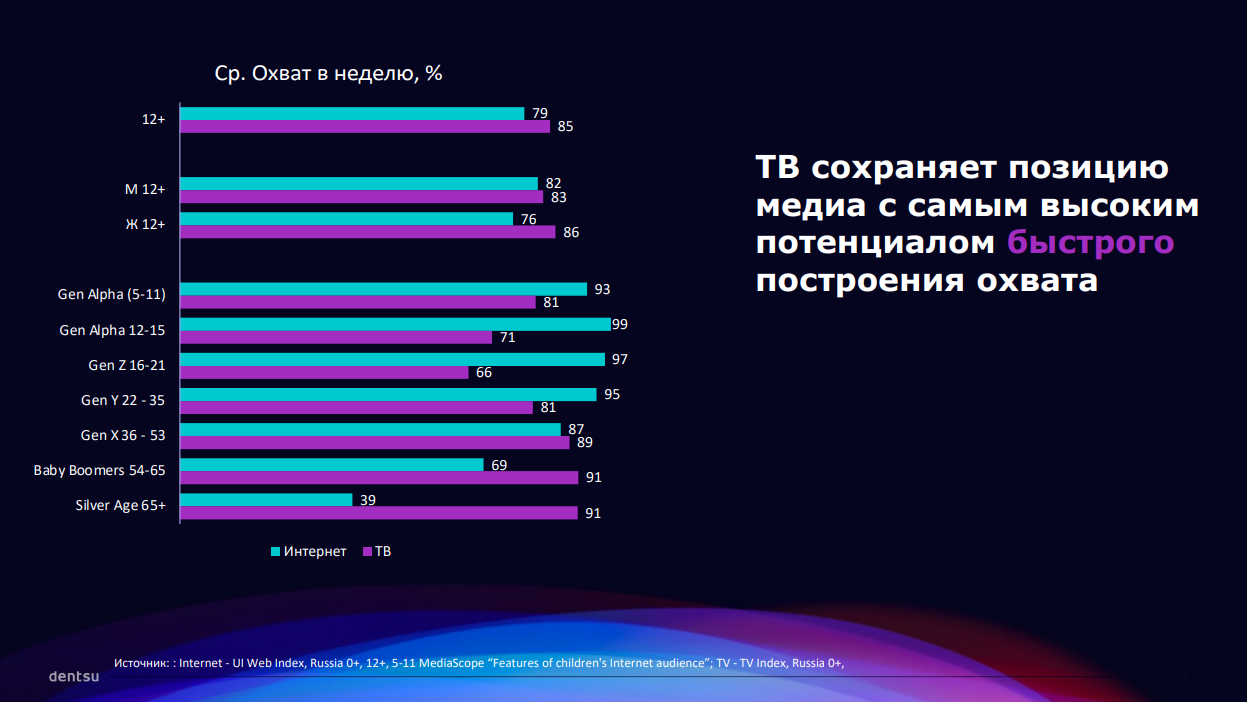
ТВ сохраняет позицию медиа с самым высоким потенциалом быстрого построения охвата. При этом на ряде показателей ТВ динамика ROI не вселяла оптимизма. Главная причина — за последние пять лет телевидение перестало быть однородным. Сейчас, как и в digital, в нем присутствует три типа внимания — фоновое (52%), полное (20%) и отсутствующее (28%).
