В статье вы узнаете подробнее о ML: на какие этапы делится процесс машинного обучения и как качество используемых данных влияет на эффективность ML-моделей.
Значение машинного обучения (Machine Learning) растёт. Кто быстрее осваивает ML, тот получает преимущества над конкурентами. Компании часто покупают технологии, чтобы разработать стратегии, но не оценивают готовность данных.
Machine Learning продолжит расти и влиять на бизнес-процессы. Бизнес получит пользу от технологии, если соберёт основу — точные данные. Количество и качество информации влияет на результаты ML.
Используйте машинное обучение на полную мощность
Для работы моделей машинного обучения понадобится достаточное количество релевантных данных. Чем лучше информация, тем продуктивнее работает ML. С неточными, неполными и противоречивыми данными модель выдаёт неправильные результаты. Проверяйте качество информации перед использованием.
Точность прогнозов модели влияет на принятие решений и рост показателей бизнеса. С корректными данными уменьшается риск погрешностей. Если исходные сведения необъективные по отношению к группе N, итог тоже окажется предвзятым. Для машинного обучения нужны разные и репрезентативные наборы сведений.
Как стать ML-инженером? Почему Machine Learning — это будущее бизнеса. Код и кофе, s 4 ep 6.
Модели ML опираются на базу информации, чтобы продолжать обучаться и совершенствоваться. Новые сведения нужны для адаптации и корректировки прогнозов с учётом новых тенденций и закономерностей.
Термины технологии машинного обучения
Алгоритмы — это математические вычисления, которые принимают и корректируют входные данные. Алгоритмы справедливо назвать «мозгом» машинного обучения.
Модель определяет взаимосвязь между входными данными (признаками) и информацией, которую дата сайентисты пытаются предсказать — маркированными данными (доказательствами). К маркированным относят, например, площадь дома или количество продаж за день.
Наборы используются для обучения моделей. Чем больше информации, тем точнее прогнозирование.
Обучение в ML — корректировка модели на основе поступающей информации. Процесс заканчивается, когда дата сайентисты уверены в точности предсказаний модели. В итоге появляется новая информация, которая актуальна в бизнес-среде.
К примеру, распознавание лиц работает, потому что модель обучена на тысячах фотографий и примерах из жизни. Если соцсеть заявляет, что распознает человека на фото «в большинстве случаев», то такой результат успешный.
Big Data — основа для платформ и приложений ML, без которой не будет уверенного результата. Обработанная, очищенная и структурированная информация — обязательное условие для успеха решения задач машинного обучения.
Этапы машинного обучения
Стандартный процесс ML улучшает клиентский опыт, усиливает персонализацию, сегментацию, прогнозирование оттока клиентов и аналитику. Для машинного обучения компании выбирают платформы клиентских данных, которые собирают достаточно информации о клиентах. Например, Altcraft Platform объединяет разные источники сведений в едином окне.
Краткий ликбез по ML метрикам и их связи с бизнес-метриками
Единый цифровой профиль клиента в Altcraft Platform
Три фазы машинного обучения
Фаза № 1. Это обработка входных данных, которая происходит до получения подготовленного набора информации, или надёжной основы, как упоминалось выше. Сначала определяют источники информации. После работают технологии, которые умеют быстро обрабатывать, проверять и очищать объёмы данных.
Этот этап называют «очисткой данных», и на него уходит большая часть времени и усилий дата сайентистов. Когда входная информация неправильно отформатирована или поступила без нужного контекста, обучение неполноценное: модель не выдаст точных результатов.
Фаза № 2. Здесь окупаются затраты времени и ресурсов на очистку данных на первом этапе. Начинают работать алгоритмы машинного обучения, для которых сведения становятся «тестовыми наборами». Такие комплекты появляются постоянно, поэтому процесс повторяется. Чем больше набор данных, тем лучше модель учится. Дата сайентисты проверяют результаты в течение всего процесса.
Наблюдают за реакцией модели на новую тестовую информацию и подтверждают, что предсказания релевантные.
Фаза № 3. Начинается, когда на предыдущем уровне модель показала надёжность. В третьей фазе начинается «производство»: ML работает с данными в режиме real-time, даёт прогнозы и влияет на бизнес-решения.
Цепочка поставок данных в машинном обучении
Цепочка поставки данных — это сбор, обработка и преобразование данных в основу, которую алгоритмы машинного обучения берут для прогнозов и решений. Точность моделей ML зависит от качества и количества данных в цепочке.
Шаг 1: Сбор
На первом шаге информация собирается из разных источников: баз данных, датчиков, платформ, соцсетей и других. Нужна релевантная и надёжная информация со сценариями и проблемами, которые решают модели ML.
Подготовка данных о клиентах для проектов машинного обучения — не всегда простая задача. Особенно с разрозненными источниками информации вне и внутри организации. Для точности выберите данные, которые с большей вероятностью доведут до цели — предсказания для решения бизнес-задачи. Это не просто возможность реагировать на брошенные корзины или выдавать рекомендации, не сбор последней информации и её усреднение, а предсказание будущего.
Для брендов входные данные включают сведения о веб-активности, покупках и взаимодействии со службой поддержки, поведении пользователей в мобильных приложениях.
Сценарии, в которых информацию не так просто получить, дополняют слоем информации (Data Layer) из слоя хоста (Hosted Data Layer). Статические данные работают как дополнение динамического слоя данных на странице сайта, где информацию собирают в режиме real-time.
Также с учётом новых правил (GDPR и других) компании должны получать согласие на использование персональных данных. Убедитесь, что информация для машинного обучения собирается правильно и законно.
