В настоящее время в разработке ПО достаточно часто применяется многоуровневая архитектура или многослойная архитектура (n-tier architecture), в рамках которой компоненты проекта разделяются на уровни (или слои). Классическое приложение с многоуровневой архитектурой, чаще всего, состоит из 3 или 4 уровней, хотя их может быть и больше, учитывая возможность разделения некоторых уровней на подуровни. Одним из примеров многоуровневой архитектуры является предметно-ориентированное проектирование (Domain-driven Design, DDD), где основное внимание сконцентрировано на предметном уровне.
В проектах с многоуровневой архитектурой можно выделить четыре уровня (или слоя):
- Слой представления, с которым взаимодействует пользователь или клиентский сервис. Реализацией слоя представления может быть, например, графический пользовательский интерфейс или веб-страница.
- Сервисный слой, реализующий взаимодействие между слоями представления и бизнес-логики. Примерами реализаций сервисного слоя являются контроллеры, веб-сервисы и слушатели очередей сообщений.
- Слой бизнес-логики, в котором реализуется основная логика проекта. Компоненты, реализующие бизнес-логику, обрабатывают запросы, поступающие от компонентов сервисного слоя, а так же используют компоненты слоя доступа к данным для обращения к источникам данных.
- Слой доступа к данным — набор компонентов для доступа к хранимым данным. В качестве источников данных могут выступать различного рода базы данных, SOAP и REST-сервисы, файлы на файловой системе и т.д.
Направление зависимостей между слоями идёт от слоя представления к слою доступа к данным. В идеальной ситуации каждый слой зависит только от следующего слоя: слой представления зависит от сервисного слоя (например, представление зависит от контроллера), сервисный слой зависит от слоя бизнес-логики (например, контроллер зависит от бизнес-сервиса), а слой бизнес-логики — от слоя доступа к данным (например, бизнес-сервис зависит от репозитория). При этом компоненты бизнес-слоя могут зависеть от других компонентов бизнес-слоя, тогда как в других слоях аналогичные зависимости нежелательны (например, зависимость одного репозитория от другого). Так же нежелательны зависимости в обратном направлении (бизнес-слой не должен зависеть от сервисного слоя) и зависимости между слоями, не являющимися соседними (сервисный слой не должен зависеть от слоя доступа к данным, например).
Грамотное ООП: организация надёжной бизнес-логики / Дмитрий Елисеев (ElisDN)
На практике иногда приходится сталкиваться с примерами, когда бизнес-логика частично или полностью находится в контроллере, а иногда встречаются и вовсе случаи обращения компонентов слоя представления к слою доступа к данным. Несоблюдение разделения кода между слоями непременно приводит к путанице, замедляет процесс разработки и развития проекта и делает процесс поддержки проекта трудоёмким и дорогим.
Допустим, у нас есть код, реализующий бизнес-логику приложения, который находится в контроллере. Что если нам требуется разработать SOAP-сервис, реализующий ту же функциональность? Мы можем скопировать существующий код в SOAP-сервис и внести в него изменения по мере необходимости. Будет ли ли такой подход работать? Да! Вызовет ли такой подход проблемы?
СЛОЙ БИЗНЕС ЛОГИКИ ASP.NET CORE — #9
Тоже да! В процессе жизненного цикла проекта требования к нему имеют свойство меняться, что ведёт к неизбежным изменениям и в коде. Но при таком подходе нам придётся изменить код и в контроллере, и в SOAP-сервисе, а также внести изменения в их тесты (вы же тестируете свой код?). Но граздо правильнее будет вынести общий код, реализующий бизнес-логику, в компонент слоя бизнес-логики. В этом случае в контроллере и SOAP-сервисе останется код, преобразующий запрос к общему виду, понятному компоненту бизнес-логики.
Очевидным фактом является то, что бизнес-логика — самая важная составляющая вашего проекта. И именно с проработки компонентов слоя бизнес-логики должна начинаться разработка проекта.
К слову сказать, очень хорошей практикой является применение UML, в данном конкретном случае — диаграммы классов. Из собственной практики помню случай, когда я решил для почти готового проекта составить диаграмму классов, результатом чего стал рефакторинг, уменьшивший количество кода примерно на 20%. Составление диаграммы классов на ранних этапах разработки позволяет уменьшить дублирование кода, сделать структуру классов и зависимости между ними более понятными.