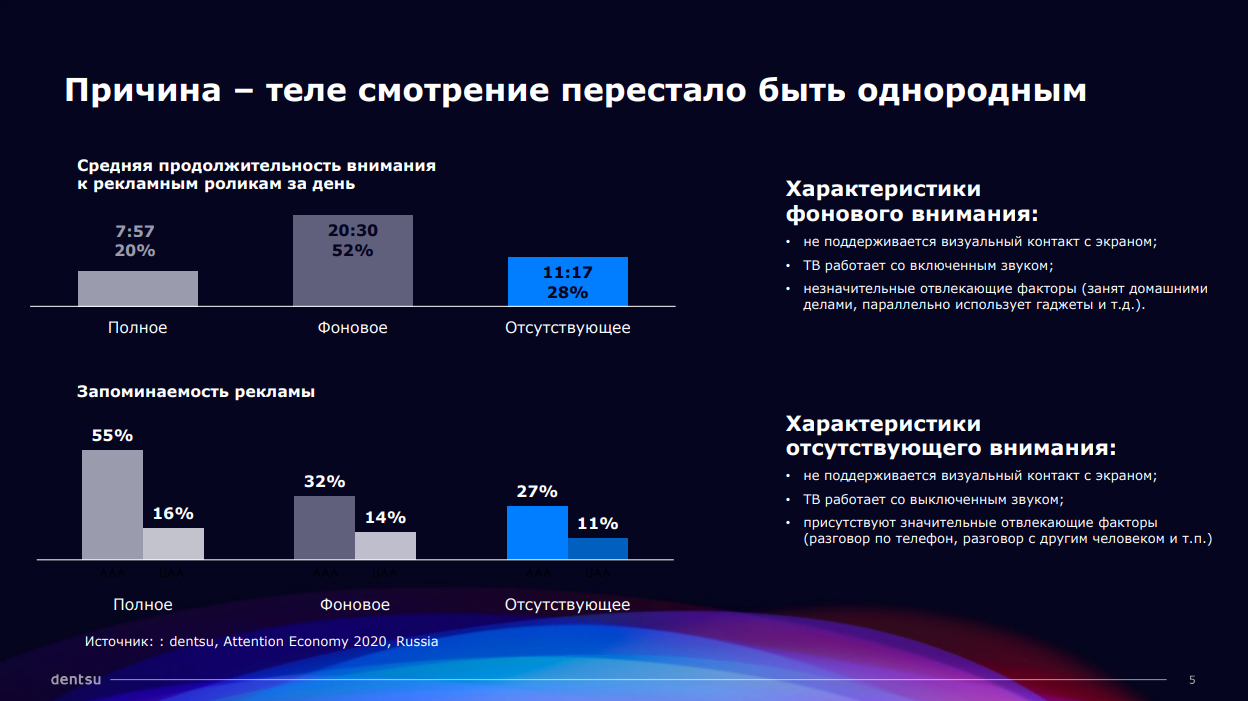
Рекламная индустрия приближается к тому, чтобы работать с телерекламой с учетом тех параметров, к которым все привыкли в digital-среде. На смену линейным измерителям — количеству и стоимости контактов должны прийти другие метрики, вроде анализа досмотра, а также измерения уровня вовлеченности и внимания.
Источник: adindex.ru
Введение в Uplift моделирование

В современном мире большинство компаний заинтересовано в предложении своих услуг как можно большему числу клиентов и пользователей их сервисов. И этим компаниям важно знать как оценивать эффект от коммуникации со своими пользователями. Помочь оценить данный эффект и выбрать интересующую группу пользователей могут модели Uplift моделирования.
Целевым результатом применения Uplift модели является определение клиентов, взаимодействие с которыми принесет компании наиболее интересуемый эффект. Всех адресатов различных рассылок можно разделить на 4 группы:
- Человек, который отреагирует негативно, если отправить ему предложение (отпишется от рассылок, откажется от услуг сервиса и т.д.)
- Человек, который никогда не совершит действие, неважно отправить ему предложение или нет.
- Человек, который в любом случае совершит действие, даже если не отправлять ему предложение.
- Человек, который совершит действие, если отправить ему предложение.
Первые три типа не приносят дохода компании, но могут нести убытки из-за особенности реакции пользователей или затраты на способы взаимодействия с ними. Из всех пользователей, нас больше всего интересуют пользователи четвертого типа, которые ответят на предложение если напрямую отправить им его. Найти данную категорию пользователей можно при помощи Uplift-моделирования. Uplift модель оценивает разницу в поведении адресата при наличии воздействия (или предложения) и при его отсутствии.