Шаг 2: Стандартизация и нормализация
После сбора данные стандартизируют и преобразовывают в формат, который умеют обрабатывать алгоритмы машинного обучения. Приводят к единообразию независимо от источника или типа. Удаляются дубликаты, неактуальные сведения, заполняют недостающие значения. Данные преобразуют в стандартный формат: CSV или JSON, который умеют обрабатывать алгоритмы машинного обучения.
Для точных результатов алгоритмам машинного обучения нужна последовательная и единообразная информация. Иначе появляются ошибки или смещение в моделях. Например, если данные содержат недостающие значения или несовместимые форматы, алгоритмы ML выдадут неточные или ненадёжные прогнозы.
На этап очистки и нормализации «грязных» данных у дата сайентистов уходят десятки часов. Даже приходится принимать решения по неполной и некорректной информации, которую исследователи не всегда понимают.
Специальные расширения на стороне клиента манипулируют данными и стандартизируют в источнике информацию, которая не подходят для ML. Правильно делать это в браузере клиента по мере поступления сведений со стороны сервера.
Спецификации событий — проверка качества входящих наборов данных в real-time режиме. Запускается, когда возникают новые события. За минуты тестируется чистота информации и соответствие требованиям ML.
Основа данных для машинного обучения и бизнеса
Надёжные данные пригодятся не только для работы машинного обучения. Точная и проверенная информация — это обоснованные data-driven решения. Если вести бизнес без опоры на данные, риск финансовых потерь увеличивается.
Полная и точная информация о клиентах подскажет, как адаптировать продукты, услуги и контент в каналах продвижения, чтобы удовлетворить потребности клиентов.
Основа данных приводит к росту бизнеса, упрощает автоматизацию повторяющихся задач и освобождает время сотрудников, которые начинают заниматься стратегиями, а не рутиной. В итоге растёт производительность, экономится бюджет и увеличивается рентабельность. С данными проще выявлять тенденции и закономерности в бизнес-сфере и быстрее реагировать на изменения на рынке: запускать новые продукты, услуги и принимать обоснованные решения.
Также без правильного сбора, организации и управления информацией бизнес не будет соответствовать требованиям GDPR и CCPA.
Работайте с данными грамотно в Altcraft Platform. Храните информацию в безопасности в одном окне на вашем сервере. Повышайте лояльность и уровень продаж. В платформе также доступен ML модуль — Best Send Time. Вы сможете настроить отправку писем таким образом, что ваши клиенты будут получать сообщения в удобное для них время.
Это значительно повысит вовлечённость подписчиков.
Подписывайтесь на наш телеграм-канал. Там вы найдёте актуальные новости в области digital-маркетинга, полезные статьи и интересные исследования. Будьте в теме вместе с нами 🙂
Источник: spark.ru
Как ускорить вывод ML-моделей в 4 раза, или Как может выглядеть экосистема МLOps в банке
Привет, я Андрей Качетов, Head of ML Operations в Альфа-Банке. Отвечаю за опромышливание всех ML-моделей в банке, строю новую платформу MLOps, а также формирую единый подход для работы с модельными данными (Feature Store).
В статье, без картинок с «бесконечностями» Ops’ов, расскажу, как может выглядеть полноценный конвейер MLOps, что может уметь и немного о том, как мы пришли к максимальной автоматизации процесса вывода моделей в промышленную эксплуатацию.

Зачем нам нужен MLOps?
Не говоря за ритейлеров или телеком-операторов, использование машинного обучения в банковских процессах — мастхэв, который приносит вполне осязаемую пользу, например, уменьшает вероятность дефолта.
Однако важна ещё и скорость «приземления» таких прогнозов и оценок на конкретные бизнес-процессы. Если компания может быстро обновлять модели, то она может быстрее реагировать на изменения рынка и поведения игроков, корректировать соответственно модели и стимулировать в итоге рост если не прибыли, то выручки. Time2Market сейчас во главе угла любой инновации.
Здесь и появляется необходимость в конвейере.
Автоматизация — традиционный способ повышать производительность команд разработки, а также оптимизировать издержки, снижать риски инцидентов и повышать устойчивость систем. Такой конвейер и есть MLOps — комплексное управление жизненным циклом моделей машинного обучения в промышленной эксплуатации (в продакшене).
Если брать совсем грубо, то MLOps — это использование и некоторая адаптация DevOps-подходов применительно к работе с ML — процесс непрерывной поставки или промышленного развертывания моделей.
DevOps — процесс непрерывной разработки ПО
MLOps = Machine Learning (Машинное обучение) + DevOps
Процесс беспрерывной накатки кода в промышленную среду.
Автоматизированное управление жизненным циклом ПО.
Разработка (Development) + эксплуатационное сопровождение (Operations).
Стандартизация непрерывной поставки/разработка и промышленное развертывание моделей ML
Результат в MLOps обеспечивается совокупностью факторов:
- качество входных данных (зависит от Дата-Инженеров – Data Engineers, DE);
- разработка ML-модели (зависит от «моделистов» — Data Scientists и DS);
- разработка и развертывание ML-решения (за это отвечают ML-инженеры);
- управление инфраструктурой (здесь «правят» DevOps-инженеры).
Другими словами, в фокусе MLOps сразу и модели, и инструменты машинного обучения, и инфраструктура для их применения, и инструменты деплоя (как в обычном DevOps) — версионирования, хранения конфигураций, автотестирования. В MLOps мы быстро накатываем изменения в модели с помощью нескольких разных идентичных сред.
Схематично платформа для автоматизированной разработки ML может выглядеть так.

С такими платформами работают DS, DE и MLE «в комплексе».

- Data Scientist занимается поиском закономерностей в больших массивах данных, анализирует их и прогнозирует будущие значения.
