Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Антонов Сергей Игоревич, Редько Сергей Георгиевич
В статье анализируются основные проблемы автоматизации процесса управления неструктурированными данными в компании. Рассмотрены модели представления данных с точки зрения применимости для описания неструктурированных данных. Рассмотрена возможность использования технологии Semantic Web для решения задачи автоматизации обработки и описания неструктурированных данных
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Антонов Сергей Игоревич, Редько Сергей Георгиевич
Интеграция информации с использованием технологий semantic web
Архитектура электронных библиотек на основе технологий Semantic Web
Современные проблемы персонификации и экстракции данных
Инструментарий создания цифровых архивов документов на основе связанных данных
Использование мультиагентного онтологического подхода к созданию распределенных систем дистанционного обучения
Рекомендательная система как средство достижения бизнес целей
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Significant limitation of automation non structured data management process in an enterprise are analyzed in the article. Models of data presentation are put concerning applicability for non structured data description. Ability of using Semantic Web technology for automation and non structured data handling is determined
Текст научной работы на тему «Автоматизация управления неструктурированными данными в рамках системы управления контентом на предприятии»
мации и на этой основе совершенствование информационных потоков путем устранения лишних данных и введения нужных.
Таким образом, бенчмаркинговая информационная система должна формироваться и совершенствоваться с учетом пере-
численных выше требований, что является необходимым условием повышения действенности и эффективности управления, принятия эффективных управленческих решений.
С.И. Антонов, С.Г. Редько
АВТОМАТИЗАЦИЯ УПРАВЛЕНИЯ НЕСТРУКТУРИРОВАННЫМИ ДАННЫМИ В РАМКАХ СИСТЕМЫ УПРАВЛЕНИЯ КОНТЕНТОМ НА
В современную высокотехнологичную эпоху системы управления предприятием стали стандартом для компаний, стремящихся к интенсивному развитию, и необходимой составляющей для ведения эффективного бизнеса. Такие системы создаются для автоматизации процессов управления и для предоставления ключевой информации топ-менеджерам с целью многостороннего ана-
лиза состояния компании, а так же призваны помочь им в принятии решений.
Важным элементом системы управления организацией является система управления информацией [1], которая, в свою очередь, делится на две ветви в соответствии с решаемыми задачами: управление структурированными (СД) и неструктурированными данными (НД).
Рис. 1. Структура контента на предприятии
Эти системы призваны обеспечить автоматизацию обработки, хранения и предоставления свободного доступа к данным, хаотично поступающим и вращающимся в корпоративной структуре, а так же служат аналитическим инструментом для руководителей. На рис.1 показаны возможные источники информации, а так же объем обрабатываемых НД и СД на предприятии в процентном соотношении.
Обработку структурированного контента компании успешно решают с помощью систем управления документами (СУД) и бизнес-процессами, которые позволяют организовать и поддерживать информационные потоки, связанные с документационным обеспечением. Обработка неструктурированных данных может быть частично решена с использованием систем класса ECM (Enterprise Content Management) и СMS (Content Management System), но полностью охватить эту область управления информацией они не позволяют в связи со следующими ограничениями.
— Отсутствие разработанной иерархии и классификации объектов НД.
— Отсутствие механизмов автоматической обработки НД.
— Низкие аналитические возможности при работе с НД.
— Низкая скорость обработки НД.
— Отсутствие единой точки ввода и доступа к данным.
С таким перечнем проблем сталкиваются организации, ставящие целью наладить эффективный информационный поток. Разберем причины, создающие эти ограничения.
Первые три пункта, в первую очередь, связаны со слабо формализованной моделью метаданных и неадаптированной для НД моделью представления данных, которые являются ключевыми элементами в архитектуре любой ECM-системы. Низкая скорость обработки данных является следствием низкой скорости работы современных физических носителей хранения данных. Последний пункт обусловлен множеством возможных путей входа информации в компанию (e-mail, курьер, факс, интернет), что делает
актуальной задачу создания единой точки входа и обработки данных.
Можно выделить несколько основных возможностей, позволяющих повысить эффективность работы с неструктурированными данными:
— разработка оптимизированной модели представления НД;
— создание узла ввода и обработки данных;
— вовлечение в процесс обработки НД высокоскоростных носителей информации.
Наиболее существенными для задачи управления корпоративной информацией являются первое направление, за которым стоят принципиальные решения основных задач в области управления неструктурированной информацией.
Рассмотрим, какие модели представления данных используются для решения задач управления документооборотом и контентом, а так же насколько они подходят для управления неструктурированными данными.
