В компаниях, где активно используются информационные технологии, многие полагают, что вопрос непрерывности бизнес-процессов с точки зрения автоматизации информационных потоков должен исходить в первую очередь от ИТ-подразделения.
В компаниях, где активно используются информационные технологии, многие полагают, что вопрос непрерывности бизнес-процессов с точки зрения автоматизации информационных потоков должен исходить в первую очередь от ИТ-подразделения. Однако это заблуждение.
Технологичность нашей жизни растет стремительно, и закрывать глаза на будущие риски по меньшей мере неразумно. Недавний энергетический кризис в Москве со всей яркостью показал, что ключевые структуры не готовы к чрезвычайной ситуации. К сожалению, в России мало кому известны методы подготовки к кризису и даже суть этих методов.
В западном мире инициатива построения процесса управления непрерывностью бизнеса (Business Continuity Management, BCM) исходит от руководителей бизнеса и распространяется по всем подразделениям компании. Задача ИТ — поддержать общий процесс в своем сегменте. Поскольку ИТ-подразделение рассматривается в зрелых компаниях именно как поставщик ИТ-услуг, то его вклад в непрерывность бизнес-процессов сводится к непрерывности предоставления ИТ-сервисов.
Управление непрерывностью. Часть 1.
Весь жизненный цикл становления процесса BCM можно разделить на четыре основные стадии, три из которых относятся к проектной деятельности, а последняя — к операционной.
Инициация
На этой стадии руководство компании инициирует проект по внедрению методов управления непрерывностью бизнеса. Еще до старта проекта фиксируются его границы, распределяются проектные роли, предоставляются необходимые ресурсы, устанавливаются критерии контрольных точек. Инициирование проекта может исходить только от высшего руководства и им же поддерживаться.
Дальнейшая реализация проекта может происходить по любому открытому проектному стандарту, в частности PMI, PRINCE2. Метод управления проектами PRINCE (PRojects IN Controlled Environments) определяет организацию, управление и контроль исполнения проектов. PRINCE был разработан агентством CCTA (Central Computer and Telecommunications Agency) в 1989 году как правительственный стандарт Великобритании для управления проектами в информационных технологиях.
Разработка требований и стратегии
В случае наступления кризиса ИТ-подразделение, очевидно, не сможет предоставлять все услуги на том же уровне, что и при штатной работе. В числе предоставляемых услуг в любой компании всегда будут те, которые поддерживают критичные бизнес-функции.
К примеру, отсутствие сервиса электронной почты вряд ли будет бизнес-критичным при наличии иных средств коммуникации, а вот остановка биллинговой системы будет означать миллионные убытки для операторов сотовой связи. Понятно, что в случае возникновения чрезвычайной ситуации все ресурсы ИТ должны быть сосредоточены именно на бизнес-критичных ИТ-сервисах. Задача этой стадии проекта как раз и заключается в определении списка ключевых ИТ-услуг и минимально необходимого уровня их предоставления в кризисной ситуации. На этой же стадии формируются схемы восстановления ключевых сервисов в кризисных ситуациях и схемы уменьшения рисков, наступления самих катастроф.
Непрерывность бизнеса с Workspace ONE в новых реалиях
Анализ влияния на бизнес
Многие ИТ-директора сталкиваются с ситуацией, когда бизнес-подразделения требуют автоматизировать те или иные бизнес-процессы, причем сами процессы нигде не регламентированы и даже не представлены в виде общих схем. Одна из важных черт проекта по созданию процесса управления непрерывностью бизнеса заключается в том, что сами бизнес-подразделения будут вынуждены выявлять внутренние процессы и выделять среди них критичные. Это еще одна из причин, почему подобный проект должен инициироваться высшим руководством компании, а не ИТ-подразделением.
Любая компания подвержена воздействию внешних факторов. Негативное влияние этих факторов можно разделить на различные группы, например: финансовые потери; увеличение накладных расходов; потеря имиджа на рынке; потеря заказчиков и т. д.
Рассматривая ситуацию, когда внешние факторы воздействуют только на критичные бизнес-процессы, владельцы этих процессов оценивают возможные негативные влияния по вышеуказанным категориям. Исходя из допустимых потерь владельцы процессов определяют минимально допустимый уровень функционирования бизнес-процессов в кризисной ситуации, в частности совместно с руководством ИТ-подразделения они фиксируют минимальный уровень тех ИТ-услуг, которые эти процессы поддерживают. Также определяется время восстановления ИТ-сервисов до минимального уровня и полное время восстановления до штатного уровня. Эти данные будут использоваться руководителями ИТ-отделов в дальнейшем при построении стратегии непрерывности ИТ-услуг.