- Data Engineer разрабатывает, тестирует и поддерживает инфраструктуру данных, занимается очисткой, обработкой и трансформацией данных для DS.
- ML Engineer разворачивает модели машинного обучения в промышленной среде.
Отчасти ML-инженеры – это специалисты на стыке между моделистами (DS) и разработчиками. У нас в команде MLOps их сегодня 6. Но так было не всегда.
Как было до экосистемы?
Два года назад в Альфа-банке уже существовала определенная практика разработки моделей ML и вывода их в промышленную эксплуатацию. Например, модели работали в процессах принятия рисковых решений, проверок клиентов и их операций, а также в чат-ботах.
Все эти процессы исполнялись в различных автоматизированных системах. Каждая из них должна была самостоятельно интегрировать модель в свой исполняющий код.
Такой процесс требовал вовлечения нескольких разработчиков и существенных временных затрат, в том числе, на постановку задачи, аналитику и тестирование. Также он накладывал свои требования на архитектуру систем и состав их компонент. А некоторые модели (например, нейросетевые) вообще не могли исполняться в существовавшей на тот момент инфраструктуре — для их работы требовалась непрерывная поставка больших данных или специфичная среда исполнения кода.
Были свои сложности и в организации работы с данными для обучения моделей. Например, под каждую ML-модель нужно создать свой набор данных (датасет), потом убрать лишние признаки (фичи) и протестировать точность предсказаний. Иногда при изменении датасета нужно собирать данные заново. Это неудобно, если нужно переиспользовать уже собранные фичи для обучения новых моделей.
Кроме того, зачастую разные DS просто по-разному собирают данные для своих моделей. Например, понятное всем в банке определение дефолта заёмщика может считаться десятком разных способов и учитывать или не учитывать особенности законодательства, принимаемого со временем.
В результате таких разрозненных действий, множества вовлекаемых специалистов и различных участвующих систем, вывод ML-модели в пром мог занимать целый квартал и даже больше.
Другими словами, системы жили своей изолированной (как во всем знакомом зоопарке) жизнью. В них изолированно же выводились какие-то модели. Необходимость ускорения, чтобы сохранять конкурентоспособность на усложняющемся и динамичном рынке, явно назрела.
Как строилась экосистема ML в банке
Ускорить разработку и развертывание ML-моделей помогла созданная с нуля платформа, на которой можно:
- вести трекинг ML-экспериментов;
- оптимизировать параметры ML-моделей;
- создавать и запускать пайплайны;
- и организовывать инференс (код исполнения).
Ну, и главное, — обеспечить возможность для переиспользования или воспроизведения обучения. Важно, чтобы процесс разработки моделей был стандартизирован на стороне DS, код соответствовал заявленным критериям и проходил автоматическую проверку.
Для этого у нас сейчас есть:
- СРМ или MDP (Model Development Platform — Среда Разработки Моделей): новый флагман модельной разработки в банке, база для модельной разработки в банке.
- СИМ (Система Исполнения Моделей): оптимизирует и ускоряет процессы вывода моделей в промышленную эксплуатацию, включая их тестирование (в проме сейчас уже 60 моделей).
- Feature Store как настоящий маркетплейс фичей, которые используется моделями машинного обучения и аналитиками банка.
Это наша экосистема ML в банке.
Все три системы разрабатывались параллельно. СИМ разрабатывали с участием команды вендора, а MDP и FS – силами внутренних команд.
СИМ: Система Исполнения Моделей
Началось всё с нее. СИМ разрабатывалась примерно год, из которых примерно полгода заняли дискуссии, на которых мы стремились прийти к единому пониманию необходимого инструментария и функциональности системы.
Обсуждались все детали:
- что будет делать подрядчик (решили, что берёт на себя всю разработку системы);
- каким должно быть архитектурное решение;
- что использовать из лучших практик с рынка с минимальными издержками (какие фреймворки, какие подходы, какой софт);
- какие функциональные области необходимы;
- как и кем будут настраиваться стенды (подрядчик или внутреннее ИТ, на ком лидерство) и пр.
Параллельно шёл тендер на выбор поставщика услуг.
Ещё важно учесть, что сама по себе СИМ никому не нужна, если с ней не могут работать. Поэтому чуть больше квартала ушло на то, чтобы встроить СИМ в IT-процессы банка. Зато сейчас, когда СИМ уже в проме, любой пользователь внутри банка может запросить результат вычисления ML-модели и применить его в своем процессе. Доступ к разработанным моделям предоставляется по API-сервису: запрос к модели идет через определенный URL (в него включено имя приложения и версия API), и она даёт на него ответ.

Процесс выведения любой ML-модели в промышленную эксплуатацию автоматизирован — весь процесс прозрачный, быстрый и защищенный. Деплой разработанных моделей идёт по стандартному циклу: от получения, валидации и подготовки данных до разработки кода модели, её обучения и деплоя.
После запуска СИМ скорость внедрения моделей теперь составляет 3-4 недели. Новая цель — ускориться еще больше и дойти до показателя в 4-5 рабочих дня.
СРМ: Среда Разработки Моделей
Среда разработки моделей (MDP) — программно-аппаратный комплекс для разработки и обучения моделей ML. В СРМ есть всё для разработки: Kubernetes, фреймворки, библиотеки, хранилка, Jupiter Notebook, VS-код, пайплайны CI/CD через Jenkins, Cassandra для горячего хранения. В этой среде можно подключиться к единому хранилищу данных (КХД), разработать, запустить и протестить код, который будет работать в бою также — ведь среды разработки и исполнения полностью идентичные.