В основе систем управления информацией, преимущественно, лежат две модели представления данных: реляционная и объектно-ориентированная. Дадим краткую характеристику каждой из моделей.
Реляционная модель представляет собой структуру данных, организованных в виде двумерных таблиц (рис.2). Каждая таблица состоит из строк (записей) и столбцов (полей). Строки таблицы содержат сведения о представленных объектах (документах) -атрибуты объекта. На пересечении столбца и строки находятся конкретное значение атрибута объекта, содержащегося в таблице данных.
Сам объект может храниться, как в базе данных, так и вне нее. Таким образом, исходя из описанной модели представления данных, СУД оперирует атрибутами документов, как коллекцией структурированных данных, каждый атрибут документа находится на «своей полке» и если есть необходимость использовать его в каком-либо процессе, то система без труда определяет необходимо значение атрибута. Преимущество
реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на компьютерах, что явилось причиной ее широкого распространения. К основным недостаткам модели относятся отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Объектно-ориентированная модель стала следующим шагом в эволюции моделей представления данных и позволила описывать не только структурированные объекты, заключив в себе элементы реляционной модели, но и частично неструктурированные и слабо структурированные данные (рис.3).
Рис. 2. Реляционная модель
свойство тип значение
район string Невский
билет в1шв 00015
номер string 02867 дата вйшв 9 01 97
билет string 00015
имя string Василвев
адрес string Мира, 3
телефон string 24Й1288 —
3 217QQ62S5 6S13D6 Базы данных А Д Хомоненко
номер string 02694
стеллаж slnng 7
издание suing I
Рис. 3. Объектно-ориентированная модель
В ЕСМ-системах данные обычно хранятся в реляционной или объектной базе данных. В первом случае объектная модель данных отображается на реляционную модель базы данных.
Основным преимуществом объектно-ориентированной модели данных, в сравнении с реляционной, является возможность адекватного отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельные записи базы данных и определять функции их обработки. Недостатками этой модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
Для определения степени пригодности рассмотренных моделей для описания СД и НД необходимо рассмотреть понятия структурированных и неструктурированных данных и разницу между ними. Структурированные данные — это данные, упорядоченные определенным образом и организованные с целью обеспечения возможности применения к ним некоторых действий для проведения анализа. Неструктурированные данные -это неупорядоченные данные, произвольные по форме, которые были собраны независимо от того, как они могут быть использованы.
Существенное отличие состоит в том, что описание СД логично и инвариантно реализуется с помощью разметки внешними атрибутами с их значениями. НД требуют, кроме того, описания самого содержания данных, а объектом описания, может быть как элемент содержания, так и оно целиком. Описание НД затрудняется нетривиальной задачей разметки содержания данных.
Отличие заключается, также в разных требованиях к метамоделям для СД и НД. Метамодель НД должна быть более гибкой, масштабируемой и должна позволять делать данные более семантически насыщенными и явно выражать (формально описывать) скрытую семантику структуры данных. Важным требованием к модели является также наличие свойств замкнутости и полноты. Замкнутость означает, что, осуществляя действия в выбранной формальной модели, мы не выйдем за её пределы и нам не встретятся не-формализуемые (неописываемые) объекты. Полнота выбранной формальной системы означает, что в её рамках можно описать все объекты из рассматриваемого множества.
Исходя из приведенных отличий, можно утверждать, что реляционная модель непригодна для работы с НД в силу своей архитектуры, основанной на совокупности плоских таблиц, не способных формализовать описание сложных структур данных. Объектно-ориентированная модель частично применима для описания НД, поскольку, наряду с простыми объектами, может описывать более сложные разветвленные структуры данных.
Таким образом, можно сделать вывод, что традиционные модели не решают задачу описания НД полностью. В качестве альтернативы рассмотрим возможность применения технологии Semantic Web, уже апробированной и использующейся в Интернет, как инструмент для описания и обработки НД [2].
Semantic Web предусматривает объединение разных видов информации в единую структуру, где каждому элементу будет соответствовать машинный код в виде специального смыслового тэга (метаданные). Все
тэги должны составлять единую иерархическую структуру RDF, на основе которой и будет работать Semantic Web. Метаданные в обязательном порядке включают общие сведения об информации, о том, как, где и кем она была создана и как структурирована. Таким образом, унифицированное представление информации в Semantic Web плюс набор механизмов «понимающих» смысловые теги, заложенных в эту информацию, обеспечат автоматическую компьютерную обработку информации с учетом ее семантики.
В основе Semantic Web лежат следующие три базовых концепции [3].
