Смысл больших данных в том, что мы можем делать нечто новое. Один из наиболее перспективных способов использования лежит в сфере «машинного обучения». Идея, попросту говоря, заключается в том, чтобы «скормить» компьютеру большой объем данных и заставить его отыскивать типовые алгоритмы, которые не способен увидеть человек, или принимать решения на основе процента вероятности в том масштабе, с которым прекрасно справляется человек, но который до сих пор не был доступен для машин, или, возможно, однажды — в таком масштабе, с которым человек не справится никогда. По сути, это способ заставить компьютер делать что-то не путем конкретных указаний к действию, а так, чтобы машина сама разбиралась в том, что ей нужно делать, на основании огромного объема информации.
По сути, машинное обучение — это способ заставить компьютер делать что-то не путем конкретных указаний к действию, а так, чтобы машина сама разбиралась в том, что ей нужно делать, на основании огромного объема информации.
БОЛЬШИЕ ДАННЫЕ В ОФД 📈 КАК ИСПОЛЬЗОВАТЬ BIG DATA В БИЗНЕСЕ
Эта область довольно молода. Несмотря на то что сама задумка появилась в 1950-х годах, такой метод плохо работал на практике. Поэтому был сделан вывод о его несостоятельности. Однако всего лишь за последнее десятилетие произошла интеллектуальная и техническая революция, когда с помощью этого метода исследователи достигли больших результатов.
Чего не доставало ранее, так это объема данных. Сейчас, когда их достаточно, метод заработал. Сегодня машинное обучение лежит в основе всего, в том числе в основе поисковых систем, предоставляемых в онлайн-режиме рекомендаций по выбору продуктов, компьютерного перевода с одного языка на другой, распознавания голоса и многого другого.
История машинного обучения
Чтобы понять суть машинного обучения, полезно знать, как появилась такая концепция. В 1950-х годах программист компании IBM Артур Самуэль написал компьютерную программу для игры в шашки. Но игра получилась не очень интересной. Он выигрывал, потому что машина знала только разрешенные ходы. Артур Самуэль знал стратегию.
Поэтому он написал умную подпрограмму, которая при каждом ходе оценивала вероятность того, что полученная конфигурация приведет к выигрышу, а не к проигрышу. И вновь партия между человеком и машиной не удалась — система была слишком незрелой. Но потом Самуэль оставил машину играть самостоятельно. Играя сама с собой, она собирала больше данных.
Собирая больше данных, она делала более точные предсказания. Артур Самуэль снова сыграл с компьютером — и проиграл. И снова проиграл. Человек создал машину, превзошедшую его способности в выполнении задачи, которой он эту машину научил.
А как мы пришли к самоуправляемым автомобилям? Индустрия программного обеспечения научилась лучше кодировать правила дорожного движения? Нет. Увеличилась компьютерная память? Нет. Появились более быстрые процессоры?
Нет. Дело в более умных алгоритмах? Нет. В более дешевых микросхемах? Нет.
Все это способствовало развитию процесса. Но что действительно сделало возможной такую инновацию, это изменение компьютерщиками самой сути проблемы.
Ее обратили в проблему данных вместо обучения машины езде, что сделать очень трудно. Мир сложен — и автомобиль собирает все данные из окружающей его действительности, пытаясь разобраться в них. Он понимает, что впереди светофор, что горит красный, а не зеленый свет, и это значит, что следует остановиться. Автомобиль может делать тысячу предсказаний в секунду.
Результат — возможность самоуправления. Больше данных не значит лишь увеличение объема. Больше данных порождает нечто иное.
Идея машинного обучения привела к обнаружению шокирующих результатов, которые, кажется, ниспровергают идею превосходства человека как источника разумного осмысления в этом мире.
Компьютер совершил прорыв в медицине
В ходе проведенного в 2011 году исследования специалисты Стэнфордского университета загрузили в алгоритм машинного обучения тысячи образцов раковых клеток молочной железы и данные о проценте выживания пациентов и попросили компьютер выявить характерные признаки, с наибольшей вероятностью предсказывающие тяжелый злокачественный характер конкретной биопсии. Компьютер смог найти 11 признаков, которые с наибольшей вероятностью предсказывают тяжелый злокачественный характер клеток молочной железы. В чем соль? Из медицинской литературы известны только восемь таких признаков. О трех из найденных признаков патологи не знали и не искали их.
