Эй, читатели! Сегодня мы будем сосредоточены на важной метрике ошибок для алгоритмов классификации – F1 балла в Python. Итак, давайте начнем! Что такое F1.
Эй, читатели! Сегодня мы будем сосредоточиться на важной метрике ошибок для алгоритмов классификации – F1 Оценка в питоне. Итак, давайте начнем!
Что такое балл F1?
F1 Оценка это Классификация ошибки метрики Что, как и любая другая ошибка, метрика помогает нам оценить производительность алгоритма. Это помогает нам оценить производительность модели обучения машины с точки зрения бинарной классификации.
Это комбинация Точность и Напомним Метрики и называются гармоническим средством точности и вспоминания. Он в основном используется в случаях, когда данные неразбавлены, или в наборе данных есть двоичная классификация.
Посмотрите на формулу ниже
F1 = 2 * (precision * recall) / (precision + recall)
Оценка F1 увеличивается, поскольку значение точности и взыскания поднимается для модели.
Высокий балл указывает на то, что модель хорошо разбирается с точки зрения обращения с задачей дисбаланса класса.
F1 — Формула успеха в бизнесе
Давайте сейчас сосредоточимся к практической реализации того же в предстоящем разделе.
Применение балла F1 на набор данных кредита
Здесь мы будем реализовать метрики оценки по прогнозированию кредита. Вы можете найти набор данных здесь Отказ
1. Загрузите набор данных
Что считается «хорошей» оценкой F1?
При использовании моделей классификации в машинном обучении общей метрикой, которую мы используем для оценки качества модели, является F1 Score .
Этот показатель рассчитывается как:
Оценка F1 = 2 * (Точность * Отзыв) / (Точность + Отзыв)
- Точность : правильные положительные прогнозы по отношению к общему количеству положительных прогнозов.
- Вспомнить : исправить положительные прогнозы по отношению к общему количеству фактических положительных результатов.
Например, предположим, что мы используем модель логистической регрессии, чтобы предсказать, попадут ли 400 разных баскетболистов из колледжа в НБА.
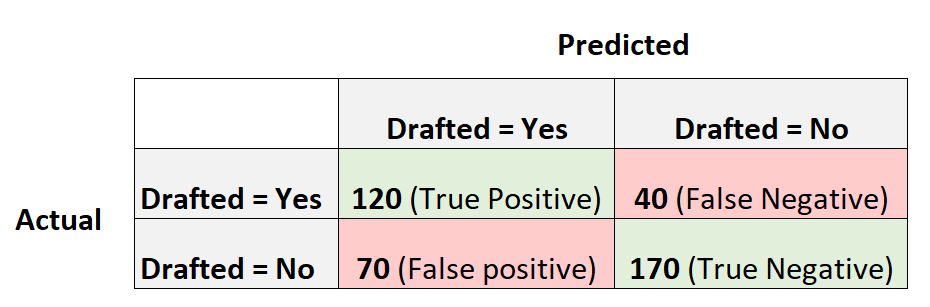
Следующая матрица путаницы суммирует прогнозы, сделанные моделью:
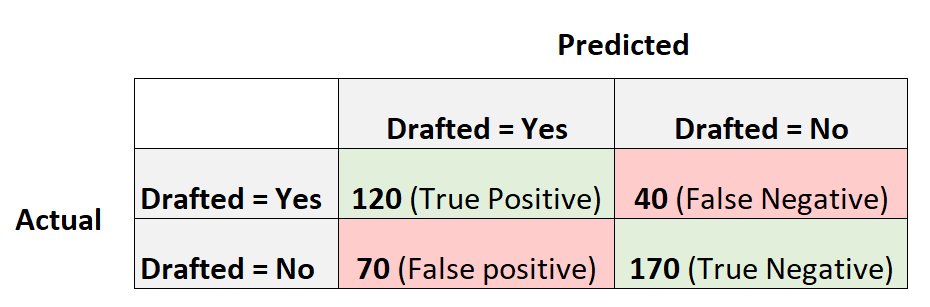
Вот как рассчитать оценку F1 модели:
Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат) = 120/(120+70) = 0,63157
Отзыв = истинно положительный / (истинно положительный + ложноотрицательный) = 120 / (120 + 40) = 0,75
Оценка F1 = 2 * (0,63157 * 0,75) / (0,63157 + 0,75) =.6857
Что такое хороший результат F1?
У студентов часто возникает вопрос:
Что такое хороший результат F1?
Проще говоря, более высокие баллы F1, как правило, лучше.
Напомним, что оценки F1 могут варьироваться от 0 до 1, где 1 представляет модель, которая идеально классифицирует каждое наблюдение в правильный класс, а 0 представляет модель, которая не может классифицировать какое-либо наблюдение в правильный класс.
СТАНОК ДЛЯ БИЗНЕСА, КОТОРЫЙ ПРИНЕСЕТ МИЛЛИОН! БИЗНЕС БЕЗ ВЛОЖЕНИЙ! #shorts
Чтобы проиллюстрировать это, предположим, что у нас есть модель логистической регрессии, которая создает следующую матрицу путаницы:
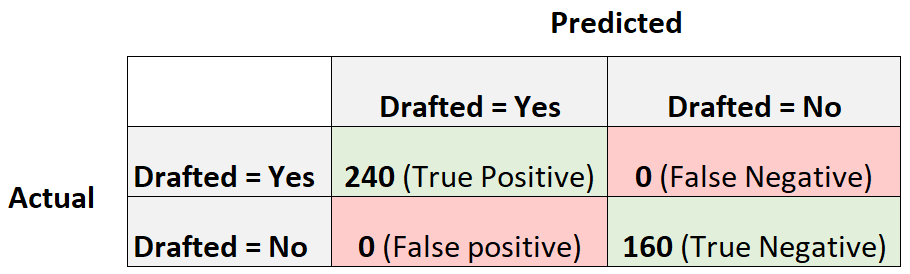
Вот как рассчитать оценку F1 модели:
Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат) = 240/(240+0) = 1
Отзыв = Истинно положительный / (Истинно положительный + Ложноотрицательный) = 240 / (240+0) = 1
Оценка F1 = 2 * (1 * 1) / (1 + 1) = 1
Оценка F1 равна единице, потому что она способна идеально классифицировать каждое из 400 наблюдений в класс.
Теперь рассмотрим другую модель логистической регрессии, которая просто предсказывает, что каждый игрок будет выбран на драфте:
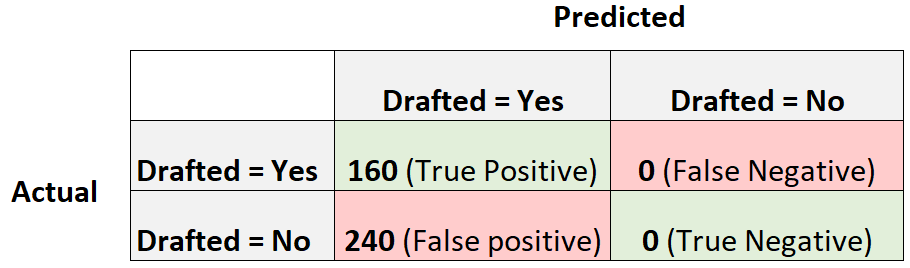
Вот как рассчитать оценку F1 модели:
Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат) = 160/(160+240) = 0,4
Отзыв = Истинно положительный / (Истинно положительный + Ложноотрицательный) = 160 / (160+0) = 1
Оценка F1 = 2 * (0,4 * 1) / (0,4 + 1) = 0,5714
Это будет считаться базовой моделью , с которой мы могли бы сравнить нашу модель логистической регрессии, поскольку она представляет собой модель, которая делает одинаковый прогноз для каждого отдельного наблюдения в наборе данных.
Чем больше наша оценка F1 по сравнению с базовой моделью, тем полезнее наша модель.
Напомним, что наша модель имела оценку F1 0,6857.Это не намного больше, чем 0,5714 , что указывает на то, что наша модель более полезна, чем базовая модель, но ненамного.
О сравнении результатов F1
На практике мы обычно используем следующий процесс, чтобы выбрать «лучшую» модель для задачи классификации:
Шаг 1: Подберите базовую модель, которая делает одинаковый прогноз для каждого наблюдения.
Шаг 2: Сопоставьте несколько разных моделей классификации и рассчитайте балл F1 для каждой модели.
Шаг 3: Выберите модель с наивысшим баллом F1 в качестве «лучшей» модели, убедившись, что она дает более высокий балл F1, чем базовая модель.
Не существует конкретного значения, которое считается «хорошим» результатом F1, поэтому мы обычно выбираем модель классификации, которая дает наивысший балл F1.
Источник: www.codecamp.ru
Оценка F1 (F1 Score)