1. Расширяемый язык разметки XML (Extensible Markup Language) обеспечивает возможность создания унифицированного представления электронных документов произвольной структуры на основе словаря разметочных тегов и правил их объединения в синтаксические конструкции.
2. RDF (Resource Description Framework) — это формат описания ресурсов в терминах «объект-атрибут-значение ». Последовательно выраженные RDF — это графы цепочек описаний метаданных, которые позволяют выразить в «машинопонимаемом» формате семантические описания ресурсов.
3. Онтологии, определяющие термины и отношения между ними. Онтология представляет собой формальное описание понятий предметной области и отношений между ними, а также правила для составления новых понятий и отношений. Очень важным в данном определении является то, что онтология, кроме уже определенных понятии и отношений, содержит также правила для получения новых понятий и отношений.
Рассмотрим общее описание модели системы, построенной на основе технологии Semantic Web. Основой системы, построенной на технологии Semantic Web, является определенный семантический базис предметной области, который позволяет организовать «осмысленный» анализ информации в электронных документах. Выражается это, во-первых, в том, что любые естественноязыковые конструкции, с помощью которых
может быть представлена та или иная информация, содержат в явном или неявном виде предмет обсуждения, семантическую идентификацию которого можно осуществить благодаря наличию онтологии предметной области. Кроме того, могут быть определены и идентифицированы потенциальные взаимосвязи между объектами в тексте.
Во-вторых, информация в электронных документах часто либо структурирована, а если нет, то содержит структурированные островки информации в виде списков и таблиц. Идентификация описания информации в виде названий атрибутов, составляющих заголовки структурированной информации, также может быть осуществлена с помощью онтологии. Не имея онтологии, островки структурированной информации могут быть неправильно разделены программным обработчиком на значения и описания этих значений, т.е. будут неправильно построены цепочки «атрибут-значение», описывающие список или таблицу. Поэтому представляется целесообразным использование онтологии предметной области для организации идентификации семантических объектов и их взаимосвязей в представлении информации в электронных документах. Рассматривая такой подход в контексте задачи автоматизации управления информацией на предприятии, можно сделать вывод, что онтология с идентифицированными связями между объектами, будет являться описанием структуры определенного вида деятельности компании (логистика, бухгалтерия, финансы, планирование и т. д.)
Идентификация более сложных для описания семантических объектов информации определяется, как процесс отображения составляющих естественно-языковых конструкций на семантические описания объектов в онтологии предметной области. Здесь одну из главных ролей выполняет полнота описания предметной области, т.е. онтологии. Кроме того, в онтологии должны быть учтены синонимы, соответствующие тому или иному семантическому объекту. Проблема омонимии языков может быть решена путем идентификации семантических объектов и
проверки на допустимость возможных взаимосвязей этих идентифицированных объектов.
Рис. 4. Схема процесса анализа электронного документа
Таким образом, анализ электронного документа сводится к следующим, последовательно выполняемым шагам, изображенным на рис.4.
В статье рассмотрены задачи и определены проблемы автоматизации обработки и управления НД в рамках общей задачи управления контентом в компании. Определены основные ограничения СУИ при работе с НД и их причины. Рассмотрены модели представления данных: реляционная, объектно-ориентированная — выяснена возможность их применения к описанию НД. Рассмотрен подход к обработке и описанию данных, основанный на технологии Semantic Web, которую предложено использовать для оптимизации модели представления данных и метамодели, в рамках описанных задач автоматизации управления неструктурированными данными.
1. Информационные технологии и управление предприятием / В.В. Баронов [и др.]. — М: Компания АйТи, 2004. — 328 с.
2. Passin T. B. Explorers’s Guide to the Semantic Web / T. B. Passin.: MAN NING, 2004.
3. Daconta M.C. The semantic web. A guide to the future of XML, web services, and knowledge management / L.J. Obrst, K.T. Smit: WILEY, 2003.
Д.М. Коробкин, С.А. Фоменков
ПОИСК И ВЫДЕЛЕНИЕ СТРУКТУРИРОВАННОЙ ФИЗИЧЕСКОЙ ИНФОРМАЦИИ В ВИДЕ ФИЗИЧЕСКИХ ЭФФЕКТОВ ИЗ ТЕКСТОВ
В связи с ростом количества электронных источников все более увеличивается потребность в поиске и выделении интересующей пользователя информации. Опыт использования существующих систем, применяющих универсальные модели выделения информации, свидетельствует о необходимости ограничения обрабатываемой в системе информации до конкретной предметной
области (ПО), что позволит более релевантно искать и выделять нужную информацию. В данном исследовании предметная область ограничивается структурированной физической информацией в виде физических эффектов (ФЭ) [1], которые полезны при конструировании принципиально новых высокоэффективных технических систем, разработке новых технологий, научно-
Источник: cyberleninka.ru
Структура контента, неструктурированная информация и проблемы ее использования в бизнес-целях
Современные компании перешли на полную компьютеризацию и уже никого не удивляет тот факт, что 100% документов создаётся в электронном формате. Однако и сейчас большая их часть печатается на бумажных носителях. Причиной этому является нужда согласования, подписи. Представьте какое удобство настанет с момента внедрения электронной системы документооборота.
