1. Графические методы связаны с геометрическим изображением функциональной зависимости при помощи линий на плоскости. С помощью координатной сетки строятся графики зависимости, например, уровня издержек от объема произведенной и реализованной продукции, а также графики, на которых можно изображать корреляционные связи между показателями (диаграммы сравнения, кривые распределения, диаграммы временных рядов, статистические картограммы).
Пример: построение сетевого графика при строительстве и монтаже предприятий. Составляется таблица работ и ресурсов, где в технологической последовательности указываются их характеристика, объем, исполнитель, сменность, потребность в материалах, продолжительность выполнения задания и другая информация. Исходя из данных показателей подготавливают сетевой график. Оптимизация графика осуществляется посредством сокращения критического пути, т. е. минимизации сроков выполнения работ при заданных уровнях ресурсов, минимизации уровня потребления ресурсов при фиксированных сроках выполнения работ.
Бизнес-анализ: методология и инструментарий. Роль бизнес-аналитика.
2. Метод корреляционно-регрессивного анализа используют для определения тесноты связи между показателями, не находящимися в функциональной зависимости. Теснота связи измеряется корреляционным отношением (для криволинейной зависимости). Для прямолинейной зависимости исчисляется коэффициент корреляции. Метод применяют при решении задач на «запуск-выпуск».
Пример: определить зависимость выпуска изделий в среднем от их запуска, составив соответствующее уравнение регрессии.
3. Метод линейного программирования. Решение сводится к нахождению крайних значений (максимума и минимума) некоторых функций переменных величин. Основано на решении системы линейных уравнений, когда зависимость между явлениями строго функциональна.
Пример: задачи рациональности использования времени работы производственного оборудования.
4. Методы динамического программирования применяют при решении оптимизационных задач, в которых целевая функция и ограничения характеризуются нелинейными зависимостями.
Пример: заполнить транспортное средство грузоподъемностью Х грузом, состоящим из определенных предметов так, чтобы стоимость всего груза оказалась максимальной.
5. Математическая теория игр исследует оптимальные стратегии в ситуациях игрового характера. Решение требует определенности в формулировке условий: установлении количества игроков, возможных выигрышей, определении стратегии.
Пример: максимизировать среднюю величину дохода от реализации выпущенной продукции, учитывая капризы погоды.
Источник: studopedia.su
Матстатистика для бизнес-аналитика: краткий ликбез
28/5/23
Знание математической статистики обязательно для продуктового аналитика и дата-аналитика, которые исследуют данные о пользовательском поведении, генерируют и проверяют гипотезы, анализируют результаты экспериментов. Однако, системным и бизнес-аналитикам понимание тоже полезно понимать, почему среднее арифметическое – не самая лучшая метрика для количественных показателей, зачем определять доверительный интервал, что такое нормальное распределение и почему оно так часто встречается. Разбираемся на конкретных примерах.
Что такое распределение и почему оно чаще всего нормальное
Цель этой статьи – на практических примерах объяснить основные термины матстатистики, которые встречаются в системном и бизнес-анализе. Поэтому фундаментальные понятия теории вероятностей и полная математическая база статистики останутся за рамками нашего рассмотрения. Впрочем, согласно принципу Парето, 20% усилий дают 80% результата. Поэтому большинству системных и бизнес-аналитиков для понимания многих закономерностей в их области деятельности достаточно будет понимания рассмотренных здесь терминов.
Считается, что в природе и бизнесе значения метрик, а также количественных показателей чаще всего распределены по нормальному закону, т.е. их функция их плотности вероятности соответствует распределению Гаусса и выглядит как перевернутая парабола с четко выраженным пиком. Этот пик называется математическом ожиданием и в случае нормального распределения он равен среднему арифметическому, т.е. сумме всех значений, деленной на их количество. Например, рост взрослой физически здоровой женщины может варьироваться от 137 сантиметров до 224, но это крайние значения. А большинство измерений находятся на уровне 165 см. Это означает, что можно сказать, что рост взрослой физически здоровой женщины в среднем составляет 165 см.