СРМ начала разрабатываться параллельно с СИМ. Ситуация тогда сложилось несколько курьезная — сосредоточившись на дискуссиях вокруг СИМ, почти упустили из вида тот факт, что единой среды, где все DS готовили бы код, вообще-то тоже нет. По сути каждый работал на своих вычислительных мощностях. Но раз уж начали автоматизировать и унифицировать — то и здесь решили создать единую среду для исследований и разработки.
Платформа разрабатывалась внутренней командой. Решение было построено примерно за 8 месяцев — на базе единого JupiterHub и MLflow. Ещё несколько месяцев занял процесс выстраивания сквозного технологического единения систем с СРМ. Наша среда разработки просто космолет, и чтобы он полетел надо его тонко настроить.
Feature Store
Feature Store — это и система, и новая парадигма непрерывной доставки данных для разработки моделей. В неё входят 3 компонента:
- FS ETL — единый процесс создания фичей.
- FS Registry — визуализация метаинформации о фичах.
- FS Datamart — единый интерфейс получения фичей (здесь реализован поиск и есть «витрина» доступных фичей).
Её разработка заняла чуть больше года, и ей полностью занималась внутренняя команда MLOps. На сентябрь 2021 года это всего 3 человека: два разработчика и техлид (которые начали продвижение проектов СИМ и СРМ). Сейчас «МЛОпсов» уже 21: это и ML-инженеры, и DevOps’ы, и QA, и тимлиды.
Feature Store собирает фичи по определенному процессу так, чтобы они применялись в системе исполнения моделей так же, как в системе разработки моделей. Feature Store получился фактически как онлайн-«магазин» данных, ассортимент которого постоянно расширяется. С его помощью можно организовать централизованную работу с фичами, чтобы гарантировать повторяемую логику их сбора для обучения разных моделей разными командами, для работы с выверенными данными высокого качества в разных департаментах.
На платформе Feature Store DS’ы могут просматривать все имеющиеся признаки «в одном окне» и подбирать для себя нужные, а не создавать повторно дубли.

Такое переиспользование существенно ускоряет работу с данными, их качество теперь проверено (и по сути гарантировано). Ну, и общий time-to-market разработки ML-моделей улучшается — пока до 3-4 недель, но есть потенциал ускориться вообще до одной.
Благодаря тому, что все фичи и датасеты хранятся централизованно, можно собирать большое количество различных метаданных, анализировать «популярность» переменных, вести мониторинг и статистику применения — какие фичи сколько раз, кем и где использовались. Вся информация о фичах, старте расчетов, статусе работы сохраняется автоматически.
Основные потребители Feature Store в банке:
- Дата-инженеры — выполняют расчёт фичей и создают широкую выборку фичей для моделей.
- DS-специалисты — работают с данными и подбирают фичи для моделей. Если нужной им фичи нет — «заказывают» её появление в хранилище.
- ML-инженеры — используют фичи для упрощения вывода ML-моделей в пром.
- Аналитики — используют эталонные данные для целей бизнес-аналитики и оптимизации процессов.
Ключевые вехи разработки экосистемы ML кратко.
Сентябрь 2021 — старт разработки СИМ выбранным вендором.
Ноябрь 2021 — обсуждение концепции Feature Store. Выбирая из разных вариантов (от Open Source решений до полностью кастомной разработки), сначала решили пропилотировать решение Feast с открытым кодом.
Декабрь 2021 — старт эксперимента с Open Source решением Feast — предшественником Feature Store. Неудачных экспериментов, как известно, не бывает, любой результат засчитывается — здесь мы столкнулись с некоторыми сложностями с приземлением готового решения под свои потребности и бизнес-задачи.
Январь 2022 — запуск собственной разработки СРМ (будущей MDP).
Февраль 2022 — проектирование необходимой инфраструктуры, закупка «железа» — bare-metal серверы с GPU. Закупка проходила не без проблем, удалось в итоге, как и всем, получить и запустить его только к сентябрю 2022. На серверах стоит Kubernetes, Jupiter, Grafana и т.д., которые настроены так, чтобы они могли работать с серверами, с GPU, с видеокартами, со средой для DS, как для разработки, так и для внедрения.
Март 2022 — по итогам того самого декабрьского эксперимента решили отказаться от рыночных решений и вендорской разработки в пользу создания собственной платформы Feature Store. Чтобы точно соответствовать всем выявленным потребностям бизнес-пользователей.
Июль 2022 — СИМ выходит в опытно-промышленную эксплуатацию (ОПЭ), на dev среду начинают заезжать первые модели, выявлены и дорабатываются недочеты системы.
Октябрь 2022 — миграция команд DS на новую инфраструктуру ML.
Ноябрь 2022 — СИМ переходит в промышленную эксплуатацию.
Декабрь 2022-январь 2023 — СРМ и Feature Store выходят в ОПЭ и готовятся к эксплуатации.
Как это всё работает, или Сценарии использования СИМ, СРМ и Feature Store
- Допустим, DS понял, какая модель нужна и для каких бизнес-задач, посетил Feature Store и выбрал для себя нужные данные.
- Если чего-то не хватило — дозапросил их у DE, чтобы тот собрал недостающие данные и поместил их также в Feature Store.
- Дальше DS провёл исследование в MDP, подобрал алгоритм и подготовил код модели.
- Если с кодом всё ок, то в этот момент DS ставит задачу на ML-инженера по выводу готовой модели в СИМ, на постоянный расчет.
- ML-инженер проводит код ревью, и если с моделью все ок, DS отправляет её к тестировщикам и деплой.
- Модель проходит функциональное, интеграционное и нагрузочное тестирование, и если на всех этапах отрабатывает корректно, выходит в прод.
- А если обнаруживаются какие-либо ошибки — отправляется на корректировки и доработки, после чего ещё раз тестируется.