Такое решение безусловно должно приниматься руководителем. Но как показывает практика коренные изменения в устоявшемся бизнес режиме происходят только после возникновения нескольких сигналов. Руководство и ведущие специалисты приходят к выводу, что для решения многих проблем связанных с бумажными документами компании потребуется использование специальной системы для управления документами. ЕСМ система позволяет контролировать и управлять информацией на всех этапах её жизнедеятельности.
Система ECM ориентируется на работу с неструктурированной информацией в любом виде, включая офисные текстовые и табличные электронные документы, документы в формате PDF, а также рисунки, чертежи, графики, презентации, сканированные изображения, сообщения электронной почты, web-страницы, видео, аудиофайлы. Flash-анимация, словом всё многообразие контента, необходимого для эффективного ведения бизнеса. Основная задача системы ECM — это поддержание полного жизненного цикла информации, от ее создания или получения извне до уничтожения, когда она теряет свою ценность.
Отличие функциональности ECM-систем от систем электронного документооборота — возможность работать не только с документами, которые сегодня являются лишь малой частью корпоративного контента, но и с любыми другими видами данных: сообщениями электронной почты, графическими изображениями, фотографиями, аудио и видео файлами, web-страницами, файловыми системами, оцифрованными материалами.
Помимо инструментов для сбора, управления, накопления, хранения и доставки информации, ECM-системы обладают средствами потоковой загрузки контента, управления web-сайтами, правами доступа, безопасного корпоративного поиска. Следует отметить, что возможности разграничения прав доступа к данным позволяют ECM-системам соответствовать одному из наиболее важных требований безопасности использования контента в госструктурах, зачастую содержащего персональную или секретную информацию.
Условно к ECM относятся системы, поддерживающие хотя бы 3 из 6 функций:
1. Управление документами (выписка/возврат, контроль версий, безопасность, группировка документов и т. д.);
2. Ввод в систему и управление полученными образами бумажных документов;
3. Совместная работа над общими документами и поддержка проектных работ;
4. Управление электронным архивом, автоматизация правил и нормативов хранения, гарантирование соответствия записей законодательству и регулирующим правилам;
5. Workflow для поддержки бизнес-процессов, маршрутизации контента, назначения рабочих задач и состояний, трассировка маршрутов и контроль исполнения;
6. Автоматизации публикаций, управление динамическим контентом (например, WEB или интранет) и взаимодействием пользователей для этих задач.
Таким образом, ECM-система интегрирует все контентно- и процессно-ориентированные технологии внутри предприятия, обеспечивает единую инфраструктуру для управления документооборотом, минимизирует необходимость развертывания и поддержки множества технологий для реализации различных бизнес-задач. Такой инфраструктурный подход делает корпоративное содержимое доступным для практически всех бизнес-приложений организации. Однако, в ряде случаев ECM-система может не иметь решающих преимуществ в использовании перед «чистым» электронным архивом или workflow системой. Выбор СЭД должен определяться стоящими перед организацией задачами, ее структурой, готовностью ИТ-решений и многими другими факторами.
Базовое понятие ECM-системы – управление документами (document management), что подразумевает управление жизненным циклом документа от его создания до передачи исполненного документа на хранение или уничтожение. При этом управление жизненным циклом применимо для любого информационного объекта.
Для работы с информационными объектами создаются библиотеки, которые могут различаться назначением хранящихся в них документов, например библиотеки финансово-бухгалтерских документов, библиотеки конструкторской документации, клиентских досье и т. д. Для классификации таких документов используется более сложная система хранения, нежели привычная российским службам ДОУ номенклатура Но составление структуры хранения все равно будет ложиться на плечи сотрудников службы ДОУ, поэтому им нужно осваивать основы теории классификации.
Сотрудники служб ДОУ должны будут определить права доступа к документам (например, на чтение без права редактирования, на редактирование без права на уничтожение, на редактирование с правом удаления и пр.).