В так полюбившейся мне книге Роберта Марина «Чистая архитектура» автор пропагандирует идею независимости (или минимизации зависимости) архитектуры приложения от внешних факторов: фреймворков, баз данных и прочих сторонних зависимостей. Это говорит не об отказе от использования этих зависимостей (вы же не будете разрабатывать собственный механизм трансляции HTTP-вызовов или хранения данных?), а о минимизации их влияния на архитектуру вашего проекта.
Разработка бизнес-логики
Давайте возьмём в качестве примера разработку блокнота, который пользователь может использовать для работы с заметками. Заметьте, я не указал, что это будет онлайн-сервис или настольное приложение. Для начала определимся с набором типов (классов и интерфейсов), которые нам понадобятся для нашего проекта. Класс-сущность, описывающий заметку — Note, компонент бизнес-логики, реализующий работу с заметками — NoteService, ещё нам потребуется компонент слоя доступа к данным — NoteRepository. Простая реализация NoteService — SimpleNoteService, использует NoteRepository для доступа к источнику данных. Диаграмма классов, описывающая текущую архитектуру, будет достаточно простая:
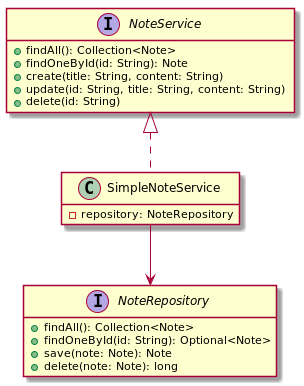
Теперь можно описать эти типы в коде, написать тесты для SimpleNoteService и реализовать этот класс.
Источник: alexkosarev.name
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
CleanArchitectureManifest / ru / layers_and_ioc.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Cannot retrieve contributors at this time
338 lines (246 sloc) 27.3 KB
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Copy raw contents
Copy raw contents
Слои и инверсия зависимостей
- Слой бизнес-логики (Domain)
- Слой работы с данными (Data)
- Repository
- Model
- View
- Presenter
- Связывание View с Presenter’ом
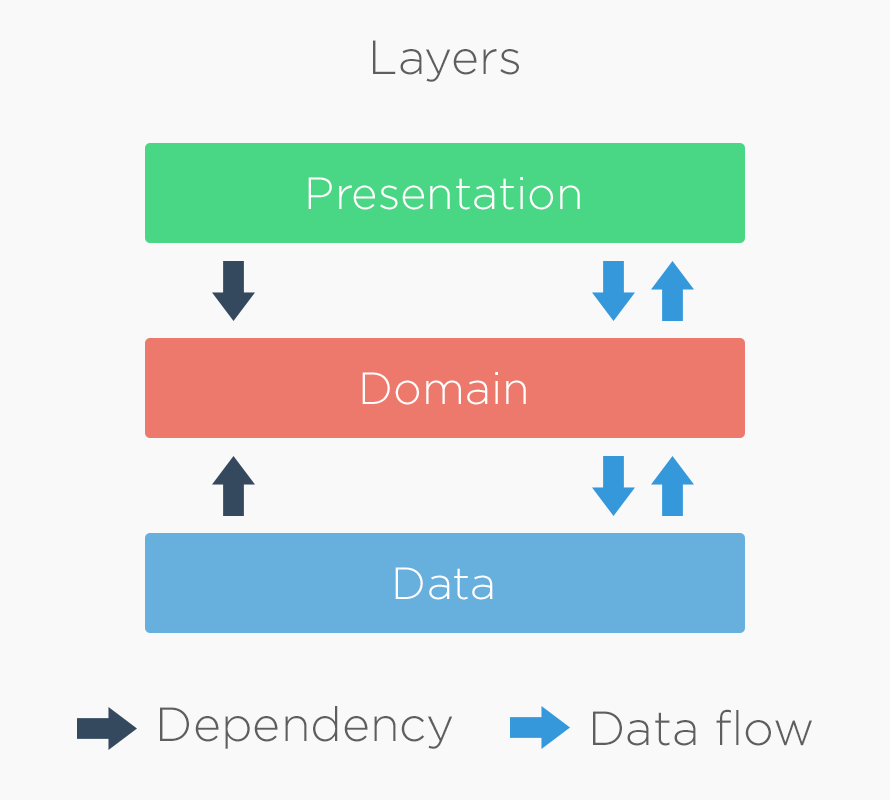
Как уже говорилось ранее, архитектуру приложения, построенную по принципу Clean Architecture можно разделить на три слоя:
- слой отображения (presentation)
- слой бизнес-логики (domain)
- слой работы с данными (data)
Выше представлена схема того, как эти слои взаимодействуют. Черными стрелками обозначены зависимости одних слоев от других, а синими — поток данных. Как видите, слои data и presentation зависят от domain, т. е. они используют его классы. Сам же слой domain ничего не знает о внешних слоях и использует только собственные классы и интерфейсы. Далее мы разберем более подробно каждый из этих слоев, и то, как они взаимодействуют между собой.