Оценка рисков
Существует много различных способов идентификации и оценки рисков в предоставлении ИТ-услуг. Одним из самых устоявшихся и рекомендуемых в ИТ-подразделениях является метод CRAMM (the UK Government Risk Analysis and Management Method). Этот метод разработан Службой безопасности Великобритании (UK Security Service) по заданию британского правительства и взят на вооружение в качестве государственного стандарта.
Он используется начиная с 1985 года правительственными и коммерческими организациями Великобритании. За это время CRAMM приобрел популярность во всем мире. Фирма Insight Consulting Limited занимается разработкой и сопровождением одноименного программного продукта, реализующего метод CRAMM.
В настоящее время CRAMM — это довольно мощный инструмент, позволяющий, помимо анализа рисков, решать также и ряд других аудиторских задач. В его основе лежит комплексный подход к оценке рисков, сочетающий количественные и качественные аналитические компоненты. Метод является универсальным и подходит не только для больших, но и для мелких организаций как правительственного, так и коммерческого сектора.
Суть метода состоит в следующем. После идентификации бизнес-критичных ИТ-услуг внутри ИТ-подразделения составляется список всех ИТ-активов, входящих в состав этих сервисов. Для каждого ИТ-актива определяются угрозы, то есть список негативных внешних воздействий, могущих привести к недоступности этого актива. К угрозам относится:
- умышленная порча оборудования;
- уход с рынка ключевого провайдера;
- сетевые атаки;
- пожар в помещении;
- террористическая атака;
- саботаж;
- отключение электричества;
- нарушение процедур эксплуатации (человеческая ошибка) и т. д.
Для каждой угрозы определяется величина, то есть вероятность ее наступления. Она может быть оценена по статистическим данным либо субъективно.
Далее для каждого ИТ-актива определяется его уязвимость по отношению к угрозам. Это означает степень влияния внешнего фактора на общий ИТ-сервис в случае воздействия этого фактора на данный ИТ-актив. Обычно высокая уязвимость ИТ-актива связана с тем, что он является единой точкой сбоя в процессе предоставления ИТ-услуги. Например, если один источник питания обслуживает кластер серверов, предоставляющих бизнес-критичную информацию, то такой источник питания будет уязвимым компонентом ИТ-услуги по отношению к отключению электричества.
| Рис. 2. Метод анализа рисков CRAMM |
Наступление угрозы в одном из ИТ-компонентов означает определенный вид нарушения ИТ-сервиса в целом, например недоступность технического персонала, потеря данных, полное разрушение ИТ-систем (в случае глобальных угроз), недоступность сети и т. д. Возможность подобных нарушений идентифицируется в качестве рисков, связанных с ИТ-сервисом в целом.
Наконец, степень риска ИТ-сервиса определяется как произведение вероятности угрозы на уязвимость актива по отношению к этой угрозе.
Количество оцененных таким образом рисков для каждого ИТ-сервиса может быть очень велико, поэтому часто в крупных компаниях пользуются правилом Tор 10, когда рассматриваются лишь первые десять самых распространенных рисков.
Разработка стратегии непрерывности бизнеса
| Определение степени риска |
Идентификация и оценка степени — это первый шаг к управлению рисками. Управлять рисками означает принимать меры по уменьшению вероятности и степени воздействия риска и быть готовым к кризисным ситуациям в случае их наступления. На этой стадии ИТ-подразделение разрабатывает методы уменьшения рисков и методы работ в чрезвычайных ситуациях.
Различные системы резервного копирования, бесперебойные источники питания, системы информационной защиты — все это примеры принятия мер по увеличению отказоустойчивости ИТ-сервисов. Однако подготовка и применение мер по восстановлению работы ИТ в кризисной ситуации не столь распространены сейчас в России. Существует несколько возможностей восстановления ИТ-сервисов в случае их полного или частичного разрушения.
Ничего не делать. Пожалуй, не самый популярный в последнее время метод. Однако он существует.
Обходные пути вручную. Это метод восстановления критичных бизнес-процессов за счет перевода их на «бумажный» режим. Бухгалтерия, служба охраны и прочие подразделения компании в этом случае должны иметь возможность быстрого переключения на бумажную работу, а это означает наличие сейфов с томами различных разлинованных журналов.
Взаимные соглашения. Этот метод заключается в поиске организации с аналогичной структурой автоматизации основных бизнес-процессов и заключения двустороннего соглашения об использовании ее инфраструктуры в критических ситуациях. Более того, две аналогичные в смысле ИТ-сервисов организации могут объединить некоторые свои системы, делая их распределенными, то есть более устойчивыми к угрозам.