Сотрудникам служб ДОУ предстоит освоить основы информационной безопасности, разобраться в сущности электронно-цифровой подписи (ЭЦП), правилах ее применения, понять, в каких случаях необходимо ее использовать, а в каких – можно обойтись без нее.
Структура контента, неструктурированная информация и проблемы ее использования в бизнес-целях
Данные существуют во множестве различных форм и размеров, но большинство из них могут быть представлены в виде структурированных и неструктурированных данных.
· Структурированные данные представляют собой высокоорганизованную, фактическую и точную информацию. Обычно он представлен в форме букв и цифр, которые хорошо вписываются в строки и столбцы таблиц. Структурированные данные обычно существуют в таблицах, подобных файлам Excel и электронным таблицам Google Docs.
· Неструктурированные данные не имеют заранее определенной структуры и представлены во всем разнообразии форм. Примеры неструктурированных данных варьируются от изображений и текстовых файлов, таких как документы PDF, до видео и аудио файлов, и это лишь некоторые из них.
Структурированные данные часто называют количественными данными, что означает, что их объективный и заранее определенный характер позволяет нам легко подсчитывать, измерять и выражать данные в числах. Неструктурированные данные также называются качественными данными в том смысле, что они имеют субъективный и интерпретирующий характер. Эти данные можно разделить на категории в зависимости от их характеристик и свойств.
1.1 Структурированные данные
Структурированные данные – это хорошо организованные и точно отформатированные данные. Эти данные существуют в формате реляционных баз данных ( СУБД ), то есть информация хранится в таблицах со связанными строками и столбцами. Таким образом структурированные данные аккуратно упорядочиваются и записываются, поэтому их можно легко найти и обработать.
Пока данные вписываются в структуру СУБД, мы можем легко искать конкретную информацию и выделять отношения между ее частями. Такие данные можно использовать только по прямому назначению. Кроме того, для структурированных данных обычно не требуется много места для хранения.
В аналитических целях можно использовать хранилища данных . DW – это центральные хранилища данных, используемые компаниями для анализа данных и составления отчетов.
Для работы с реляционными базами данных и хранилищами используется специальный язык программирования SQL, который означает язык структурированных запросов и был разработан IBM еще в 1970-х годах.
Примеры структурированных данных. Структурированные данные знакомы большинству из нас. Файлы Google Sheets и Microsoft Office Excel – это первое, что приходит на ум, когда речь идет о примерах структурированных данных. Эти данные могут содержать как текст, так и числа, такие как имена сотрудников, контакты, почтовые индексы, адреса, номера кредитных карт (таблица 1).
Таблица 1- пример структурированных данных
Типичный пример структурированных данных: электронная таблица Excel, содержащая информацию о покупателях и покупках.
Практически каждый имел дело с бронированием билета через одну из систем бронирования авиабилетов или снятием наличных в банкомате. Во время этих операций мы обычно не думаем о том, с какими приложениями имеем дело и какие типы данных они обрабатывают. Однако это системы, которые обычно также используют структурированные данные и реляционные базы данных.
1.2 Неструктурированные данные
Имеет смысл, что если определение структурированных данных подразумевает аккуратную организацию компонентов предопределенным образом, определение неструктурированных данных будет противоположным. Части таких данных не структурированы заранее определенным образом, то есть данные хранятся в своих собственных форматах.
Проблема с неструктурированными данными в том, что традиционные методы и инструменты не могут быть использованы для их анализа и обработки. Один из способов управления неструктурированными данными – выбор нереляционных баз данных, также известных как NoSQL .
Если есть необходимость хранить данные в исходных исходных форматах для дальнейшего анализа, лучше всего подойдут репозитории хранения, называемые озерами данных . Озеро данных – это хранилище или система, предназначенная для хранения огромных объемов данных в естественном / необработанном формате.
Принимая во внимание все разнообразие форматов файлов неструктурированных данных, неудивительно, что они составляют более 80 процентов всех данных. При этом компании, игнорирующие неструктурированные данные, остаются далеко позади, поскольку не получают достаточно ценной информации.
Примеры неструктурированных данных. Существует широкий спектр форм, которые составляют неструктурированные данные, такие как электронная почта, текстовые файлы, сообщения в социальных сетях, видео, изображения, аудио, данные датчиков и так далее (таблица 2).