Как видно из схемы, все три слоя могут обмениваться данными. Следует отметить, что нельзя допускать прямого взаимодействия между слоями presentation и data. Поток данных должен идти от слоя presentation к domain, а от него к слою data (это может быть, например, передача строки с поисковым запросом или регистрационные данные пользователя). То же самое может происходить и в обратном направлении (например, при передаче списка с результатами поиска).
Слой бизнес-логики (Domain)
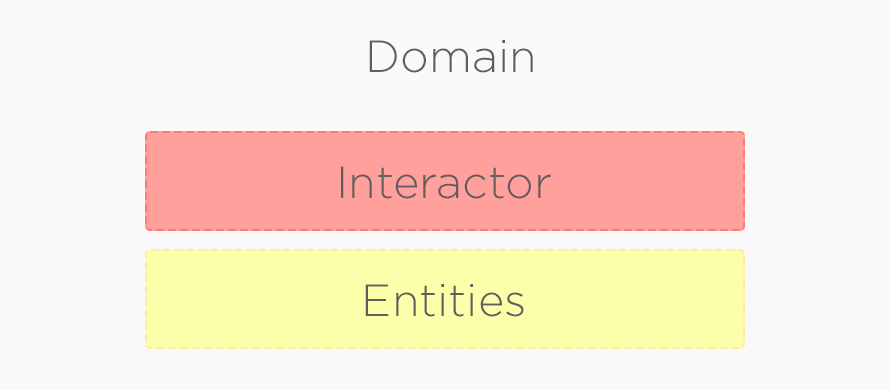
Бизнес-логика — это правила, описывающие, как работает бизнес (например, пользователь не может совершить покупку на сумму больше, чем есть на его счёте). Бизнес-логика не зависит от реализации базы данных или интерфейса пользователя. Бизнес-логика меняется только тогда, когда меняются требования бизнеса, и не зависит от используемой СУБД или интерфейса пользователя.
Роберт Мартин разделяет бизнес-логику на два вида: специфичную для конкретного приложения и общую для всех приложений (в том случае, если вы хотите сделать ваш код общим между приложениями под разные платформы).
Бизнес объект (Entity) — хранят бизнес-логику общую для всех приложений.
Interactor – объект, реализующий бизнес-логику специфичную для конкретного приложения.
Но это все в теории. На практике же используются только Interactor’ы. По крайней мере, мне не встречались приложения, использующие Entity. Кстати, многие путают Entity с DTO (Data Transfer Object). Дело в том, что Entity из Clean Architecture — это не совсем те Entity, которые мы привыкли видеть.
Данная статья проливает свет на этот вопрос, а также на многие другие.