Оценка F1 (F-мера) – среднее значение Точности измерений (Accuracy) и Отзыва (Recall) с Весами (Weight) при наличии. F1 обычно более полезна, чем точность измерений, особенно если распределение классов неравномерно. Оценка F1 вычисляется по формуле:
Когда мы получаем данные, то после очистки и предварительной обработки, первым делом передаем их в модель и, конечно же, получаем результат в виде вероятностей. Но как мы можем измерить эффективность нашей модели? Здесь Матрица ошибок (Confusion Matrix) и оказывается в центре внимания.
Матрица ошибок – это показатель успешности классификации, где классов два или более. Это таблица с 4 различными комбинациями сочетаний прогнозируемых и фактических значений.

Давайте рассмотрим значения ячеек (истинно позитивные, ошибочно позитивные, ошибочно негативные, истинно негативные) с помощью «беременной» аналогии:

Истинно позитивное предсказание (True Positive, сокр. TP)
Вы предсказали положительный результат, и женщина действительно беременна.
Истинно отрицательное предсказание (True Negative, TN)
Вы предсказали отрицательный результат, и мужчина действительно не беременен.
Ошибочно положительное предсказание (ошибка типа I, False Positive, FN)
Вы предсказали положительный результат (мужчина беременен), но на самом деле это не так.
Ошибочно отрицательное предсказание (ошибка типа II, False Negative, FN)
Вы предсказали, что женщина не беременна, но на самом деле она беременна.
Точность измерений вычисляется по формуле:
Отзыв вычисляется по формуле:
Теперь, когда у нас есть базовое представление о том, как рассчитывается F1, рассмотрим пример.
Оценка F1: SkLearn
Давайте посмотрим, как SkLearn считает F1. Для начала импортируем необходимые библиотеки:
from sklearn.metrics import f1_score
Ниже мы объявим два списка – истинные Классы (Class) y_true шести Наблюдений (Observation) и предсказанные y_pred :
y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1]
Вызовем соответствующий модуль для вычисления оценки. Параметр average требуется, если у целей более двух классов, и weighted означает, что набор данных несбалансированный.
f1_score(y_true, y_pred, average=’weighted’)
Метрика подспудно вычислила точность и отзыв, а затем выполнила подстановку в формулу F1:
0.26666666666666666
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.

Подари чашку кофе дата-сайентисту ↑
Источник: www.helenkapatsa.ru