Таблица 2- пример неструктурированных данных
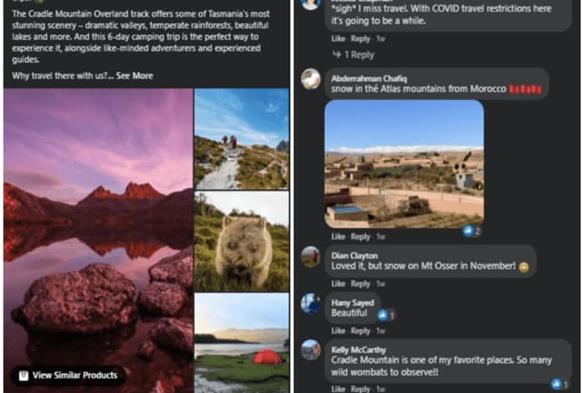
Сообщение туристического агентства в Facebook: пример неструктурированных данных.
В качестве примера мы можем взять сообщения в социальных сетях туристического агентства или все публикации, если на то пошло. Каждый пост содержит некоторые показатели, такие как репосты или хэштеги, которые можно количественно определить и структурировать. Однако сами посты относятся к категории неструктурированных данных. Мы пытаемся сказать, что для анализа сообщений и сбора полезной информации потребуется некоторое время, усилия, знания и специальные программные инструменты. Если агентство публикует новые туристические туры и хочет узнать реакцию аудитории (комментарии), им нужно будет изучить публикацию в ее собственном формате (просмотреть публикацию в приложении социальных сетей или использовать передовые методы, такие как анализ настроений)
1.3 Ключевые различия между структурированными и неструктурированными данными
Рассмотрим еще несколько важных различий между структурированными и неструктурированными данными;
Структурированные данные обычно представлены в виде текста и чисел. Его форматы стандартизированы и удобочитаемы. Наиболее распространены CSV и XML. В модели данных формат данных был определен заранее.
В отличие от структурированных данных, неструктурированные форматы данных представлены в избытке различных форм и размеров. Неструктурированные данные не имеют заранее определенной модели данных и хранятся в своих собственных форматах (так называемых «исходных» форматах). Это могут быть аудио (WAV, MP3, OGG и т. Д.) Или видеофайлы (MP4, WMV и т. Д.), PDF-документы, изображения (JPEG, PNG и т. Д.), Электронные письма, сообщения в социальных сетях, данные датчиков и т. д .
· По модели данных:
Структурированные данные менее гибкие, так как они основаны на строгой организации модели данных. Такие данные зависят от схемы. Схема базы данных обозначает конфигурацию столбцов (также называемых полями) и типы данных, которые должны храниться в этих столбцах. Такая зависимость является как преимуществом, так и недостатком. Хотя информацию здесь можно легко найти и обработать, все записи должны соответствовать очень строгим требованиям схемы.
С другой стороны, неструктурированные данные обеспечивают большую гибкость и масштабируемость. Отсутствие заранее определенной цели неструктурированных данных делает их очень гибкими, поскольку информация может храниться в различных форматах файлов. Однако эти данные субъективны и с ними труднее работать.
· Легкость поиска, анализа и обработки:
Одно из основных различий между структурированными и неструктурированными данными заключается в том, насколько легко их можно подвергнуть анализу. Структурированные данные в целом легко искать и обрабатывать, независимо от того, обрабатывает ли это человек или выполняет программные алгоритмы.
Неструктурированные данные, напротив, гораздо сложнее искать и анализировать. После обнаружения такие данные должны быть внимательно обработаны, чтобы понять их ценность и применимость. Этот процесс сложен, поскольку неструктурированные данные не могут поместиться в фиксированные поля реляционных баз данных, пока они не будут собраны и обработаны.
С исторической точки зрения, поскольку структурированные данные существуют дольше, логично, что для них существует отличный выбор зрелых аналитических инструментов. В то же время те, кто работает с неструктурированными данными, могут столкнуться с меньшим выбором инструментов аналитики, поскольку большинство из них все еще разрабатываются. Использование традиционных инструментов интеллектуального анализа данных обычно разбивается о неорганизованную внутреннюю структуру этого типа данных.
1.4 Проблемы использования неструктурированная информация в бизнес-
Подводя итоги, стоит сказать, что настоящей борьбы между неструктурированными и структурированными данными нет. Оба типа данных имеют большое значение для предприятий различных сфер и масштабов. Выбор источника данных может зависеть от структуры данных. Но чаще всего мы не выбираем один тип по сравнению с другим, а ищем возможности программного обеспечения для обработки всех данных.