Сценарий использования (Use Case) — набор операций для выполнения какой-либо задачи. Пример сценария использования при регистрации пользователя:
- Проверяем данные пользователя
- Отправляем данные на сервер для регистрации
- Сообщаем пользователю об успешной регистрации или ошибке
- Пользователь ввел неверные данные (выдаем ошибку)
Давайте теперь посмотрим как это выглядит на практике. Роберт Мартин предлагает создавать для каждого сценария использования отдельный класс, который имеет один метод для его запуска. Пример такого класса:
class RegisterUserInteractor( private val userRepository: UserRepository, private val registerDataValidator: RegisterDataValidator, private val schedulersProvider: SchedulersProvider ) < fun execute(userData: User): SingleRegisterResult> < return registerDataValidator.validate(userData) .flatMap < userData -> userRepository.registerUser(userData) > .subscribeOn(schedulersProvider.io()) > >
Однако практика показывает, что при таком подходе получается огромное количество классов, с малым количеством кода. Более правильным будет создание одного Interactor’а на один экран, методы которого реализуют определенный сценарий, например:
class ArticleDetailsInteractor( private val articlesRepository: ArticlesRepository, private val schedulersProvider: SchedulersProvider ) < fun getArticleDetails(articleId: Long): SingleArticle> < return articlesRepository.getArticleDetails(articleId) .subscribeOn(schedulersProvider.io()) > fun addArticleToFavorite(articleId: Long, isFavorite: Boolean): Completable < return articlesRepository.addArticleToFavorite(articleId, isFavorite) .subscribeOn(schedulersProvider.io()) > >
Как видите иногда методы Interactor’а могут и вовсе не содержать бизнес-логики, а методы Interactor’а выступают в качестве прослойки между Repository и Presenter’ом.
Если вы заметили, методы Interactor’а возвращают не просто результат, а классы RxJava 2 (в зависимости от типа операции мы используем разные классы — Single, Completable и т. д.). Это дает несколько преимуществ:
- Не нужно создавать слушатели для получения результата.
- Легко переключать потоки.
- Легко обрабатывать ошибки.
Для переключения потоков мы используем, как обычно, метод subscribeOn, однако мы получаем Scheduler не через статические методы класса Schedulers, а при помощи SchedulersProvider’а. В будущем это поможет нам при тестировании.
Слой работы с данными (Data)
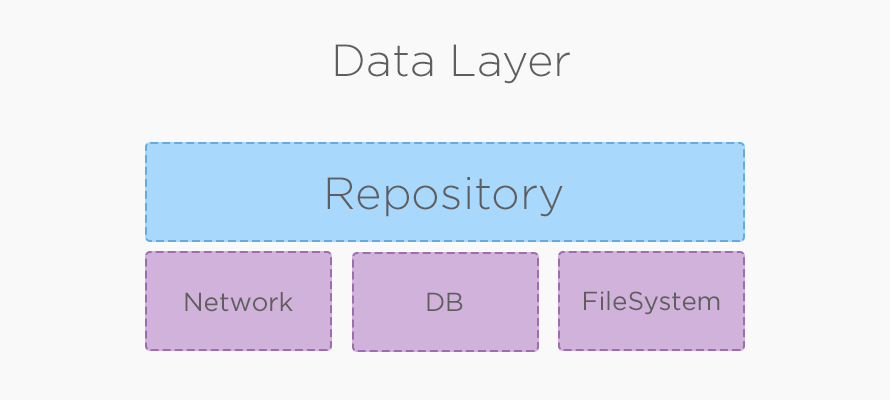
В данном слое содержится всё, что связано с хранением данных и управлением ими. Это может работа с базой данных, SharedPreferences, сетью или файловой системой, а также логика кеширования, если она имеется.
«Мостом» между слоями data и domain является интерфейс Repository (в оригинальной схеме дядюшки Боба он называется Gateway). Сам интерфейс находится в слое domain, а уже реализация располагается в слое data. При этом классы domain-слоя не знают откуда берутся данные — из БД, сети или откуда-то ещё. Именно поэтому вся логика кеширования должна содержаться в data-слое.