Постепенное восстановление. Применимо для организаций, чей бизнес не пострадает при простое ключевых ИТ-сервисов в течение 72 часов. За это время ИТ-подразделению может быть предоставлено третьей стороной на коммерческой основе либо самой организацией новое, полностью оборудованное телекоммуникационной сетью помещение. Также при выборе помещения необходимо учитывать количество сотрудников, которые будут находиться при восстановлении и потреблении ключевых ИТ-сервисов. Обычно заранее оговаривается количество, состав рабочих мест и серверов в помещении, а также то, чьими силами будут переноситься данные из зоны чрезвычайной ситуации в новое помещение.
Промежуточное восстановление. Этот вид восстановления применим для организаций, в которых простой критичных ИТ-сервисов допустим в пределе от 24 до 72 часов. Обычно этот вид восстановления доступен на коммерческой основе.
Специальные поставщики восстановления ИТ-услуг предлагают единое, хорошо охраняемое помещение с уже работающей ИТ-инфраструктурой, предоставляющей определенные, общие для различных организаций ключевые ИТ-услуги. В случае наступления кризиса организация использует внешние работающие ИТ-сервисы на территории поставщика.
Минусом здесь может быть удаленность от организации-заказчика. Зачастую поставщик предоставляет мобильные ИТ-услуги: полностью снабженный необходимым телекоммуникационным оборудованием трейлер доставляется до территории заказчика. Этот трейлер соединен беспроводной связью с центром обработки данных поставщика. В стоимость использования внешних ИТ-услуг входит их техническое обслуживание и их бесперебойное предоставление. Стоимость за пользование внешними услугами обычно взимается на ежедневной основе.
Максимальное время пользования услугами восстанавливающих компаний оговаривается в контракте и обычно составляет 6-12 недель.
Немедленное восстановление. Этот метод восстановления применим для компаний, чей бизнес почти полностью зависит от ИТ, таких как брокерские компании, банки, операторы сотовой связи и т. д. Суть заключается в том, что компания снимает у сторонней коммерческой организации помещение, в котором уже сформирована инфраструктура, полностью совпадающая с инфраструктурой компании.
Все основные приложения поддерживаются в рабочем состоянии командой поставщика, а все данные в этих зеркальных инфраструктурах полностью синхронизированы. В случае катастроф организация переключается на зеркальную инфраструктуру, при этом все ИТ-сервисы доступны из другого источника. Подобный вид переключения и потребления ИТ-сервисов из зеркальной инфраструктуры означает наличие устойчивого канала связи. Иногда организации предпочитают снять у поставщика дополнительные площадь и рабочие места для своих ключевых сотрудников (например, ключевых брокеров на случай «падения» основного канала связи). Конечно, подобный вид услуги восстановления оказывается весьма дорогим удовольствием, но многие организации готовы идти на это, так как возможные убытки от простоя бизнеса существенно превышают абонентскую плату за ренту зеркальной инфраструктуры.
Планирование внедрения
После того как выработана стратегия уменьшения рисков и методов восстановления, начинается стадия внедрения механизмов управления непрерывностью бизнеса. На этой стадии различные подразделения разрабатывают детальные планы по распределению ролей и ответственности в организации в случае катастроф, взаимодействию с общественностью, управлению безопасностью, оценке ущерба, спасению имущества и т. д. Подразделение ИТ в свою очередь детально разрабатывает планы по восстановлению телекоммуникационного и компьютерного оборудования в кризисной ситуации.
Внедрение
Дальнейшее внедрение разработанных планов идет по трем направлениям.
Принятие мер по уменьшению рисков. Собственно, это знакомое всем внедрение систем повышения безопасности и отказоустойчивости — от различных смарт-карт до создания распределенных систем.
Поиск запасных площадок. На этой стадии проводится поиск коммерческих организаций, предоставляющих услуги по восстановлению ИТ в кризисных ситуациях, выбор нужных площадок, подготовку и настройку ИТ-систем, закупку нового оборудования.
Разработка плана и процедур восстановления. На этой стадии руководство ИТ разрабатывает детальный план по управлению непрерывности ИТ-сервисов. Стоит напомнить, что управление непрерывностью ИТ-сервисов — это лишь малая часть большого процесса управления непрерывностью бизнеса. На этой стадии определяются процедуры по восстановлению ключевых ИТ-сервисов в определенном порядке за минимально допустимое время до минимально допустимого уровня. Эти процедуры могут включать, например, разработку инструкций, согласно которым любой ИТ-специалист, незнакомый со спецификой ИТ-сервиса, мог бы шаг за шагом восстановить его в указанный временной период.