Участие людей в этом процессе, благодаря новой платформе, стало минимальным. В целом, конвейер работает отлично, с его помощью выводится 50 моделей в квартал.
Что будет дальше?
Следующие наши шаги и планы на ближайшее будущее:
Подключение все большего числа пользователей к СИМ. Будет наращен объём данных, используемый моделями для работы, чтобы повысить точность их вычислений. А увеличение ресурсных мощностей системы позволит получать ответы за доли секунды, что значительно сократит время на принятие решений.
Создание контура тестирования моделей с промышленными данными. Здесь необходимы, помимо технологических, и определённые организационные шаги, с внесением изменений в существующие производственные процессы банка. А значит, вопрос — какая часть на деле займет больше времени.
Автоматизировать процессы обучения, дообучения и внедрения в пром новой версии модели на базе AutoML (тоже наша собственная разработка).
И, сделать мир ML лучше, конечно же 🙂
Как связаться со мной и узнать больше деталей:
- https://t.me/andriazol
- https://www.linkedin.com/in/andrew-kachetov-9740aa60/
- Как улучшить ключевые метрики банка за счет кассовых чеков ОФД?
- Нейросетевой подход к моделированию транзакций расчетного счета
- Нейросетевой подход к кредитному скорингу на данных кредитных историй
- Как и зачем мы начали искать бизнес-инсайты в отзывах клиентов с помощью машинного обучения
- Багатон как в первый раз
- Как мы заняли первое место в хакатоне ВК «Машинное обучение на графах», где не было графов
- Как я участвовал в соревновании по машинному обучению и занял второе место (и почему не первое)
- Как мы участвовали в чемпионате по DS длиной 3,5 месяца
- Классификация кассовых чеков
- Знакомство с Apache Airflow: установка и запуск первого DAGа
- Не принимай оффер в Data Science, пока…
- Как я занял 13 место из 3500+ участников и стал Kaggle Competition Master
- Подкасты, книги, курс: подборка интересного по Data Science
- «Бесполезные» доклады о том, как кочегарить, инференсить и моделировать LTV: как прошёл Data Science Meet Up #2
- Как перестать волноваться и полюбить хакатоны
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
Источник: habr.com
Зачем продакт-менеджеру изучать ML и AI

Машинное обучение и искусственный интеллект — самые обсуждаемые и горячие темы в технологической среде. Но насколько они релевантны продакт-менеджерам? Нужны ли продактам знания и навыки в ML и AI? Если да, то зачем?
Чтобы найти ответ на этот вопрос, давайте посмотрим, как разные продукты и индустрии изменились благодаря технологиям машинного обучения за последние 10 лет.
Мы подготовили эту статью совместно с соавторами «Симулятора управления ML/AI-проектами» — Ириной Пименовой и Виталием Пименовым , которые более 10 лет работают в сфере ML-технологий.