Широкая распространенность нормального распределения случайных величин основана на их представлении в виде произвольного количества независимых, одинаково распределённых слагаемых, не влияющих друг на друга. Математическое обоснование можно найти в теоремах Ляпунова и Колмогорова и формуле Леви-Хинчина. А практический смысл этих глубоких работ сводится к центральной предельной теореме, согласно которой, что если измерений много (большая выборка случайных значений), то они распределены нормально. Поэтому, зная только математическое ожидание значения метрики и ее стандартное отклонение, можно вычислить вероятность его возникновения. Стандартное отклонение (сигма) показывает разброс случайных величин в выборке, т.е. насколько далеко возможные значения отходят от матожидания, т.е. среднего арифметического в нормальном распределении. Причем для нормальных выборок характерно так называемое правило 3 сигм:
- 1/3, т.е. примерно 68 % значений находятся на расстоянии не более одного стандартного отклонения σот матожидания;
- около 95 % значений лежат расстоянии не более двух стандартных отклонений от матожидания;
- 2/3 значений, т.е. 99,7 % отстоят от матожидания на расстояние не более 3-х стандартных отклонений.
А с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в интервале матожидание плюс-минус 3 стандартных отклонения.
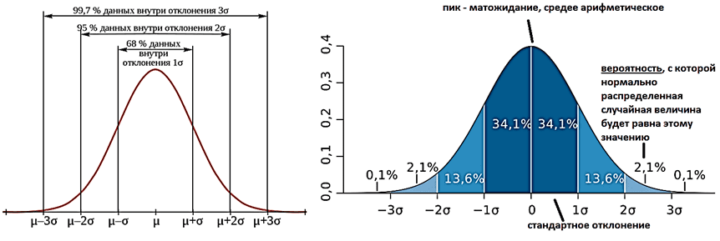
На практике именно по такой закономерности могут определяться приемлемые значения показателей управленческого учета для бизнес-процессов и продуктовые метрики. Например, при критическом отклонении фактического значения от ожидаемого, ответственному генерируется уведомление и/или запускается процедура реагирования на этот инцидент согласно внутренней системы менеджмента качества (СМК). Именно на этом построена одна из концепций производственного менеджмента под названием «Шесть сигм» (six sigma), которая вошла в основу производственной системы Toyota на базе Lean и статистических методов контроля отклонений от заданных показателей.
От процессов к продуктам: Product Ownership и Agile-практики для бизнес-аналитика
Код курса
POAP
Ближайшая дата курса
19 июня, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
Среднее арифметическое, медианное и модальное значение: чему верить
Чтобы выборка была статистически значимой и подчинялась нормальному закону распределения, она должна быть достаточно большая. На практике это означает, что для формирования объективных выводов, например, о причинах проблем с производительностью информационной системы или пользовательского поведения, нужно проанализировать определенное количество лог-файлов или профилей. Но объем выборки для анализа – это не доля от генеральной совокупности (всех возможных значений), а сложная функция от доверительного уровня, предельной ошибки выборки и долей измерений с отсутствием и присутствием исследуемого признака.
Доверительный уровень – это вероятность того, что реальное значение лежит в границах полученного доверительного интервала. Доверительный уровень устанавливается исследователем в зависимости от необходимой надежности результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99.
А доверительный интервал означает вероятность соответствия случайного значения матожиданию для нормального распределения. Например, DAU равно 800 на доверительном интервале 70%. Это означает, что в течение 5 будних дней на протяжении недели, т.е. в 7 случаев из 10, на сайт заходит около 500 уникальных посетителей.
Но если расширить этот доверительный интервал до 95%, включив сюда и часть выходных дней, среднее арифметическое значение метрики может поменяться и составить 400 человек. Это происходит потому что границы выборки расширяются, т.е. сюда попадает больше крайних значений. В нашем примере это может быть падение спроса на b2b-продукты в выходные и снижение DAU до 200 в субботу и воскресенье.
На практике это означает, что для разных исследований нужны выборки разных размеров. Например, чтобы сделать объективные выводы о средней скорости выполнения SQL-запросов в информационной системе, можно взять расширенную выборку, т.е. с большим значением доверительного интервала, чтобы захватить редкие сложные случаи, которые выполняются редко и очень медленно.
Однако, чем шире доверительный интервал для заданного уровня вероятности, тем ниже уровень доверия, т.е. доверительный уровень к результатам. И, наоборот, чем уже доверительный интервал, тем надежнее выборочная оценка. Вероятность, связанная с доверительным интервалом, называется доверительной вероятностью. Если доверительный интервал строится по уровню 95%, то соответствующая доверительная вероятность будет 5%, или 0,05=1-95%, для интервала по уровню 98% — 2%, или 0,02.