Начальное тестирование. Эта стадия предполагает первое эмулирование кризисной ситуации, в ходе которой определяются реальное время восстановления определенных ИТ-систем. К процедуре тестирования привлекается весь ИТ-персонал — от системных администраторов до службы Service Desk. Первое тестирование может происходить и без сотрудников бизнес-подразделений, однако для полноценного тестирования рекомендуется их привлечение.
Операционное управление
Тактика «внедрить и забыть» неизбежно приведет к тому, что организация будет не готова к кризисной ситуации. Руководство должно заботиться о поддержании планов в актуальном состоянии, а также к тому, чтобы персонал был готов к встрече с кризисом. Это осуществляется через операционное управление и включает в себя следующие мероприятия.
Обучение и оповещение. Обучение и оповещение должно проводиться с сотрудниками абсолютно всех подразделений организации. Персонал компании должен знать о существовании процессов управления непрерывностью бизнеса (в частности, ИТ-персонал — об управлении непрерывностью ИТ-сервисов) и воспринимать это как часть повседневной жизни.
Пересмотр и аудит. Возможное появление новых внешних угроз или автоматизация новых бизнес-процессов означает неизбежное изменение требований к имеющимся ключевым ИТ-сервисам. Регулярное обновление планов и процедур по обеспечению непрерывности ключевых ИТ-услуг позволит ИТ-подразделению гибко приспосабливаться к изменяющемуся бизнесу организации.
Тестирование. Как и в случае первого эмулирования кризисной ситуации, организация должна быть постоянно готова к принятию быстрых мер. «Учебные тревоги» должны стать частью штатной жизнедеятельности крупных организаций.
Управление изменениями. Процесс управления изменениями, если таковой внедрен в организации, должен быть привлечен к управлению непрерывностью ИТ-услуг для четкого понимания того, как изменение внутри ИТ может повлиять на доступность ключевых ИТ-услуг в кризисной ситуации.
Обучение ИТ. ИТ-персонал может быть привлечен к обучению функционирования ключевых бизнес-процессов с целью понять собственный вклад в управление непрерывностью бизнеса.
Управление непрерывностью бизнеса дает организации гарантии устойчивости к внешним рискам.
В западных компаниях, где управление рисками уже давно стало нормой функционирования любого крупного бизнеса, внедрение подобного процесса уже вошло в повседневную практику.
Однако необходимость внедрения столь недешевого и полномасштабного процесса в российских компаниях наверняка еще долгое время будет темой для обсуждения на конференциях. И дело здесь скорее не в отсутствии денежных средств, а в готовности сознания бизнес-руководителей принять данный процесс как жизненную необходимость. Однако повышенный интерес к этой теме со стороны ИТ-руководителей оставляет надежду на рост интереса к данному процессу со стороны и бизнес-руководителей. А это в свою очередь означает перспективу развития новой ниши российского ИТ-рынка — рынка поставщиков услуг по восстановлению ИТ в кризисных ситуациях.
Источник: www.osp.ru
Облако про запас

Создавать собственный резервный ЦОД или приобретать ресурсы для резервирования ИТ как услуги? В компании «Аэрофлот» предпочли создать собственный ЦОД с виртуализованной инфраструктурой.
15.12.2013 Михаил Зырянов
- Ключевые слова :
- ИТ-инфраструктура
Почему «Аэрофлот» предпочел создать собственный резервный ЦОД? «С одной стороны, аренда ресурсов ЦОД в Московском регионе обошлась бы слишком дорого — расценки, скажем, в Далласе (штат Техас) на порядок ниже, правда, задержка сигнала, если арендовать вычислительные мощности в Штатах, слишком велика, — поясняет Кирилл Богданов, заместитель генерального директора по ИТ компании «Аэрофлот». — С другой — коммерческие ЦОД, с которыми велись переговоры, не пожелали подписывать с нами SLA — вероятно, опасались, что не смогут соответствовать нашим требованиям в части непрерывности и доступности ИТ-сервисов, а также защиты персональных данных наших клиентов».
Требования в отношении непрерывности и доступности ИТ-сервисов и в самом деле высокие. По мере увеличения интенсивности авиаперевозок «Аэрофлот» стал зависеть от ИТ все сильнее и сильнее. Если в 2009 году «Аэрофлот» выполнял в среднем 150–160 рейсов в сутки на вылет и столько же на прилет, то сейчас — примерно по 250 рейсов в сутки на прилет и на вылет. Интервалы между взлетами и посадками отдельных самолетов сократились до нескольких минут. В этих условиях практически любой сбой способен вызвать «эффект домино» — существенно нарушить график движения самолетов и, как следствие, породить весьма серьезную волну нареканий со стороны недовольных пассажиров, широкий резонанс в обществе и в конечном итоге привести к заметным финансовым и репутационным потерям.