В прошлом у компаний не было реального способа анализа неструктурированных данных, поэтому от них отказались, а основное внимание было уделено данным, которые можно было легко подсчитать. В настоящее время компании могут использовать искусственный интеллект, возможности машинного обучения и расширенную аналитику для выполнения за них сложного анализа неструктурированных данных. Например, такие корпорации, как Google, добились огромных успехов в технологии распознавания изображений, создав алгоритмы ИИ, которые могут автоматически определять, что или кто находится на фотографии.
По правде говоря, эти границы между структурированными и неструктурированными данными немного размыты, потому что в наши дни большинство наборов данных частично структурированы. Даже если мы возьмем неструктурированные данные, такие как фотография, они все равно будут содержать компоненты структурированных данных, такие как размер изображения, разрешение, дата создания изображения и т. д. Эта информация может быть организована в табличном формате реляционных баз данных.
Теперь, когда пояснены характеристики и различия между неструктурированными и структурированными данными, возможно принять обоснованное решение о том, следует ли инвестировать в технологии, чтобы воспользоваться преимуществами неструктурированных данных. Лучшим сценарием для корпораций является использование обоих типов данных, повышая эффективность бизнес-аналитики.
Дата добавления: 2021-07-19 ; просмотров: 379 ; Мы поможем в написании вашей работы!
Источник: studopedia.net
Неструктурированные данные: Что это такое и для чего это нужно?

Неструктурированные данные — самый распространенный тип в современном мире больших данных. В этом типе данных хранится много полезной информации, которая может быть использована для принятия бизнес-решений. Искусственный интеллект (ИИ) и машинное обучение используются для создания новых программных решений, которые фильтруют огромные объемы данных в поисках полезных для бизнеса сведений.
Большая часть информации, создаваемой и собираемой предприятиями, является неструктурированной, и ее объем быстро растет. В этой статье мы дадим определение неструктурированным данным, обсудим их различные виды и поговорим об их использовании в различных областях.
Что такое неструктурированные данные?
Неструктурированные данные сложны для использования компьютерной программой, поскольку у них нет четкой структуры. Они не соответствуют модели данных и не имеют структуры, которую можно было бы распознать. Большинство данных этого типа состоят из текста, но они могут включать и другие виды информации, такие как даты, числа и факты.
Ниже приведен список характеристик данных:
- Данные неструктурированы и не подчиняются модели данных.
- Данные не имеют четко определенной структуры.
- Данные не имеют определенного формата или порядка.
- Отсутствие узнаваемой структуры затрудняет их использование компьютерными программами.
- Данные нельзя хранить в строках и столбцах, как в базах данных.
Структура данных стремительно растет благодаря тому, что все больше людей пользуются цифровыми услугами и приложениями. Структурированные данные крайне важны, но если правильно оценивать неструктурированные данные, они могут быть гораздо полезнее для бизнеса. Они могут предложить множество идей, которые не могут передать цифры и статистика. Давайте рассмотрим некоторые примеры их типов.
Типы неструктурированных данных
Неструктурированные данные включают различные форматы и источники, такие как юридические документы, аудио, разговоры, видео, фотографии, текст на сайте и многие другие. Ниже приведены примеры некоторых наиболее распространенных типов данных.
Электронная почта
Существует тонна неструктурированных данных, ежедневно создаваемых многочисленными электронными письмами, которые мы отправляем, и традиционные инструменты аналитики не могут их разобрать. Однако метаданные электронного письма придают ему определенную структуру, и некоторые алгоритмы анализа текста могут извлечь важную информацию из тысяч писем за считанные секунды.
Социальные сети
Данные, собранные с платформ социальных сетей, являются неструктурированными. Но, как и электронные письма, они могут быть настроены определенным образом. Отличным примером этого являются хэштеги.
Пользователи могут использовать хэштеги для поиска интересующих их тем. Однако сообщения хэштегов неструктурированы.
Ответы на опросы
В анкетах, посвященных маркетинговым исследованиям, вовлечению сотрудников и изучению потребительского опыта, часто содержатся вопросы с несколькими вариантами ответов и открытые вопросы. Такие вопросы требуют неструктурированных текстовых ответов.
Публикации
Неструктурированные данные публикуются в различных формах изданиями, справочниками и порталами. Примеры содержания включают новостные статьи, объявления о вакансиях, рецензии на фильмы, объявления о продаже недвижимости, обзоры ресторанов, базы данных резюме, запросы предложений и так далее. Данные в виде текста или изображений включены в каждый из них.
Коммуникационные данные
В наши дни существует множество способов вести содержательные беседы с другими людьми, как в профессиональном, так и в личном плане. Представьте себе предприятие, сотрудники которого часто общаются с клиентами и поставщиками по различным каналам, генерируя неструктурированные аудио-, графические и текстовые данные.