В симуляторе вы научитесь строить продукты, оптимизировать процессы на основе технологий машинного обучения, приносить через эти технологии пользу бизнесу.
Если после прочтения этого материала вы захотите приступить к практическим действиям по реализации ML/AI-проекта, то переходите по ссылке, чтобы получить в нашем симуляторе необходимые знания и навыки.
Технологические прорывы в ML
За последние десять лет (благодаря росту доступности облачных вычислений, новым мощным чипам, накопленным массивам данных, научным прорывам и инвестициям в исследования) в технологиях машинного обучения произошли существенные прорывы.
Вот несколько интересных примеров.
Компьютеры научились играть в сложные игры
Когда-то давно компьютеры стали лучшими в шахматах, но еще долгое время существовал консенсус, что у них нет шансов в более сложных логических играх, таких как го, а также кибердисциплинах вроде Starcraft. Предполагалось, что на достижение человеческого уровня в этих играх компьютерам понадобится не один десяток лет.
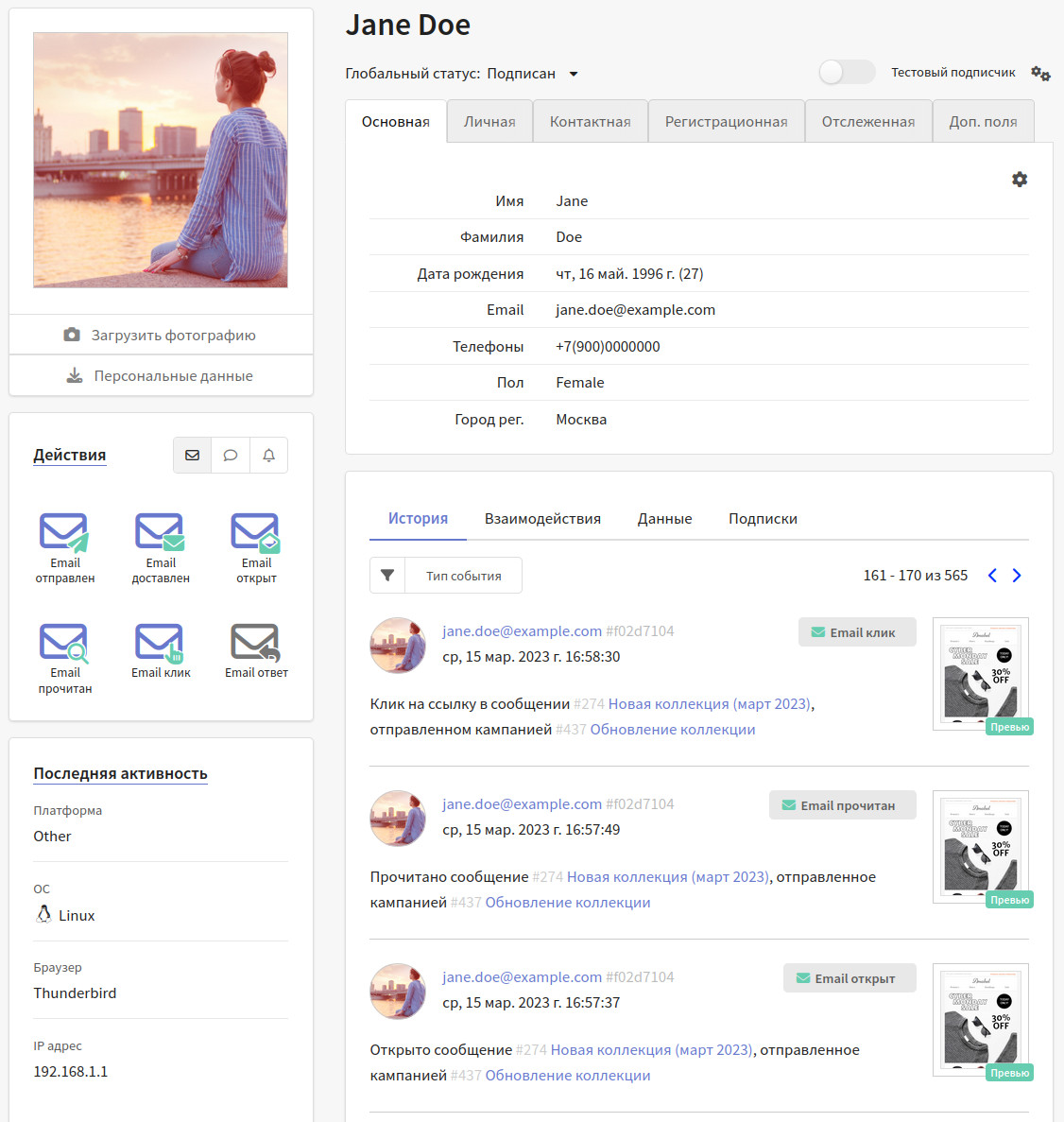
Но уже в 2016 году компьютерная модель, разработанная в Google Brain, впервые выиграла в го у лучшего гроссмейстера мира, а спустя лишь один год — стала непобедимой. Для шахмат интервал между первым выигрышем компьютера у гроссмейстера и последним проигрышем составил куда больше — 10 лет.
Перелом случился, когда модели стали обучаться, играя сами с собой. Это называется Reinforcement Learning. При этом в процесс этого обучения не добавлялось никакого предварительного знания о стратегиях и тактиках от человека.
→ Подробнее о прогрессе компьютера в игре в го можно прочитать по ссылке .
Недавно компьютеры покорили еще одну вершину. Теперь они умеют в « Дипломатию » — игру, основанную на естественном языке. Компания Meta создала AI-агента CICERO , который уже входит в 10% лучших игроков в мире.
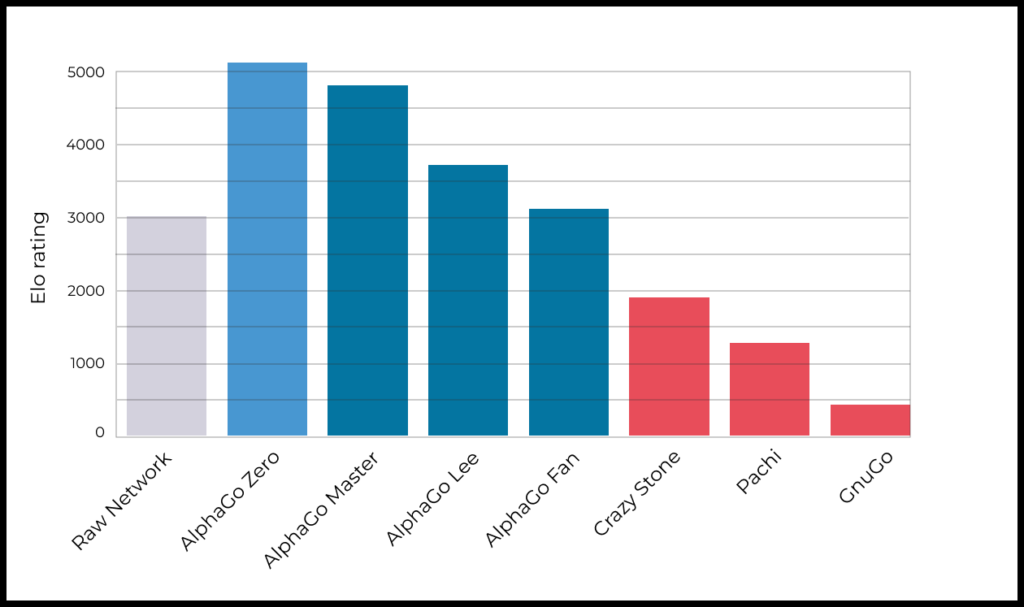
Модели распознавания изображений и речи сперва догнали, а затем и обогнали по точности человека
Еще в 2012 году модель распознавания изображений с помощью ML существенно уступала по эффективности человеку. Но уже в 2015 году в рамках конкурса ImageNet модель впервые показала результат лучше, чем у человека. Ключом к успеху здесь стал прогресс в области глубокого обучения нейронных сетей (Deep Neural Networks).
…А теперь и генерируют изображения и тексты не хуже людей
В 2023 году продукты вроде ChatGPT и Stable Diffusion окончательно захватили внимание людей. Кто-то вне себя от восторга, а кто-то — от страха. Эти генеративные модели рисуют картины, пишут тексты и проходят экзамены на уровне лучших выпускников Стэнфорда.