/2013-12/12_13/13153913/Direktor_informacionnoj_sluzhby_(CIO.RU)_QB9A6799_(1622).png) |
| «Мы убедились в том, что модульность — это очень удобно, а потому будем развивать оба наших ЦОД на модульной основе», Кирилл Богданов, заместитель генерального директора по ИТ компании «Аэрофлот» |
Непрерывность бизнеса — это непрерывность ИТ
Действия компании «Аэрофлот» в чрезвычайных ситуациях курирует производственный блок. «Возглавляет эту работу департамент планирования и координации операционной деятельности — самое важное подразделение с точки зрения непрерывности производственного цикла. Оно отвечает за своевременное отправление, прибытие всех рейсов и выстраивание всего комплекса наземного обслуживания пассажиров, их багажа, обработки грузов и пр.», — рассказывает Богданов. Если какой-то из ИТ-сервисов перестает быть доступным, то, как правило, именно это подразделение первым бьет тревогу. Подразделение это работает круглосуточно, поэтому и его ИТ-поддержка обеспечивается круглосуточно. Сбой в графике на один час рассматривается как форс-мажорная ситуация, и если она возникает, авиакомпания принимает все возможные меры по ее разрешению.
Второй по важности департамент с точки зрения непрерывности его ИТ-поддержки — департамент производства полетов, он обеспечивает подготовку экипажей летчиков и бортпроводников перед полетами, в том числе разрабатывает задания на полет, готовит навигационные карты маршрутов, инструкции по взлету и посадке, проводит инструктаж экипажей и пр. «Сейчас практически вся документация на полет самолетов A-320 передается экипажам в электронном виде, — отмечает Богданов. — Для сравнения: в бумажном виде она весит около 30 кг на относительно небольшой рейс и около 50 кг — на дальний рейс. Электронная документация записывается на ноутбуки, на борту их должно находиться два — таким образом документация дублируется». В 2014 году компания планирует существенно расширить перечень самолетов, для которых документация на полет будет готовиться в электронном виде.
Третий по важности — департамент наземного обеспечения перевозок, его ключевая функция — регистрация пассажиров. Непрерывность ИТ-услуг для бэк-офисных служб, а также подразделений продаж обеспечивается с меньшим приоритетом.
Таким образом, наиболее критичная к сбоям система обеспечивает управление отправкой и прибытием рейсов. Вторые по критичности — система регистрации пассажиров, багажа и грузов вместе с приложениями, с которыми она интенсивно работает, а также системы, обеспечивающие подготовку экипажей к полетам (включая летные задания, метеопрогнозы). Бэк-офисные системы — третьи по уровню критичности.
«Практически весь бизнес нашей авиакомпании построен на базе ИТ, и за все вопросы, касающиеся непрерывности ИТ-сервисов, отвечаю я. В моем распоряжении есть специальная бригада из полусотни сотрудников, которые в случае необходимости немедленно приступают к активации резервных сервисов и каналов связи — соответствующую команду даю им лично я. Обычно эти бригады обеспечивают полную готовность резервных систем к работе за 3–4 минуты. Если сбой оказался настолько серьезным, что его не удалось устранить в течение часа, то эти специалисты оповещают меня».
Разработкой регламентов восстановления ИТ-сервисов после сбоя занималось ИТ-подразделение, согласовывая практически каждый шаг этого плана с производственными структурами. В частности, согласовывались допустимые сроки переключения сервисов на резервные мощности.
В 2012 году в одном из помещений основного ЦОД
«Аэрофлота» (он построен в 2010 году в местечке Мелькисарово под Москвой) был создан ситуационный центр, в нем собраны терминалы всех производственных систем, а также коммуникационное оборудование и средства связи с экипажами самолетов, выполняющих рейсы, и с подразделениями, обеспечивающими наземное обслуживание. При возникновении масштабных форс-мажорных обстоятельств ситуационный центр дает возможность перейти на «ручное управление» авиакомпанией. Для этого руководство авиакомпании дает команду на активацию одного из разработанных заранее планов действий в условиях чрезвычайных ситуаций, в этих планах детально определены роли и границы ответственности должностных лиц, а также последовательность действий, которые необходимо предпринять. Раз в год в компании проводятся масштабные учения — отрабатывается слаженность всех, кто задействован в планах на случай ЧП.
Контейнеры для облаков
По мере усиления требований к непрерывности ИТ-сервисов росли и требования к резервированию мощностей для их предоставления. В 2012 году руководство компании приняло решение о строительстве собственного резервного ЦОД в 10 км от основного.
Для резервного ЦОД были выбраны модульные технологии. На специально подготовленной железобетонной площадке установили модули, выполненные на базе решения «ИТ Экипаж» компании «Техносерв».