Эти примеры показывают несостоятельность среднего арифметического как объективной метрики для формирования объективных управленческих решений. Напомним, в нормальном распределении матожидание случайной величины равно среднему арифметическому, т.е. сумме всех измерений, деленной на их количество. Это отлично иллюстрирует правдивая шутка про среднюю температуру по больнице 36,6 с учетом гнойного отделения и морга. Например, DAU 500 человек в день, распределенное по дням недели, оказывается равным от 460 до 830 уникальных посетителей в будни и 200 в выходные. Согласно данным с популярной площадки для работодателей и соискателей HeadHunter, зарплата бизнес-аналитика в 2021 году в среднем составляет 99 т.р. и колеблется в пределах от 15 до 500 тысяч по всем городам РФ, для всех вариантов занятости (полная/частичная) и профессиональных грейдов.
Основы бизнес-анализа: вход в профессию для начинающих
Код курса
INTRO
Ближайшая дата курса
29 мая, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
50 000 руб.
Поэтому для формирования качественных выводов по количественным измерениям лучше использовать не среднее арифметическое, а медианное и модельное значения, причем уточненные по группам. Медиана — это число в середине выборки, которое делит измерения на 2 половины, одна из которых его больше, а 2-я – меньше.
Например, медианная зарплата бизнес-аналитика в 2021 году составила 87 т.р. по России, а в Москве и Спб – 108 т.р. Модальное значение или мода – то, что встречается в выборке чаще других. В примере с месячной заработной платой бизнес-аналитика это 200 т.р. для Москвы, согласно дэшборду https://revealthedata.com/examples/hh/. О зарплатах бизнес-аналитиков по другим странам и в среднем по миру читайте в обзоре отчета IIBA® за 2021 год.
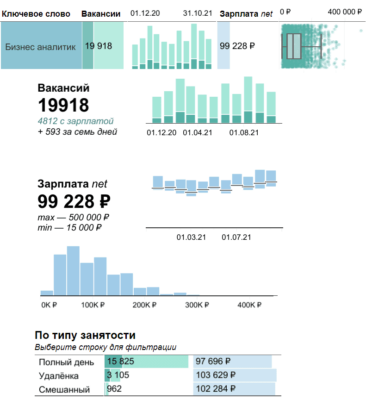
Если вернуться к кейсу с DAU, модой может быть 620 уникальных посетителей в будний день. А модальное значение длительности выполнения SQL-запроса скажет о производительности информационной системы гораздо точнее, чем среднее арифметическое, и позволит сделать выводы о наиболее частых вариантах использования. На практике это пригодится при разработке или корректировке нефункциональных требований к ПО.
Источник: babok-school.ru
Исследование математических моделей, методов и средств бизнес-аналитики СУБД SQL Server
Повсеместное использование компьютеров привело к пониманию важности задач, связанных с анализом накопленной информации для извлечения новых знаний. Управление предприятием, банком, различными сферами бизнеса, немыслимо без процессов накопления.
Постановка задачи и обзор литературы
Постановка задачи 1. Необходимо выполнить обзор различных технологий в бизнес-аналитике на примере СУБД SQL Server. 2. Также надо обозначить перечень используемых математических моделей и описать их сущность. 3. Произвести анализ языковых средств, с.
Архитектура СУБД SQL Server
В SQL Server реализовано несколько технологий управления и анализа данных. На рисунке 10 схематично представлены компоненты СУБД MS SQL Server 2008. Для многомерных данных (OLAP): Службы MicrosoftSQL ServerAnalysis Services реализуют быстрый и.
Математические основы бизнес-аналитики
Математические основы оперативного анализа данных Существующие математические модели многомерных OLAP-систем обладают следующими недостатками, касающимися формальной структуры этих моделей. 1) Моделирование запросов к многомерной БД с помощью.
Задачи, методы и алгоритмы Data Mining
В службах MicrosoftSQLServerреализовано несколько алгоритмов в решениях интеллектуального анализа данных. Выбор правильного алгоритма в конкретной аналитической задаче может быть достаточно сложным. В то время как можно использовать различные.
Задача кластеризации
Большое достоинство кластерного анализа в том, что он позволяет осуществлять разбиение объектов не по одному параметру, а по целому набору признаков. Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих».
Обзор алгоритмов интеллектуального анализа данных
Существует большое количество методов и алгоритмов интеллектуального анализа данных. Но в данной работе мы ограничимся рассмотрением тех алгоритмов, которые реализуются в SQL Server 2008, так как тема бакалаврской работы связана с рассмотрением.
