Играя огромную роль в индустрии больших данных, машинное обучение (ML) является еще одной технологией, которая, как ожидается, окажет существенное влияние на наше будущее. Проекты в этой сфере получили наибольшее финансирование в 2019 году по сравнению со всеми другими системами искусственного интеллекта.
До недавнего времени ML и ИИ были недоступны большинству компаний из-за доминирования платформ с открытым исходным кодом. Хотя те и были разработаны, чтобы сделать технологии ближе к людям, большинству компаний не хватает навыков для самостоятельной настройки необходимых решений.
Ситуация изменилась, как только коммерческие поставщики ИИ начали создавать соединители для платформ с открытым исходным кодом и предоставлять доступные продукты и сервисы, не требующие сложного конфигурирования. Коммерческие поставщики предлагают функции, которых в настоящее время не хватает платформам с открытым исходным кодом, такие как управление моделью машинного обучения и повторное использование.
Между тем эксперты предполагают, что способность компьютеров учиться на данных значительно улучшится благодаря более совершенным неконтролируемым алгоритмам, более глубокой персонализации и когнитивным услугам. В результате появятся машины, которые будут более умными и способными читать эмоции, водить автомобили, исследовать пространство и лечить пациентов.
Услуги Data Scientists и CDO’s будут пользоваться все большим спросом
Должности специалистов Data Science и Chief Data Officer (CDO) являются относительно новыми, и поэтому потребность в таких сотрудниках на рынке труда довольно высока. В 2019 году KPMG опросили 3600 ИТ-директоров и технологических руководителей из 108 стран и выяснили, что 67% из них столкнулись с нехваткой навыков в сфере аналитики больших данных, безопасности и искусственного интеллекта. Неудивительно, что Data Scientist входит в список самых быстрорастущих на рынке труда профессий, наряду с инженерами ML и аналитиками Big data. Большие данные бесполезны без анализа, и только специалисты могут превратить их в действенные идеи.
Пытаясь преодолеть разрыв в навыках, компании теперь также обучают специалистов Citizen Data Scientist, которые занимают позицию вне аналитической области, но при этом способны анализировать данные.
CDO — это руководители уровня C, отвечающие за доступность, целостность и безопасность данных в компании. По мере того, как все больше владельцев бизнеса осознают важность этой роли, найм CDO становится нормой: если верить опросу «Big Data and AI Executive Survey 2019» от NewVantage Partners, 67,9% крупных компаний уже заполнили данную позицию.
Однако позиция Chief Data Officer во многом остается неопределенной, особенно с точки зрения разделения обязанностей между CDO, Data Scientists и CIO. Это одна из ролей, которая зависит от бизнес-потребностей конкретных компаний, а также их цифровой зрелости. Следовательно, позиция CDO будет развиваться вместе с тем, как мир станет более ориентированным на данные.
Быстрые и действенные данные выйдут на передний план
Еще одно предсказание о будущем связано с появлением так называемых «быстрых данных» и «действенных данных». В отличие от больших данных, требующих наличия сервисов Hadoop и NoSQL для анализа информации, быстрые данные можно обрабатывать в масштабе реального времени. Благодаря такой потоковой обработке информация может быть проанализирована буквально за считанные миллисекунды.
Это приносит больше пользы организациям, которые могут принимать бизнес-решения и предпринимать действия сразу же после поступления данных. Быстрые данные также испортили пользователей, сделав их зависимыми от взаимодействия в реальном времени. По мере того, как бизнес становится все более цифровым, качество обслуживания клиентов повышается – пользователи ожидают, что получат доступ к данным на ходу. Более того, они хотят, чтобы это было персонализировано. В подготовленном для Seagate отчете IDC прогнозирует, что к 2025 году к почти 30% глобальных данных будет обеспечен доступ в режиме реального времени.
Действенные данные – недостающее звено между Big data и бизнесом. Как уже упоминалось ранее, большие данные сами по себе бесполезны без эффективного анализа. Обрабатывая их с помощью аналитических платформ, организации могут сделать информацию точной, стандартизированной и действенной. Эти знания помогают принимать более обоснованные бизнес-решения, совершенствовать деятельность и разрабатывать больше вариантов использования собранной информации.
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
- подготовитесь к сдаче вступительных экзаменов в Школу анализа данных Яндекса;
- углубитесь в математический анализ, линейную алгебру, комбинаторику, теорию вероятностей и математическую статистику;
- узнаете роль чисел, формул и функций в разработке алгоритмов машинного обучения.