Десять из них содержали компьютерное оборудование компании HP и инженерное оборудование, в одном были рабочие места для персонала, в двух модулях — системы бесперебойного электропитания, способные снабжать резервный ЦОД электричеством в течение часа, еще в одном — дизель-генератор, который должен запуститься максимум за 30 мин. после возникновения сбоя. Модули расположены в два яруса: на нижнем — инженерное оборудование, на верхнем — серверное. Емкость ЦОД сейчас составляет 56 серверных стоек. Как утверждают разработчики модулей, надежность работы серверного оборудрования обеспечивается на уровне не ниже Tier III по классификации Uptime Institute.
На строительство резервного ЦОД ушло полгода. Проект был выполнен по лизинговой схеме, организованной подразделением финансовых услуг НР в России.
«Модульный подход помог обеспечить нам масштабируемость, теперь мы сможем, если потребуется, легко нарастить серверные мощности и инженерную инфраструктуру — это и в самом деле несложно, поскольку мы не ограничены рамками отдельного помещения, — поясняет Богданов. — Мы убедились, что модульность — это очень удобно, а потому будем продолжать развивать оба наших ЦОД на модульной основе».
Ресурсы резервного ЦОД отданы в распоряжение двух облаков. В одном размещены резервные системы, они активируются, если выходит из строя основной ЦОД. Второе облако охватывает часть физических серверов в основном ЦОД и часть — в резервном, оно предназначено для тестирования новых функций и обновлений к имеющимся, а также для обучения сотрудников.
На базе основного ЦОД работает облако, в котором размещаются системы, находящиеся в промышленной эксплуатации. В настоящее время в компании используются три основные платформы.
Первая — система бронирования билетов Sabre, на ее основе также реализована система управления доходами от услуг авиаперевозки, тарифами, с ее помощью рассчитывается доходность рейсов в зависимости от выбранного маршрута полетов и пр. Бронирование авиабилетов обеспечивают серверы, расположенные в Далласе, функции, связанные с расчетами для нужд самого «Аэрофлота», — собственные серверы авиакомпании. Вторая прикладная платформа — SAP, на ней работает весь бэк-офис компании. Третья платформа — Sirax AirFinance, разработка компании Lufthansa Systems (входит в состав Lufthansa Group), на ее базе реализована ИТ-поддержка наземного обслуживания рейсов, в частности — управления потоками транзитных пассажиров и учета фактических доходов.
Развитие на основе ИТ
Дальнейшая судьба компании будет неразрывно связана с ИТ не только потому, что зависимость от ИТ с каждым годом только растет, но и потому, уверен Богданов, что успехи блока ИТ благоприятно сказываются на ключевых показателях компании: «С нашей помощью «Аэрофлот» внедрил технологии, которые позволили обслуживать больше пассажиров меньшим числом сотрудников. Так, если в 2009 году на одного сотрудника авиакомпании приходилось 250 перевезенных за год пассажиров, то, как ожидается, в 2013 году этот показатель вырастет почти в пять раз в основном благодаря увеличению парка самолетов и повышению загрузки кресел, при этом штат авиакомпании растет незначительно. ИТ помогают компании оптимизировать затраты на перевозки, не жертвуя качеством обслуживания».
Ближайшие планы авиакомпании связаны в первую очередь с внедрением новых электронных услуг для пассажиров. Дальнейшее развитие получит и ИТ-поддержка программы лояльности «Аэрофлот-Бонус». Третье направление — поддержка работы бортпроводников, реализованная средствами мобильных решений. Планируется также в скором времени заменить прежнюю систему управления ремонтами самолетов на более современную — AMOS, разработку швейцарской компании Swiss AviationSoftware, это решение является стандартом де-факто в своем сегменте.
Источник: www.osp.ru
Непрерывность как процесс. Ошибки, которые вполне можно не допустить при организации управления непрерывностью.
Среди ITSM-консультантов можно встретить такую точку зрения, что некоторые процессы, описанные в ITIL, на самом деле процессами не являются. В пример обычно приводятся или очень простые процессы, такие, как управление доступом, или, наоборот, достаточно сложные, к которым традиционно относят ряд процессов стадии проектирования (Service Design), например, управление мощностями или непрерывностью ИТ-услуг.
В качестве одного из доводов в защиту такой точки зрения обычно предлагается попробовать построить блок-схему такого процесса. Действительно, при попытке формализации управления доступом часто получается положение об отделе (по сути, описание функционала), а вот обеспечение непрерывности ИТ-услуг вызывает сложности. С управлением доступом все просто – в данном случае процессом действительно названо подробное описание деятельности узкоспециализированного подразделения (функции с точки зрения ITIL), отвечающего за конкретный участок оперативно-технической работы. Но почему документы, регламентирующие управление непрерывностью, зачастую так сложны, непонятны и, будем откровенны, просто не работают, попробуем разобраться.