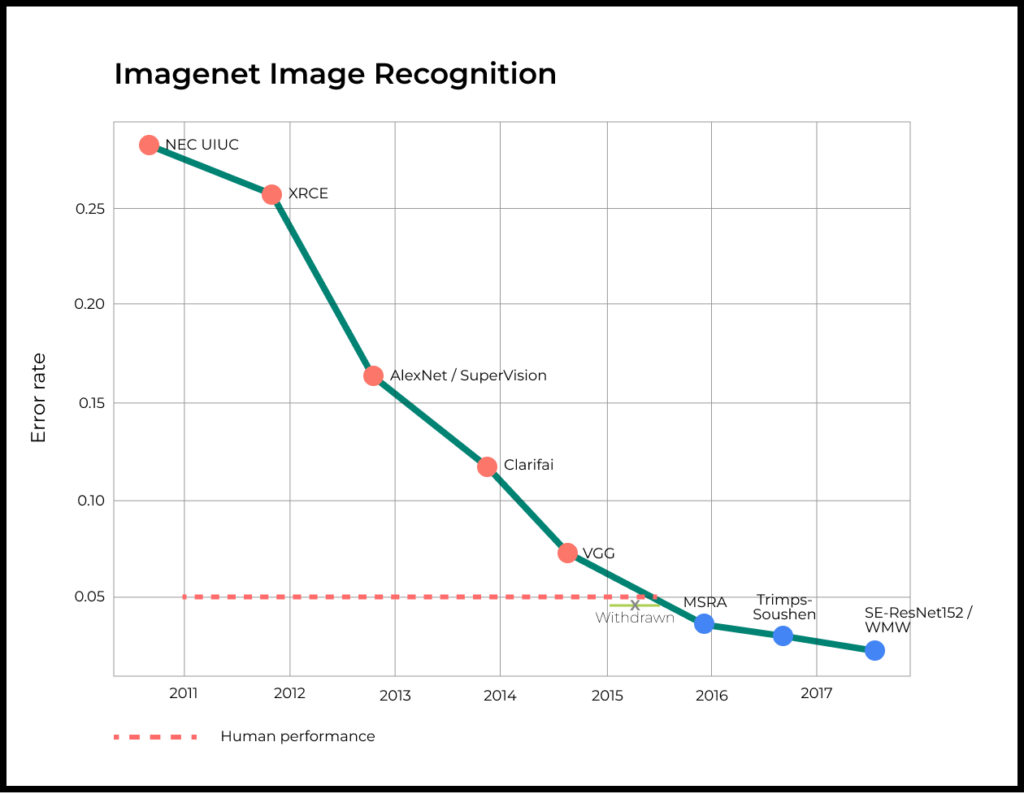
Оцените скорость прогресса.
На графике ниже показаны результате GPT-3.5 и GPT-4 для разных экзаменов. По вертикальной оси показан процентиль среди тех, кто проходил тест. Другими словами, уже сейчас модель GPT-4 проходит большее количество тестов лучше большинства людей .
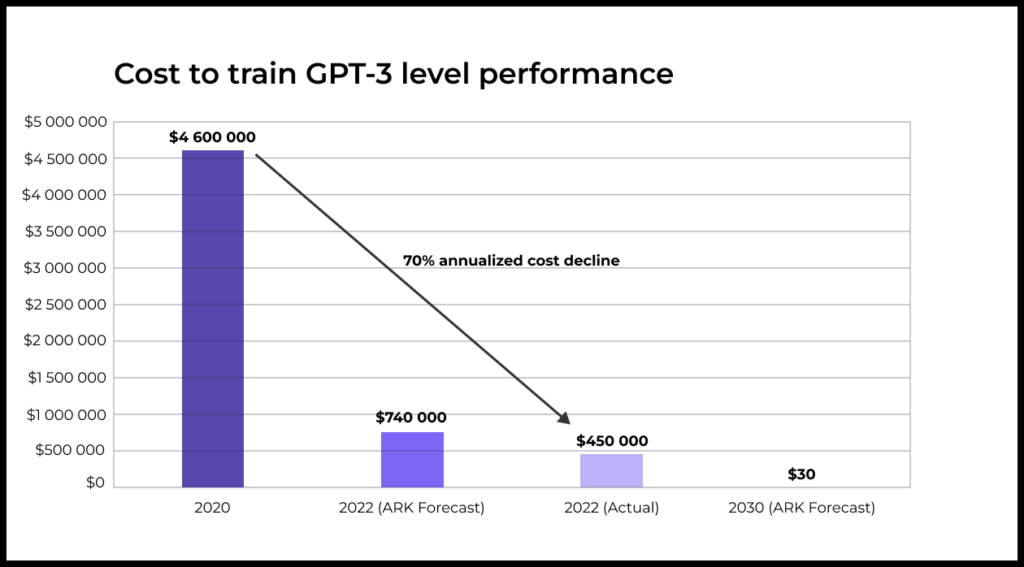
Стоимость обучения моделей падает
Технологии машинного обучения становятся все более доступными, так как стоимость обучения моделей стремительно снижается.
Из отчета OpenAI : объем вычислительной мощности, необходимой для обучения AI-модели в рамках одной и той же задачи, с 2012 года уменьшается в два раза каждые 16 месяцев.
Предполагается, что стоимость обучения модели уровня GPT-3 к 2030 году снизится до $30. Для сравнения: в 2022 году ее обучение стоило $450 000.
Появляется различная инфраструктура для применения ML к прикладным задачам
Сегодня доступно огромное количество инфраструктурных проектов, которые максимально упрощают применение машинного обучения. От AWS и Azure до Hugging Face и множества других инструментов. От инструментов для контроля версий данных и моделей до мониторинга качества данных и моделей в продакшене: DVC, EvidentlyAI, MLflow , WhyLabs, Arize .