- освоите специальную терминологию и сможете читать статьи по Data Science без постоянных обращений к поисковику.
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.
Источник: proglib.io
Что такое Big Data
Рассказываем, как обрабатываются и хранятся большие данные.

Владислав Филинков
Автор статьи
21 сентября 2022 в 12:37
Big data — это наборы данных, которые быстро генерируются и поступают из разных источников. В совокупности они создают огромный массив данных, которые можно использовать для анализа, прогнозов, статистики, принятия решений.
Термин «большие данные» появился только в 2008 году, когда редактор журнала Nature Клиффорд Линч заявил, что объем информации в мире растет слишком быстро. До 2011 года big data использовали только в науке и статистике. С 2014 года сбором и анализом данных занялись ведущие вузы мира и IT-гиганты: IBM, Google, Microsoft.
Что такое big data?
Большие данные — это огромный объем структурированной и неструктурированной информации. Также к big data относятся технологии, которые используют, чтобы собирать, обрабатывать данные и использовать их в работе.
К большим данным можно отнести поток сообщений из социальных сетей, датчики трафика, спутниковые снимки, стриминговые аудио- и видеопотоки, банковские транзакции, содержимое веб-страниц и мобильных приложений, телеметрию с автомобилей и мобильных устройств, данные финансового рынка.
Технологические компании практически никогда не удаляют собранную информацию, так как завтра она может стоить в разы больше, чем вчера. И даже сегодня она уже приносит миллиардные прибыли многим компаниям. Первые версии системы хранения больших данных Hadoop даже не имели команды «Удалить данные»: такой функции не предполагали.
Как пример — Facebook*. Компания использует информацию о поведении пользователей, чтобы рекомендовать новости, продукты внутри соцсети. Знания об аудитории повышают интерес пользователей и мотивируют посещать соцсеть как можно чаще. Как следствие — растет прибыль Facebook.
А гугл выдает результаты поиска не только на основе ключевых слов в поисковом запросе. Он также учитывает историю предыдущих запросов и интересы пользователя.
За последние годы производительность вычислительных систем сильно выросла. Это видно на графике роста количества транзисторов за последние 50 лет.
Транзистор — это полупроводниковый элемент. Из транзисторов собирают основные логические элементы, а на их основе создают различные комбинационные схемы и непосредственно процессоры. Чем больше транзисторов в процессоре — тем выше его производительность.
Закон Мура: количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые два года
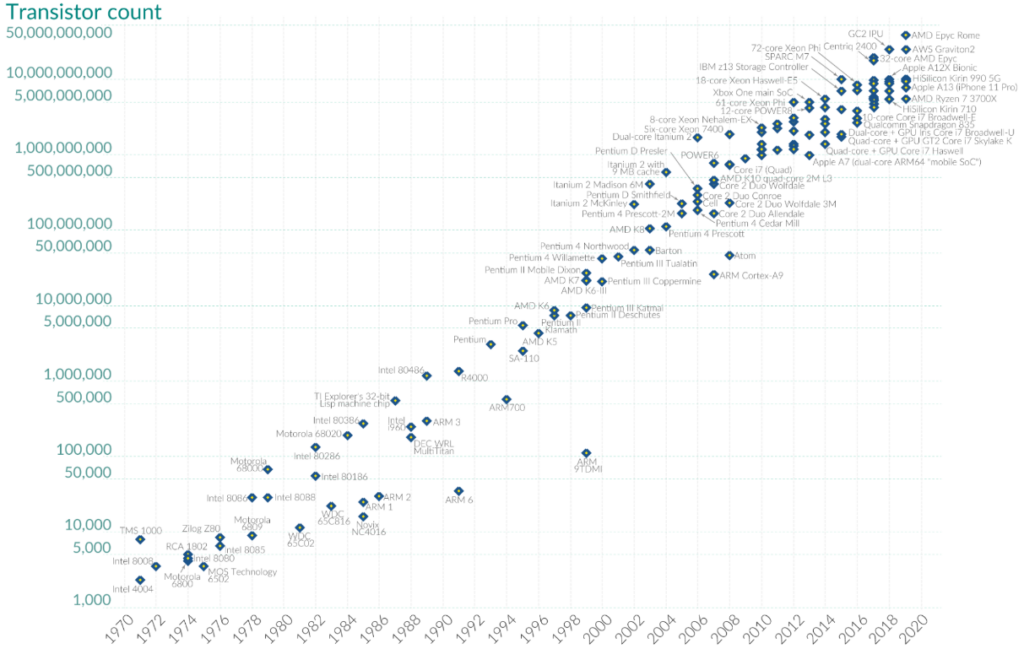
Закон Мура: количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые два года График: ourworldindata.org
Благодаря высокой производительности появилась возможность обрабатывать данные с такой же большой скоростью, с которой они поступают.