Мультимедийные файлы
Мультимедийные файлы по-прежнему неструктурированы, поскольку мы не знаем, что на самом деле представляет собой изображение, музыка или видео, хотя они могут быть помечены названиями или темами и сохранены в базах данных MP3, JPG, PNG, GIF и т. д.
Документы
Оценки, юридические документы и слайд-шоу для бизнеса часто пишутся от руки, публикуются в Интернете или сохраняются в формате PDF. Эти файлы могут также включать электронные таблицы, изображения или файлы XML. Даже если текстовые файлы написаны в стандартной манере, данные не упорядочены таким образом, чтобы их можно было анализировать без применения сложных технологий искусственного интеллекта.
Веб-страницы
Неструктурированные данные создаются с экспоненциальной скоростью в Интернете. Текст, фотографии, аудио, видео и другие типы материалов — все это можно найти на веб-страницах.
Использование неструктурированных данных
Неструктурированные данные по своей природе несовместимы с программами обработки транзакций; аналитика и BI — вот основные области их использования.
Розничные компании, производители анализируют эти типы данных, а также другие предприятия для повышения качества обслуживания клиентов и создания эффективной рекламы. Кроме того, они анализируют отзывы клиентов, чтобы узнать их отношение к продуктам, услугам и брендам компании с помощью анализа настроений.
Одним из новых вариантов использования аналитики с неструктурированными данными является предиктивное обслуживание. Например, производители могут изучать данные датчиков для выявления проблем с оборудованием в производственных системах или готовой продукции на местах.
Анализ журнальных данных ИТ-систем позволяет выявить тенденции использования, ограничения пропускной способности и причины проблем с приложениями, сбоев в работе систем и узких мест в производительности. Кроме того, огромные массивы неструктурированных данных можно использовать для следующих целей:
- Изучение сообщений на предмет соответствия нормативным требованиям.
- Мониторинг и оценка взаимодействия с клиентами и комментариев в социальных сетях.
- Получение достоверной информации об общих предпочтениях и поведении клиентов.
Проблемы неструктурированных данных
Наличие и применение неструктурированных данных для аналитических, нормативных и директивных нужд приводит к необходимости поиска и тщательного изучения этих данных. Ниже перечислены некоторые проблемы, которые могут возникнуть при работе с неструктурированными данными:
- Длительное ожидание новых и измененных данных: Требуется очень много времени для разбора целых файловых систем хранения и обработки ежедневных изменений в больших объемах сотен миллионов или даже миллиардов неструктурированных файлов.
- Трудность поиска высококачественных данных: Если говорить о качестве, то неструктурированные данные могут быть весьма непоследовательными. Поскольку данные трудно проверить и, следовательно, они не всегда корректны, наблюдается отсутствие постоянства качества.
- Сложно управлять данными: Эти данные находятся в сыром виде и никак не структурированы. Поиск достоверных данных может быть затруднен. Кроме того, поиск нужных данных и индексирование — сложные задачи.
- Неадекватное хранение: Устаревшие ограничения на резервное копирование заставляют предприятия создавать дорогостоящие репликации, которые «прикрепляют» данные к одному поставщику и бренду хранения.
- Недоступные данные: Немасштабируемое программное обеспечение для резервного копирования не может быстро и безопасно передавать важные данные между хранилищами. Это затрудняет миграцию данных со старого хранилища на новое.
Вывод
Неструктурированные данные могут показаться подавляющими из-за своей неорганизованности и большого объема информации. Однако с ними можно просто обращаться, а разнообразные данные можно получать с помощью искусственного интеллекта.
Узнавайте своих конкурентов и клиентов лучше. Возьмите под контроль неструктурированные данные и управляйте ими, чтобы получить глубокие знания, которые можно использовать немедленно. Программное обеспечение для анализа на основе машинного обучения позволяет глубоко погрузиться в неструктурированные данные больших данных, чтобы увидеть общую картину или провести тонкие исследования.
предлагает решения для любых вопросов и отраслей, что делает его намного больше, чем просто программное обеспечение для проведения опросов. Для работы с данными у нас также есть системы, такие как наша исследовательская библиотека InsightsHub.
Организации по всему миру используют системы управления знаниями и такие решения, как InsightsHub, чтобы лучше управлять данными, минимизировать время, необходимое для получения информации, и повысить эффективность использования исторических данных, экономя при этом затраты и повышая рентабельность инвестиций. Попробуйте прямо сейчас!
Ключевые слова:
- Маркетинговые исследования
- Инсайт-хаб
Источник: hr-portal.ru