Опять же в этом случае исследователи не говорили компьютеру, что анализировать. Они просто дали ему образцы клеток, их общие характеристики и данные о выживании пациентов (этот прожил еще 15 лет, тот умер через 11 месяцев…). Компьютер обнаружил очевидное. Но он также заметил и неочевидные вещи: признаки болезни, которых не видели люди, потому что человеческому глазу это не под силу.
Однако эти признаки были выявлены благодаря некоторому алгоритму. Машинное обучение достигает успешных результатов, потому что компьютеру предоставляют большие объемы данных — больше информации, чем человек может переработать за всю жизнь или мгновенно запомнить. Однако в данном случае компьютер превзошел человека. Он заметил такие признаки, которые не увидели специалисты.
Это позволяет ставить более точные диагнозы. А поскольку это компьютер, он может делать такие вещи в требуемом масштабе. Итак, «больше» для больших данных — это не просто больше, это еще и «лучше».
Почему это важно?
Только подумайте: применяя данный подход в требуемом масштабе, мы сможем анализировать материал биопсии раз в день, каждый день, для каждого человека — вместо одного или нескольких раз за жизнь. Благодаря этому мы сможем определить, как выглядит рак на самых ранних стадиях, с тем чтобы его можно было лечить самыми простыми, самыми эффективными и наименее дорогими способами, от чего выиграют пациенты, общество и бюджет государственной системы здравоохранения, из которого такое лечение оплачивается.
Что в этом нового?
Не забывайте, что компьютер не просто повысил точность диагностики за счет добавления новых признаков. Фактически он также сделал научное открытие. (В данном случае ранее неизвестные три признака тяжелой степени рака представляли собой отношения между клетками в клеточном материале под названием строма, а не просто характерные особенности самих клеток.) Компьютер обнаружил нечто, что ускользнуло от людей и что продвигает человеческую мысль вперед.
«Больше» для больших данных — это не просто больше, это еще и «лучше»
Что значит иметь больше данных?
Убедительный пример приводит Манолис Келлис, исследователь-генетик из Института Брода в Кембридже. Как отмечается в докладе Белого дома, «Большое количество генетических данных имеет решающее значение при выявлении значимого для заболевания варианта гена. В данном исследовании связанная с шизофренией аллель не выявлялась при анализе 3500 случаев, а начала лишь слабо прослеживаться при анализе 10000 случаев и внезапно оказалась статистически значимой при анализе 35000 случаев». Вот как объяснил это Келлис: «Существует точка перелома, в которой все меняется».
Медицина являет собой еще один убедительный пример того, как большие данные готовы преобразовать бизнес. Сфера здравоохранения представляет множество примеров, так как уже накопила огромное количество данных, однако она серьезно отстает в плане их использования в соответствии с громадным потенциалом.
Обратимся к проблеме выявления нежелательного взаимодействия лекарственных веществ — в случае, когда человек принимает два разных препарата, которые по отдельности безопасны и эффективны, но в сочетании дают опасный побочный эффект. При условии наличия на рынке десятков тысяч препаратов, эту проблему сложно решить из-за невозможности протестировать одновременный прием всех препаратов. В 2013 году исследовательское подразделение компании Microsoft и несколько американских университетов придумали оригинальный способ выявления подобных случаев: путем анализа поисковых запросов.
Как большие данные готовы преобразовать бизнес. Пример из медицины
Исследователи составили список из 80 терминов, связанных с симптомами общеизвестного заболевания — гипергликемии (такими как «высокий уровень сахара в крови» или «помутнение зрения»). После этого они анализировали следующее: искали ли пользователи один препарат пароксетин (антидепрессант) и/или другой препарат, правастатин (снижающий уровень холестерина). Проанализировав 82 миллиона поисковых запросов, выполненных за несколько месяцев 2010 года, ученые напали на след.