Видео: «Яндекс» на ютубе
Характеристики больших данных
Обычно big data описывают с помощью шести характеристик.
Volume (объем). Нет четких критериев, при каком объеме данные можно назвать «большими». «Много данных» — это метрика, которая зависит от времени и мощностей. Например, 30 лет назад считалось, что на жесткий диск объемом 10 Мб помещается много данных. В 2022 году большой объем — это 100–150 Гб.
На графике ниже видна динамика увеличения средней вместительности жестких дисков, по информации производителя Seagate.
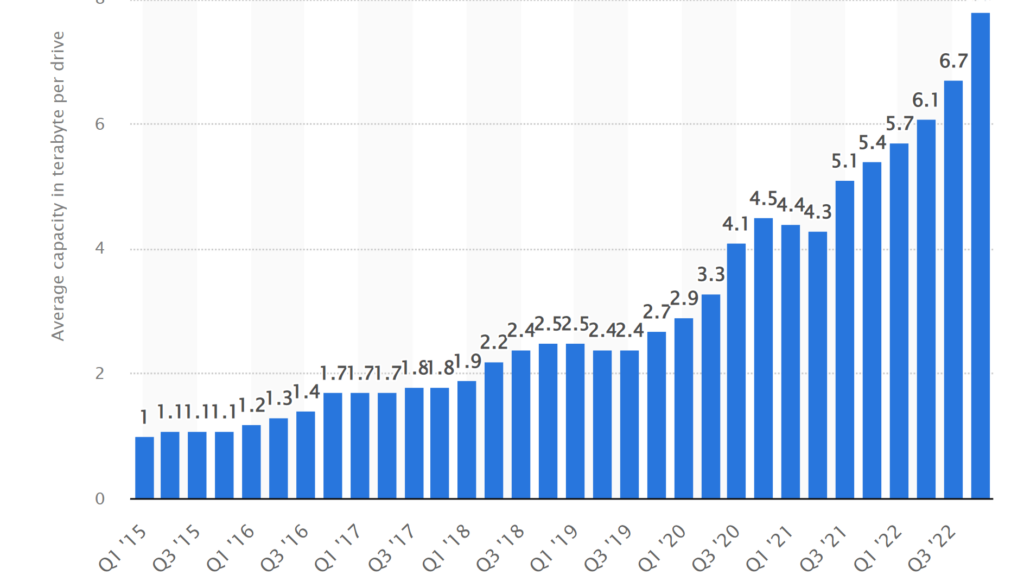
Средняя емкость HDD с 2015 по 2022 год Скриншот: statista.com
Velocity (скорость). Эта характеристика описывает скорость накопления данных. Скорость накопления определяют два фактора:
- Скорость накопления от одного источника данных. Например, социальная сеть сохраняет информацию о том, сколько раз один пользователь открывал страницу у себя на компьютере или в приложении на смартфоне. Информация может сохраняться десятки раз в день.Также могут собираться данные производственного оборудования, которое передает важные показатели о своем состоянии. Эта информация может генерироваться 10–100 раз в секунду!
- Количество источников данных. Например, социальная сеть имеет миллионы пользователей по всему миру. Если собирать информацию по каждому пользователю, скорость накопления будет — миллионы записей в секунду.
При этом производственного оборудования на одном заводе может быть несколько десятков штук. А итоговая скорость накопления данных будет до тысячи записей в секунду.
Variety (разнообразие). Данные могут отличаться как по контенту, так и по типу данных: структурированные, слабоструктурированные и неструктурированные.
Чтобы построить систему управления big data и систему анализа данных, нужно понимать, какие используются типы данных:
- Структурированные — это строго организованные данные. Например, в Excel все работают со структурированными данными.
- Слабоструктурированные — обычно это так называемые интернет-данные. К ним относится информация, полученная из социальных сетей, или история посещения сайтов. Так, JSON и XML имеют формат слабоструктурированных данных.JSON (англ. JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript. Но при этом формат независим от JS и может использоваться в любом языке программирования.
XML (англ. Extensible Markup Language) — расширяемый язык разметки. Также используется для хранения и передачи данных.