Исходя из результатов анализа значительного количества документов, призванных формализовать обеспечение непрерывности ИТ-услуг в разных организациях: стратегий, регламентов, планов непрерывности, сценариев восстановления и т.п., можно сформулировать некоторые распространенные заблуждения, способные серьезно повлиять на управляемость данного процесса.
Ошибка №1. Некорректный охват процесса
Первая ошибка, которую можно допустить, инициируя мероприятия по обеспечению непрерывности – это попытка объединить под одной крышей процессную активность и деятельность, которая является внешней по отношению к данному процессу. Происходит это потому, что начинающие менеджеры (а в роли таковых практически всегда вынужденно выступают ИТ-специалисты) смешивают совершенно разные сущности, а именно – субъекты и объекты управления. Схематично взаимоотношения между субъектами и объектами управления можно представить так, как показано на Рисунке 1. То есть, необходимо учитывать, что структура управляемого объекта может быть многоуровневой.
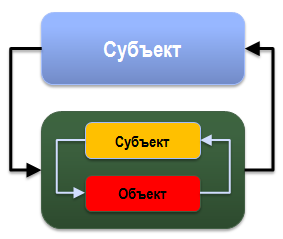
Рисунок 1 Субъекты и объекты управления.
Часто приходится наблюдать, как в охват процесса управления непрерывностью ИТ-услуг пытаются включить вообще всю деятельность, имеющую хоть какое-то отношение к этой теме, например, разработку стратегии непрерывности или регламента данного процесса. Такая точка зрения в целом понятна – ITIL содержит довольно подробное описание организации процесса, начинающееся именно с выработки Стратегии, однако управление непрерывностью – это не тот процесс, который следует перегружать сущностями, там и так достаточно объектов для управления.
Стратегия должна определять цели и высокоуровневые показатели всей деятельности по обеспечению непрерывности, регламент – описывать способы их достижения, включая методы контроля и показатели эффективности (KPI) самого процесса. Создание и актуализацию этих документов лучше вынести за рамки процесса, они органично смотрятся в качестве входящей управленческой информации.
Ошибка №2. Смешивание функций управления
Второй характерной ошибкой можно назвать отсутствие понимания того, что процедуры управления процессом лучше разделять на группы (их иногда называют контурами управления), в соответствии с основными функциями менеджмента, среди которых обычно выделяют планирование, организацию, координацию, контроль и мотивацию (Рисунок 2). Практика показывает, что высокоуровневые процессы, в отличие от процессов операционного уровня (таких, как управление инцидентами, проблемами или запросами на обслуживание), крайне чувствительны к подобным недоработкам.
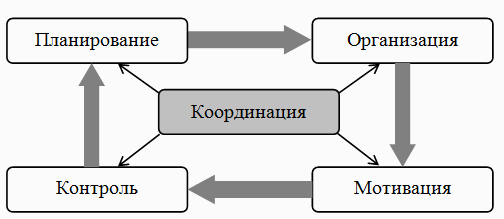
Рисунок 2 Функции управления процессом.
Планирование и мотивацию рассматривать сейчас не будем – с ними все более-менее понятно, а вот на оставшихся трех функциях стоит остановиться подробнее. Вооружившись Стратегией непрерывности и Регламентом (создание которых, как уже сказано выше, целесообразно вынести за рамки процесса), можно приступать к организации деятельности. Основные документы, которые рекомендуется разработать на данном этапе – это план обеспечения непрерывности и сценарии восстановления ИТ-услуг.
Характерным следствием смешивания функций управления является попытка включить в план обеспечения непрерывности все, кроме того, что там действительно должно быть. Ведь, если отвлечься от ITIL и прочих «good practices» в этой области, то план – это документ, который в первую очередь должен стать руководством к действию, воинским уставом для персонала при наступлении по-настоящему чрезвычайной ситуации. Поэтому довольно странно видеть там такие разделы, как «Анализ рисков» или «Порядок проведения и оценки тренировок», что как раз и является примером смешивания контуров организации, координации и контроля процесса.
В плане обеспечения непрерывности, в первую очередь, должны содержаться актуальные ответы на простые, но жизненно важные вопросы: «что случилось?», «кому звонить?», «куда бежать?», «что спасать?» и т.п. Ответы на эти вопросы должны быть понятны не только менеджеру по управлению непрерывностью или ИТ-руководству, но и тем людям, которые будут находиться в диспетчерской или пункте управления именно в тот момент, когда любое начальство окажется вне зоны доступа (а в чрезвычайных ситуациях весьма часто так и происходит). Именно им придется принимать первые и, возможно, самые важные решения. Таким образом, учитывая основное назначение Плана непрерывности и необходимость поддержания его актуальности, перегрузка этого документа информацией приводит к очевидному снижению управляемости процессом, причем, на самом критичном его участке.