Поиски только симптомов, без того или иного препарата, составляли исключительно малое количество запросов — менее 1%, как «фоновый шум». Поиски симптомов и только одного из препаратов составили 4% запросов, поиски симптомов и другого препарата — 5%. А поиски симптомов и обоих препаратов составили целых 10% запросов. Другими словами, люди более чем с удвоенной вероятностью вводили в поисковую систему определенные медицинские симптомы, если при этом они искали оба препарата, а не один из двух.
Это серьезный результат. Но он не является неопровержимым доказательством. И не дает права полиции ворваться в дома топ-менеджеров фармацевтических компаний и увозить их в отделение. Это всего лишь соотношение, которое ничего не говорит о причинах. Тем не менее подобные результаты имеют глубокий смысл и большое значение для бизнеса и отрасли.
Раньше о таком нежелательном взаимодействии лекарственных веществ не знали, о нем ничего не писали в инструкции по применению. Оно не включалось в рамки клинических исследований или в процесс одобрения препарата к применению. Оно обнаружилось при анализе старых поисковых запросов — опять же в количестве аж 82 миллионов.
Значение данных
Значение этих данных огромно. Если вы пациент, вам следует знать эту информацию. Если вы врач, вы тоже захотите ее иметь. Если вы медицинский страховщик, вы еще больше хотите ее получить. А если вы инспектор по контролю лекарственных средств, вы однозначно желаете владеть этими данными.
Если же вы представляете компанию Microsoft, возможно, вам следует подумать о создании подразделения по лицензированию данных как о способе организации нового потока доходов, вместо того чтобы просто зарабатывать на рекламе, появляющейся рядом с результатами поисковых запросов.
Препятствия
Этот новый мир данных и то, как компании могут поставить его себе на службу, наталкивается на сопротивление двух областей государственной политики и регулирования. Первая — сфера занятости. Прежде всего руководители компаний видят необходимость нового типа работников — наступает великая эпоха специалистов по обработке и анализу данных.
Консультанты по вопросам управления бьют тревогу, предупреждая о серьезной нехватке кадров. Университеты готовятся удовлетворять этот спрос. Но это очень недальновидный взгляд на вещи. В средне- и долгосрочной перспективе большие данные украдут наши рабочие места. Можно ожидать, что развитие технологий вызовет волну структурной безработицы.
А все потому, что большие данные и алгоритмы теснят офисных работников умственного труда в XXI веке точно так же, как автоматизация производства и сборочные конвейеры вытеснили с производства тяжелый ручной труд в XIX и XX веках. В то время ценным ресурсом считались мускулы, и тут машины справлялись лучше людей. В будущем окажется, что и ум наш слабее машинного. Исследование, проведенное специалистами Оксфордского университета, дает прогноз, что в США не менее 47% объема всей сегодняшней работы может быть переложено на компьютеры.
Возьмем пример патолога, который становится ненужным, так как алгоритм машинного обучения позволяет читать результаты биопсии у раковых больных намного точнее, быстрее и дешевле. Как правило, патологи имеют высшее медицинское образование. Они покупают дома. Платят налоги. Голосуют. По выходным они натаскивают в игре футбольные команды своих детей.
Короче говоря, они являются вовлеченными и заинтересованными членами общества. И вот им — и еще целому классу подобных им профессионалов — предстоит увидеть, как их работа меняется до неузнаваемости или, возможно, полностью упраздняется.
Источник: rb.ru
Влияние Big Data: почему уже не получится жить и работать без больших данных

Большие данные – это сфера, в которой только начинают разбираться и пользователи, и сам бизнес, который использует эти данные для организации различных процессов. Почти 60% компаний до сих пор ничего не знают о своей аудитории, потому что не освоили технологии Big Data. Разбираемся, что это такое, какие российские разработки есть в сфере AdTech, и почему в рекламе они оказались нужнее всего.