Из-за простоты JSON используют чаще, но на базе XML можно строить более сложные структуры данных. - Неструктурированные — данные произвольной формы и не имеющие заранее определенной формы. Например, файлы, каждый из которых уникален сам по себе. При этом их хранение нужно как-то организовать.
Veracity (достоверность). Достоверность — это когда данные «правильные» и непротиворечивые. То есть им можно верить и их можно анализировать и использовать, чтобы принимать бизнес-решения.
Высокие требования к достоверности обычно предъявляют в финансовых организациях. Одно неверно записанное в базу число может привести к некорректным отчетам.
Но есть ситуации, когда достоверность не так важна. Когда скорость накопления данных больше тысячи записей в секунду, то одна или даже десять ошибочных записей не создадут проблемы. Ведь после них последуют еще 900 записей хорошего качества.
Variability (изменчивость). Потоки данных могут изменяться по разным причинам: из-за социальных явлений, сезонов, внешнего воздействия. Когда собирают данные температуры производственного оборудования или вычислительного сервера, информация постоянно изменяется, если измерять температуру достаточно точно.
Изменчивость относится и к частоте получения данных. Иногда поступает 1000 записей в секунду, иногда — 100 записей. Например, данные изменяются, когда собирают информацию о количестве активных пользователей приложения. Так получается, потому что пользователи открывают приложение не каждый день.
Value (ценность, или значимость). Ценность — это фактор, который определяет весь перечень основных характеристик, описанных выше. Она зависит от возможности самой организации извлекать из данных пользу и превращать знания в ценность для клиентов.
Источники больших данных
Большие данные непрерывно поступают из разных источников. Ниже перечислены основные.
Социальные. Это данные, которые поступают из социальных сетей, веб-сайтов, мобильных приложений и сервисов, интегрированных с социальными сетями. Социальные данные содержат историю посещения социальных сетей, мессенджеров, реакции на сообщения, новости и любые другие действия пользователей.
Машинные. Данные, которые оборудование производит о самом себе. Это может быть информация о местоположении, внутреннем состоянии оборудования (например, температура) и другие показатели.
Оборудованием считаются любые носимые устройства, элементы «умного» дома, производственное оборудование на заводе.
Транзакционные. Это банковские или любые другие финансовые транзакции. С появлением необанков и fintech-стартапов количество транзакционных данных в мире резко выросло.
Где хранят и как обрабатывают big data
Большие данные хранятся в data-центрах с мощными серверами. Современные вычислительные системы обеспечивают мгновенный доступ ко всем данным.
Для работы с big data используют распределенные системы хранения данных. Часто все данные не помещаются на одном сервере и их нужно распределить на несколько.
Распределение данных помогает быстрее обрабатывать информацию. Это возможно, потому что над каждой частью данных работает отдельный сервер и процессы обработки идут параллельно.
Есть распределенные системы вычислений, которые позволяют работать с данными размером больше одного петабайта. Например, Spark и его более старая версия — MapReduce.
Одна из самых популярных систем для сбора и хранения данных — Hadoop. На ее основе появилось целое семейство других систем хранения, которые работают «поверх» Hadoop. Они позволяют добавлять новые функциональные возможности, которые недоступны в базовой сборке Hadoop.
Методы анализа big data
Для анализа можно использовать любые объемы больших данных. Иногда данные сначала структурируют и выбирают нужные для анализа. Вот основные методы анализа big data:
Описательная аналитика. Это анализ, цель которого — дать ответ на вопрос «что случилось?». Пример описательной аналитики — финансовый отчет, который описывает произошедшее, не объясняя причин. Еще пример — статистика активных пользователей соцсети за день.
Диагностическая аналитика. На этом шаге анализа нужно понять: «почему это случилось?». Иногда диагностическую аналитику называют факторным анализом. То есть при анализе выявляют факторы, из-за которых произошли изменения в показателях. Так, финансовые аналитики ежегодно докладывают об изменениях в инфляции и рассказывают, почему она изменилась.
Определение факторов, за счет которых изменилась инфляция, — это результат диагностической аналитики.
Прогнозная аналитика. Цель метода — ответить на вопрос «что случится в будущем?». Для анализа используют методы data science, основанные на различных математических концепциях. Прогнозная аналитика — это, как правило, просчитывание вероятности какого-то события в будущем. Например, утверждение «С вероятностью 80% рынок акций на следующей неделе будет расти» — это результат прогнозной аналитики.