Алгоритм дерева принятия решений
Алгоритм представляет собой алгоритм регрессии и алгоритм классификации, предоставляемый службами Microsoft SQL Server Службы Analysis Services для использования в прогнозирующем моделировании как дискретных, так и непрерывных атрибутов. Для.
Алгоритм линейной регрессии
Алгоритм линейной регрессии позволяет представить зависимость между входной и выходной переменными как линейную, а затем использовать полученный результат при прогнозировании. Линия на диаграмме является наилучшим линейным представлением данных. Рис.
Алгоритм кластеризации
Кластеризация позволяет снизить размерность задачи анализа предметной области, путем «естественной» группировки вариантов в кластеры. Таким образом, кластер будет объединять близкие по совокупности параметров элементы, и в некоторых случаях, его.
Алгоритм взаимосвязей
Алгоритм взаимосвязей или ассоциативных правил (Association Rules) позволяет выявить часто встречающиеся сочетания элементов данных и использовать обнаруженные закономерности для построения прогноза. Для выявления часто встречающихся наборов.
Алгоритм нейронных сетей
В случае наличия в данных сложных зависимостей между атрибутами, «быстрые» алгоритмы интеллектуального анализа, такие как упрощённый алгоритм Байеса, могут давать недостаточно точный результат. Улучшить ситуацию может применение нейросетевых.
Языковые средства бизнес-аналитики: языки MDX и DMX
Базовые понятия языка MDX MDX (MultiDimensional eXpressions — язык многомерных выражений) является языком запросов, используемым для извлечения данных из многомерных баз данных. Он используется для запрашивания данных из баз данных OLAP с помощью.
Создание структуры многомерного анализа
Выражение WHERE
Для задания условия отбора применяется предложение WHERE. Инструкция WHERE ограничивает набор результатов запроса с помощью некоторого критерия. SELECT Measures. [Sales] ON COLUMS, [Product]. [Product Line].MEMBERS on ROWS FROM ProductsCube WHERE ([.
Выражения MDX
Выражения MDX представляют собой инструкции языка MDX, которые вычисляют определенные значения. Обычно они используются для вычисления или определения значений для таких объектов, как заданный по умолчанию член и заданная по умолчанию размерность.
Функции
Функции MDX могут использоваться в выражениях или запросах MDX. Функции MDX помогают обращаться к некоторым общим операциям, которые требуются в ваших запросах или выражениях MDX. Функции набора применяются для выполнения операций с наборами.
Базовые понятия языка DMX
Наименьшей логической единицей работы с данными при интеллектуальном анализе является атрибут, который содержит некоторую «элементарную» информацию об анализируемом примере. Для алгоритмов Data Mining существует два основных типа атрибутов: ·.
Создание структуры интеллектуального анализа данных
Структура интеллектуального анализа данных может быть представлена как совокупность исходных данных и описания способов их обработки. Структура содержит модели, которые используются для анализа ее данных. Рассмотрим конструкции языка DMX.
Создание модели интеллектуального анализа данных
Создание модели интеллектуального анализа данных можно осуществить одним из следующих способов: 1. после создания структуры интеллектуального анализа данных можно добавлять в нее модели с помощью инструкции ALTER MINING STRUCTURE; 2. можно.
Листинг
Удалить данные, модель или структуру можно с помощью оператора DELETE. Его синтаксис приведен ниже: DELETE FROM [MINING MODEL] [.CONTENT] DELETE FROM [MINING STRUCTURE] [.CONTENT]|[.CASES] Таблица 8. Значения.
Детализация структуры
Рассмотрим инструкцию FROM. Если в ней стоит .CASES, где — имя структуры интеллектуального анализа, то будут возвращаться варианты, использованные для создания структуры. Если детализация для структуры не включена.
Использование Microsoft SQL Server для аналитической обработки данных
Постановка задача для экспериментальной части работы Цель экспериментальной части работы — показать возможные применение технологий бизнес-аналитики на предприятии. Решаемые задачи: 1. Формирование источника данных, представление источника данных, в.
Задача кластеризации клиентов базы данных AdventureWorks
Пусть необходимо разделить всех клиентов на несколько групп, сходных по значениям параметров. Подобная задача называется — кластеризацией. Необходимо создать структуру, основанную на реляционной БД, и модель интеллектуального анализа данных. Для.
Заключение
В поисках возможностей извлечения данных и выделения из них информации, позволяющей делать прогнозы и принимать меры, компании часто тратят значительные средства на приобретение больших и сложных приложений бизнес-аналитики. Целью выпускной работы.
Источник: studentopedia.ru