Repository — представляет из себя интерфейс, с которым работает Interactor. В нем описывается какие данные хочет получать Interactor от внешних слоев. В приложении может быть несколько репозиториев, в зависимости от задачи. Например, если мы делаем новостное приложение, репозиторий работающий со статьями может называться ArticleRepository, а репозиторий для работы с комментариями CommentRepository. Пример репозитория, работающего со статьями:
interface ArticleRepository < fun getArticle(articleId: String): SingleArticle> fun getLastNews(): SingleListArticle>> fun getCategoryArticles(categoryId: String): SingleListArticle>> fun getRelatedPosts(articleId: String): SingleListArticle>> >
Слой отображения (Presentation)

Слой представления содержит все компоненты, которые связаны с UI, такие как View-элементы, Activity, Fragment’ы и т. д. Помимо этого здесь содержатся Presenter’ы и View (или ViewModel’и при использовании MVVM). В данном туториале для реализации слоя presentation будет использован шаблон MVP, но вы можете выбрать любой другой (MVVM, MVI).
Для более удобной связки View и Presenter мы будем использовать библиотеку Moxy. Она помогает решить многие проблемы, связанные с жизненным циклом Activity или Fragment’а. Moxy имеет базовые классы, такие как MvpView и MvpPresenter , от которых должны наследоваться наши View и Presenter. Для избежания написания большого количества кода по связыванию View и Presenter, Moxy использует кодогенерацию.
Для правильной работы кодогенерации мы должны использовать специальные аннотации, которые предоставляет нам Moxy. Более подробную информацию о библиотеке можно найти здесь.
MVP расшифровывается как Model-View-Presenter (модель-представление-презентер). Model содержит в себе бизнес-логику и код по работе с данными. Т. к. мы используем связку Clean Architecture + MVP, то Model у нас является код находящийся в слоях Data (работа с данными) и Domain (бизнес-логика). Следовательно, в слое Presentation остаются лишь два компонента — View и Presenter.
View отвечает за то, каким образом данные будут показаны пользователю. В случае с Android в качестве View выступает Activity или Fragment. Также View сообщает о действиях пользователя Presenter’у, будь то нажатие на кнопку или ввод текста. Пример View:
interface ArticlesListView : MvpView < fun showLoadingProgress(show: Boolean) fun showArticles(articles: ListArticle>) fun showArticlesLoadingErrorMessage() >
Пока мы описали лишь интерфейс View, т. е. какие команды Presenter может отдавать View. Обратите внимание, что наш интерфейс наследуется от интерфейса MvpView, входящего в библиотеку Moxy. Это является обязательным условием для корректной работы библиотеки.
Согласно концепции MVP, View не может напрямую взаимодействовать с Model, поэтому связующим звеном между ними является Presenter. Presenter реагирует на действия пользователя, о которых ему сообщила View (такие как нажатие на кнопку, пункт списка или ввод текста), после чего принимает решения о том, что делать дальше. Например, это может быть запрос данных у модели и отображение их во View. Пример Presenter’а:
Все необходимые классы для работы Presenter’а (как и всех остальных классов) мы передаем через конструктор. Этот способ так и называется — внедрение через конструктор.
При создании объекта Presenter’а мы должны передать ему запрашиваемые конструктором зависимости. Если их будет много, то создание Presenter’а будет довольно сложным делом. Чтобы не делать этого вручную, мы доверим это дело Component’у.
Он подставит нужные зависимости, а нам нужно будет лишь получить инстанс Presenter’а вызвав метод getPresenter(). Если у вас возник вопрос «А как в таком случае передавать аргументы в Presenter?», то загляните в FAQ — там подробно описан этот вопрос.
Иногда можно встретить такое, что в конструктор передается DI-контейнер (Component), после чего все необходимые зависимости внедряются в поля:
Однако, данный способ является неправильным, т. к. усложняет тестирование класса и создает кучу ненужного кода. Если в первом случае мы сразу могли передать mock’и классов через конструктор, то теперь нам нужно создать DI-контейнер и передавать его. Также данный способ делает класс зависимым от конкретного DI-фреймворка, что тоже не есть хорошо.
Также обратите внимание на то, что перед тем как отобразить результаты, полученные от Interactor’а, мы переключаем поток на UI при помощи observeOn(schedulersProvider.ui()) . Это сделано потому, что мы не знаем заранее в каком потоке нам придут данные.