Ошибка №3. Отсутствие вовлеченности бизнес-подразделений
Со сценариями восстановления тоже все не так просто, как могло бы показаться. Представим себе ситуацию, что процесс запущен, регламент исполняется, планы актуализируются, сценарии разрабатываются, тренировки ИТ-персонала проводятся, и даже показатели процесса свидетельствуют о высокой готовности организации противостоять различным неприятностям. Но рано или поздно обязательно случается реальная нештатная ситуация (не катастрофа даже), и все почему-то идет не по плану. К примеру, дизельные генераторы запущены, автоматизированные системы переведены на резервные схемы работы, сохраненные данные загружены, а вот прерванные бизнес-процессы отчего-то не возобновляются.
Это и есть следствие третьей ошибки – попытки построить управление непрерывностью без активного вовлечения в него бизнес-подразделений. Разумеется, по-хорошему, именно с этого и следовало бы начать данный обзор – ведь очевидно же, что целью обеспечения непрерывности ИТ-услуг является поддержка непрерывности бизнеса (business continuity), то есть восстановление функционирования бизнес-процессов, а не автоматизированных систем или даже ИТ-услуг.
Это и в ITIL неоднократно сказано, и во всех стандартах по непрерывности написано, и тренеры на курсах не устают повторять. Однако в жизни, к сожалению, слишком часто решение сложнейших задач по обеспечению жизнестойкости бизнеса возлагается на технических специалистов, не имеющих к этому самому бизнесу никакого отношения. В результате, естественно, начинаются попытки решить организационные проблемы без понимания их сути, зато с использованием технических средств, стоящих весьма недешево. И хорошо еще, если удается иногда проводить комплексные тренировки с участием сотрудников бизнес-подразделений, способные наглядно показать низкую эффективность подобного подхода, но, зачастую, обходятся и без них. С легко предсказуемым результатом, понятно.
Ошибка №4. Подход к управлению непрерывностью как к процессу операционного уровня
Ну и четвертая ошибка – излишне упрощенное понимание процесса, особенно свойственное начинающим процессным менеджерам. Управление непрерывностью ИТ-услуг отличается от процессов операционного уровня – это стратегический, многогранный и многоуровневый процесс, в котором ключевую роль играет постоянное совершенствование. Здесь недостаточно придумать систему метрик и регулярно проводить оценку деятельности с целью условно справедливого распределения квартальной премии. Результаты такой оценки должны служить основой для регулярного проведения комплексных мероприятий, направленных на повышение доступности ИТ-услуг в части обеспечения их восстановления после серьезных сбоев. Поэтому, например, к выбору показателей эффективности процесса необходимо подходить не формально, а постоянно сравнивать итоги проведенных тренировок с результатами деятельности по устранению реальных нештатных ситуаций на тех же объектах ИТ-инфраструктуры, на которых проводится отработка сценариев восстановления.
Разумеется, в этом краткое обзоре рассмотрены далеко не все возможные ошибки, допускаемые при организации управления непрерывностью ИТ-услуг, но приведенных примеров вполне достаточно для того, чтобы однозначно определить эту деятельность как сложный и многоуровневый процесс, внедрение которого является серьезным вызовом для любой организации. Однако, современные тенденции в развитии бизнеса и постоянно возрастающая роль обеспечения доступности и непрерывности ИТ-услуг фактически не оставляют нам выбора – внедрять процесс необходимо, но делать это нужно в тесном взаимодействии с бизнесом, избегая при этом элементарных управленческих ошибок.
Цифровой путь с компанией IT Expert начинается!
Группа компаний IT Expert объявляет о запуске отечественной системы сертификации специалистов с линейкой соответствующих учебных курсов для России и стран СНГ под названием «Цифровой путь».
10 фактов об ITIL® и 1 мифический бонус (или бонусный миф?)
Уже многие годы в кругах ИТ-профессионалов звучит термин «ITIL» в контексте построения работы ИТ-подразделения, предоставления ИТ-услуг бизнесу и подходов к организации технической поддержки.
COBIT®. Эволюция методов оценки системы управления
Информационные технологии уверенно и незаметно покоряют мир. Информация нужна всем, новые возможности работы с информацией в любой форме дают потрясающие преимущества любому бизнесу.
Учиться лучше в настоящем учебном центре!
Наверное, многие и не подозревают, но образовательная деятельность или, проще говоря .
О пользе тестирования планов непрерывности