Перед созданием модели необходимо провести эксперимент, который заключается в следующем: нужно разбить часть базы пользователей на целевую и контрольную выборку и запустить пилотную версию взаимодействия на целевой выборке пользователей. В данном случае, для взаимодействия мы должны выбирать случайных пользователей. Собранные данные позволят в дальнейшем построить модель uplift прогнозирования на контрольной группе. Также стоит рассмотреть возможность настройки разработки uplift модели итеративно: на каждой итерации будут собираться новые обучающие данные о результатах взаимодействия, которые состоят из комбинированной случайной подвыборки пользователей и пользователей, выбранных моделью.
Для работы с uplift-моделированием в Python есть библиотека scikit-uplift (или сокращенно sklift). В ней также есть несколько наборов данных, на которых можно протестировать реализованную модель.
Одним из наборов данных является Hillstrom Dataset. Этот набор данных содержит информацию о 64000 покупателей, совершивших покупку в течение 12 месяцев. В нём содержатся следующие признаки:
Recency: количество месяцев с момента последней покупки.
History_Segment: категоризация денежных средств, потраченных в прошлом году.
History: Фактическая стоимость, израсходованная за последний год.
Mens: показатель 1/0, 1 = покупатель приобрел мужские товары в прошлом году.
Womens: показатель 1/0, 1 = покупатель приобрел женские товары в прошлом году.
Zip_Code: классифицирует почтовый индекс как городской, пригородный или сельский.
Newbie: индикатор 1/0, 1 = новый клиент за последние двенадцать месяцев.
Channel: описывает каналы, через которые клиент совершил покупку в прошлом году.

Перед применением Uplift-моделирования также необходимо провести разведочный анализ данных, который обычно состоит из следующих основных шагов:
- Проанализировать все виды признаков, которые имеются в нашем наборе данных (категориальные, вещественные и т.д.).
- Проверить коллинеарность признаков с помощью матрицы корреляции (оценить возможность исключения признака, в случае выявления коллинеарности с другим признаком).
- Проверить сбалансированность классов целевой переменной
Далее требуется разделить выборку данных на тренировочную и валидационную (на которой мы будем подбирать гиперпараметры). Это можно сделать с помощью функции train_test_split из библиотеки sklearn.
X_train, X_val, y_train, y_val, treat_train, treat_val = train_test_split( dataset, target, treatment, test_size=0.3, random_state=42)
Обучение модели можно провести с помощью CatBoostClassifier из библиотеки градиентного бустинга Catboost. Суть бустинга, как и других ансамблей алгоритмов состоит в том, чтобы из нескольких слабых моделей собрать одну сильную. Общая идея алгоритмов бустинга – последовательно применять предикторы так, чтобы каждая последующая модель минимизировала ошибку предыдущей модели. К преимуществам использования библиотеки Catboost относится возможность проводить обучение на нескольких GPU; обеспечение высокой точности за счёт уменьшения переобучения; возможность предварительно не обрабатывать категориальные признаки (нет необходимости использовать one-hot кодирование); возможность использования как для задач регрессии, так и для задач классификации.
estimator = CatBoostClassifier(cat_features=cat_columns, random_state=42, thread_count=1 ) model = ClassTransformation(estimator=estimator)
Обучить модель можно с помощью метода fit.
model.fit( X=X_train, y=y_train, treatment=treat_train )
Далее следует вызвать метрику для оценки качества модели. Вызвать Uplit кривую можно при помощи.
auc_coef = uplift_auc_score(y_true=y_val, uplift=uplift_predictions, treatment=treat_val)
Визуализировать полученную кривую можно использовав методы
uplift_disp = plot_uplift_curve( y_val, uplift_predictions, treat_val, perfect=True, name=’Model name’ ) uplift_disp.figure_.suptitle(«Uplift curve»)
Пример графика Uplift кривой.

По графику Uplift кривой видно, что получившаяся модель имеет более высокую точность, чем случайная модель. Для повышения точности модели можно расширить набор данных, собрав больше информации или, например, комбинировать информацию о взаимодействии, ранжировать пользователей сначала в целевой, затем в контрольной группе.
Источник: newtechaudit.ru