Почему эти технологические прорывы влияют на роль продакт-менеджера
Как было раньше
Исторически сфера применимости компьютеров и алгоритмов была ограничена тем, какие есть в наличии оцифрованные данные и какие существуют методы работы с ними.
Как стало теперь
Только за последние несколько лет компьютеры научились видеть, говорить, писать и распознавать. Не просто научились, а вышли на такой уровень, где многие из этих задач они решают лучше людей.
Это расширяет сферу применимости технологий и алгоритмов.
У компьютеров появились способности для того, чтобы понимать окружающий мир. А значит — для разработчиков, предпринимателей и продакт-менеджеров открылось множество новых путей и возможностей для создания ценности и перепридумывания способов решения разных задач.
Прорывы в ML/AI создают огромный потенциал для продуктовых инноваций и для того, чтобы повышать эффективность решения задач в самых разных сферах деятельности (а именно в этом и заключается суть работы продакт-менеджера).
С высокой вероятностью именно эти технологии станут движущей силой в следующие 10–20 лет, что принципиально повлияет на роль продакт-менеджера.
Эра AI повлияет на продуктовую роль не меньше, чем эра мобильных устройств
Сложно обойтись без следующей аналогии, сравнивая степень значимости прорывов в ML/AI для продуктовых индустрий и продуктовых ролей.
В 2007 году мир увидел первый iPhone. За прошедшие годы смартфоны стали крупнейшей платформой, а их возможности стали драйвером для создания множества новых продуктов, перевернувших свои индустрии с ног на голову.
Разумеется, это повлияло на роль продакт-менеджера. Навыки работы с мобильными приложениями и интерфейсами стали важной частью роли. Это открыло путь в профессию для многих и многих новых людей, а также потребовало переобучения тех, кто работал продактом в «домобильные» времена.
Сегодняшние прорывы в технологиях машинного обучения и искусственного интеллекта станут еще один переломным моментом, подобным по своему значению.
Продакт-менеджеры и предприниматели, которые смогут первыми освоить и применить возможности ML/AI-технологий получат существенное конкурентное преимущество.
Почему мы так уверены в этом? Давайте обсудим.
Создание продуктов на основе ML/AI стало доступно всем
Обычно продуктовые инновации появляются с задержкой относительно фундаментальных научных и технологических прорывов.
Иными словами, нужно время (и иногда длительное время) для того, чтобы реализовать технологический потенциал во что-то практически применимое.
Искусственный интеллект был предметом исследований с 1950-х годов, но значительное влияние на продукты и услуги он начал оказывать только в 2010-х годах, спустя половину столетия.
Сегодня машинное обучение уже используется в широком спектре приложений: от рекомендательных систем до самоуправляющихся автомобилей. При этом технологии и необходимые вычислительные мощности доступны практически всем, кто готов прийти — и взять их.
Пример превращения технологической проблемы в продуктовую проблему
В 1999 году Джефф Безос подошел к решению задачи создания интернет-магазина. Для этого ему понадобилось привлечь финансирование, нанять дорогих технических специалистов, закупить серверы, решить множество других проблем.
Это было сложно и дорого. Дело в том, что одна из ключевых проблем для e-commerce в 1999 году лежала именно в технологической плоскости.
Но сегодня это не так. Можно открыть Shopify и запустить свой интернет-магазин практически мгновенно. Технологических барьеров больше нет. Теперь это бизнес-задача и продуктовая задача.
То же самое происходит сегодня и в сфере ML/AI. Технологические проблемы превращаются в продуктовые.
- Построение персональных рекомендаций — одна из наиболее распространенных и успешных областей применения ML в пользовательских сервисах. Сегодня рекомендации на основе ML используются повсеместно: новости, соцсети, стриминги, банки, e-commerce, путешествия, знакомства и так далее. Где-то рекомендации даже ложатся в основу бизнес-модели.
- Модели вроде DALL-E и Stable Diffusion появились в 2022 году. Команда Prisma Labs на основе этих моделей построила приложение Lensa (вы же еще помните стилизованные генеративные аватары почти всех своих друзей и коллег?). За несколько месяцев Lensa стало самым зарабатывающим продуктом в мире в App Store.
- OpenAI представила миру модель GPT-3 в 2020 году. Поверх этих моделей Copy.ai и Jasper построили миллиардные бизнесы, которые помогают компаниям в создании коммерческих текстов. Сама же OpenAI небольшой командой построила ChatGPT, который предположительно стал самым быстрорастущим продуктом в мире.
- По данным GitHub, запущенный поверх модели GPT-3 Copilot сегодня участвует в написании 46% кода и помогает разработчикам, которые используют эту технологию, писать код на 55% быстрее.
Подобные примеры можно приводить еще очень долго.
Словари-переводчики вроде Google Translate сегодня стали основными инструментами, а не вспомогательными, как это было в начале 2010-х.
Технологии распознавания лиц стали мейнстримом (FaceID в iPhone, биометрическая идентификация в банковских приложениях, распознавание документов, приложения вроде FaceApp, отметки людей на фотографиях в соцсетях). Даже в сфере дейтинга начали превалировать ML-алгоритмы для оптимального матчинга людей.
Крупнейшие продукты ринулись переизобретать или улучшать себя на основе новых технологий: новый поиск от Bing, интеграция умных ассистентов в продукты Microsoft и Google, функции саммаризации в Slack, множество новых фичей в Notion.
Технологический прогресс прошлых десятилетий в сфере ML дошел до состояния, когда его достаточно, чтобы команды (без глубокого погружения в саму технологию) могли создавать востребованные продукты для конечных пользователей массового рынка.
Продукты, которые будут вызывать восторг и удивление.