Связывание View с Presenter’ом
В контексте разработки под Android роль View на себя берет Activity (или Fragment), поэтому после создания интерфейса View, мы должны реализовать его в нашей Activity или Fragment’е:
Разбиение классов по пакетам
Ниже представлен пример разбиения пакетов по фичам новостного приложения:
com.mydomain | |—-data | |—- database | | |—- NewsDao | |—- filesystem | | |—- ImageCacheManager | |—- network | | |—- NewsApiService | |—- repositories | | |—- ArticlesRepositoryImpl | | |—- CategoriesRepositoryImpl | |—- domain | |—- global | | |—- models | | | |—- Article | | | |—- Category | | |—- repositories | | | |—- ArticlesRepository | | | |—- CategoriesRepository | |—- articledetails | | |—- ArticleDetailsInteractor | |—- articleslist | | |—- ArticlesListInteractor | |—- presentation | |—- mvp | | |—- global | | | |—- routing | | | | |—- NewsRouter | | |—- articledetails | | | |—- ArticleDetailsPresenter | | | |—- ArticleDetailsView | | |—- articleslist | | | |—- ArticlesListPresenter | | | |—- ArticlesListView | |—- ui | | |—- global | | | |—- views | | | |—- utils | | |—- articledetails | | | |—- ArticleDetailsActivity | | |—- articleslist | | | |—- ArticlesListActivity | |—- di | |—- global | | |—- modules | | | |—- ApiModule | | | |—- ApplicationModule | | |—- scopes | | |—- modifiers | | |—- ApplicationComponent | |—- articledetails | | |—- ArticleDetailsComponent | | |—- ArticleDetailsModule | |—- articleslist | | |—- ArticleListComponent
Прежде чем делить код по фичам, мы разделили его на слои.
Данный подход позволяет сразу определить к какому слою относится тот или иной класс. Если вы заметили, классы слоя data разбиты немного не так, как в слоях domain, presentation и di. Здесь вместо фич приложения мы выделили типы источников данных — сеть, база данных, файловая система. Это связано с тем, что все фичи используют практически одни и те же классы (например, NewsApiService) и их не имеет смысла разбивать по фичам.
В пакетах с именем global хранятся общие классы, которые используются в нескольких фичах. Например, в пакете data/global хранятся модели и интерфейсы репозиториев.
Слой presentation разбит на два пакета — mvp и ui. В mvp хранятся, как понятно из названия, классы Presenter’ов и View. В ui хранятся реализация слоя View из MVP, т. е. Activity, Fragment’ы и т. д.
Разбиение классов по фичам имеет ряд преимуществ:
- Очевидность. Даже не знакомый с проектом разработчик, при первом взгляде на структуру пакетов сможет примерно понять что делает приложение, не заглядывая в сам код.
- Добавление нового функционала. Если вы решили добавить новую функцию в приложение, например, просмотр профиля пользователя, то вам лишь нужно добавить пакет userprofile и работать только с ним, а не «гулять» по всей структуре пакетов, создавая нужные классы.
- Удобство редактирования. При редактировании какой либо фичи, нужно держать открытыми максимум два-три пакета и вы видите только те классы, которые относятся к конкретной фиче. При разбиении по типу класса, раскрытой приходится держать практически всё дерево пакетов и вы видите классы, которые вам сейчас не нужны, относящиеся к другим фичам.
- Удобство масштабирования. При увеличении количества функций приложения, увеличивается и количество классов. При разбиении классов по типу, добавление новых классов делает навигацию по ним очень не удобным, т.к. приходится искать нужный класс, среди десятков других, что сказывается на скорости и удосбстве разработки. Разбиение по фичам решает эту проблему, т.к. вы можете объединить связанные между собой пакеты с фичами (например, можно объединить пакеты login и registration в пакет authentication).
Также хочется сказать пару слов об именовании пакетов: в каком числе их нужно называть — множественном или единственном? Я придерживаюсь подхода, описанного здесь:
- Если пакет содержит однородные классы, то имя пакета ставится во множественном числе. Например, пакет с классами Dog, Cat и Cow будет называться animals. Другой пример — различные реализации какого-либо интерфейса (XmlResponseAdapter, JsonResponseAdapter).
- Если пакет содержит разнородные классы, реализующую определенную функцию, то имя пакета ставится в единственном числе. Пример — пакет order, содержащий классы OrderInfo, OrderInteractor, OrderValidation и т. д.
Источник: github.com