Предписательная аналитика. Этот метод считается самым прогрессивным. В нём автоматическая система дает рекомендации к действиям на основе предыдущих анализов. Метод отвечает на вопрос «как поступить?».
Примеры использования big data
Big data используют практически во всех областях жизни. Вот примеры по разным сферам.
Бизнес. Все крупные компании работают с большими данными. В Америке больше 55% компаний из разных сфер работают с технологиями. В Азии и Европе — 53% компаний. Бизнес, который не использует big data, упускает выгоду.
Производитель спецтехники Caterpillar признался, что его дистрибьюторы ежегодно упускали 9–18 миллиардов долларов прибыли, потому что не работали с big data.
Банковская сфера. Fintech — одно из самых быстроразвивающихся направлений. Благодаря большим данным банки могут оказывать совершенно новые услуги, которые раньше были недоступны: выявлять мошеннические схемы, автоматически анализировать кредитоспособность и вести бухгалтерию.
Маркетинг. Маркетинг всегда был и есть драйвером big data: решения в нём принимают на основе данных. Их используют, например, чтобы анализировать посетителей сайта, определить предпочтения клиента, понять, успешна ли реклама.
Медицина. Современные методы анализа данных, в том числе компьютерное зрение, открывают дорогу одному из самых перспективных направлений на текущий момент. Анализ показателей жизнедеятельности человека может изменить нашу жизнь, как когда-то социальные сети.
Автомобилестроение. Автопилоты, роботы-доставщики, автоматизированное производство машин — это то, что уже существует сегодня. Без больших данных это было бы невозможно.
Ретейл. Наряду с fintech и маркетингом исторически ретейловое направление имеет очень много транзакционных данных. Их можно использовать, чтобы улучшать пользовательский опыт в магазинах и онлайн. Например, раскладывать товар на полках на основе истории продаж и карты перемещения людей по магазину.
Наем сотрудников. Автоматическое чтение резюме, выявление талантов среди десятков тысяч других резюме, чат-боты для базового скрининга сотрудника — это небольшая часть применения big data в найме.
Госструктуры. Могут использовать большие данные, чтобы управлять городами. С помощью big data можно создавать «умные» города с интеллектуальной системой поддержки жизни горожанина на протяжении его жизнедеятельности.
Медиа. Большие данные напрямую влияют на величину выручки в этом секторе. Знания о том, какие заголовки чаще интересуют определенную когорту пользователей, какой тип новостей или развлечений интересен, анализ пользовательского поведения — это возможность больше зарабатывать. Например, онлайн-стриминговые сервисы типа нетфликса используют большие данные даже для создания сериалов, а не только для продвижения в сети.
Логистика. Big data помогают находить оптимальный путь на длинные дистанции, оптимизировать движение морского транспорта. Есть компании, которые используют дополненную реальность в складском учете.
Кто работает с большими данными
Есть несколько профессий, в основе которых — работа с большими данными.
Data-инженер. Чтобы начать работать с большими данными, необходимо их собрать, организовать место хранения, подготовить и обработать эти данные. Всё это обеспечивает инженер, который строит процессы работы с big data.
Data-инженер — это программист, у которого есть опыт работы с различными базами данных и высоконагруженными системами обработки данных.
Data-сайентист. Это эксперт в анализе данных, математической статистике, теории вероятности. Его главная задача — построение математических моделей для прогнозирования, оптимизации и других задач. Data-сайентист в меньшей степени погружен в бизнес-процессы компании, потому что сфокусирован на техническом и математическом решении задач.
Аналитик данных. Это эксперт в анализе данных и бизнес-процессах компании, в которой он работает. Аналитик разбирается в задачах и проблемах бизнеса, знает, какие данные доступны для анализа. Он является связующим звеном между бизнесом и миром больших данных.
Станьте аналитиком данных в два раза быстрее
Ускоренный курс для тех, кто хочет быстрее перейти на удаленку
Сложности применения big data
Несмотря на плюсы и большие перспективы big data, в работе с ними есть сложности:
- Большие данные требуют инфраструктуру для хранения. Часто под хранение данных выделяют отдельный центр обработки данных (ЦОД).
- Чтобы создать аналитическую модель (например, некоторые виды нейронных сетей), нужно очень много времени для обучения. Так, чтобы обучить современную сеть создавать изображения на основе текстового описания, используют массив данных размером 270 терабайт. Обучение такой сети может занять около недели.
- Знание технологий обработки больших данных очень важно, но так же важно понимать предметную область. Иногда понять, «что нужно?», сложнее, чем «как это сделать?».
Источник: sky.pro