Как работает наука о данных
Летом на Яндекс.Кью появился вопрос: как объяснить бабушке, что такое Data Science? И простое описание этому направлению нашел всего один пользователь – Сослан Табуев, Data Scientist крупного банка:
«Если бабушка верит в приметы, то можно сказать ей, что это область, где новые приметы находит компьютер, если рассказать ему о случившихся событиях и тому, что им предшествовало. Можно привести пример предсказания погоды», – ответил на вопрос эксперт.
И это действительно наглядное объяснение, которое поможет понять суть аналитики данных. Люди тоже наблюдают явления, находят закономерности и на их основе делают предположения, просто компьютеры делают это эффективнее. Учитывая, что поток информации удваивается в объеме каждые 18 месяцев, возникла необходимость автоматизировать его обработку и это открыло большое количество возможностей.
Big Data или «большие данные» – общее обозначение данных всех возможных видов, которые можно обработать или структурировать. Они собираются в базы данных, а для управления базами разрабатывают целые системы, которые смогут эти данные хранить, обрабатывать и выдавать очень точные отчеты.
Big Data в повседневности
На анализ данных опирается прогнозирование в самых разных сферах, без их использования уже не получится получить кредит, купить продукты или заказать доставку. По последнему опросу Хабр, уже 37% бизнеса внедрило в свою деятельность технологии работы с большими данными, а это почти каждая третья компания.
Откуда собираются данные:
- соцсети, блоги и СМИ;
- данные о мобильных устройствах: тип устройства, браузер, ПО, геолокация;
- интернет вещей (IoT) и подключенные к нему устройства;
- данные компаний: транзакции, заказы товаров и услуг.
Банки используют Big Data-технологии, чтобы анализировать платежеспособность клиентов при выдаче кредитов. Это не составляет сложности, потому что у них есть вся информация о том, сколько денег на вашем счете, какие есть регулярные и нерегулярные источники дохода, сколько вы тратите в месяц и даже на что именно и в какое время.
Ритейл, то есть розничные магазины анализируют данные о продажах, чтобы закупать нужный объем товара, который не будет долго задерживаться на полках. Это особенно важно для сегмента скоропортящихся продуктов, так как компания не несет убытки, а покупатели всегда видят в магазине свежий товар.

E-commerce, то есть все торговые площадки в интернете, тоже анализируют, что покупают их пользователи, когда и в каких объемах. Им это необходимо для того, чтобы персонализировать предложения и предлагать аудитории те категории товаров, которые ей необходимы. Например, молодым родителям – товары для детей, предпринимателям – технику и все для бизнеса, а тем, кто недавно переехал – мебель и строительные материалы.
Big Data в рекламе
Индустрия рекламных технологий объединяет все направления экономики, перечисленные выше, потому что каждый продукт нужно продвигать. Банки предлагают свои финансовые услуги, ритейл и маркетплейсы – продукты, товары первой необходимости и множество других категорий товаров, которые интересны абсолютно разным людям.
В сфере рекламы возможность отслеживать действия людей, их предпочтения, интересы, перемещение, круг общения и поведенческие особенности стала прорывом, потому что действия людей наиболее правдивы, чем слова. Отзывы, которые собирают о продукте маркетологи могут не соответствовать действительности, так как при личном общении много факторов могут заставить людей солгать.
«Нейросети, которые анализируют поведение потребителей, не обращают внимание на наш субъективный оральный фидбек, ведь если люди платят, смотрят, покупают, значит миссия выполнена, даже если интуитивно это не так очевидно. И в этом преимущество работы с большими данными», – отмечает в своем блоге популяризатор науки Артур Шарифов.
Например, мобильные устройства собирают данные о местоположении владельца. Как правило, они хранятся мобильными операторами, а те в свою очередь продают эти данные владельцам бизнеса или компаниям, которые занимаются настройкой рекламных компаний.
Яндекс с помощью аналитики данных о геолокации, формирует отчеты о загруженности любого общественного пространства, чтобы пользователи планировали свой день, а бизнес мог отслеживать приток клиентов. Этот отчет общедоступен, чтобы его увидеть, нужно ввести в поисковой строке браузера название места или заведения, которое вы планируете посетить, а система аналитики выдаст вам отчет о потоках людей в данной точке:
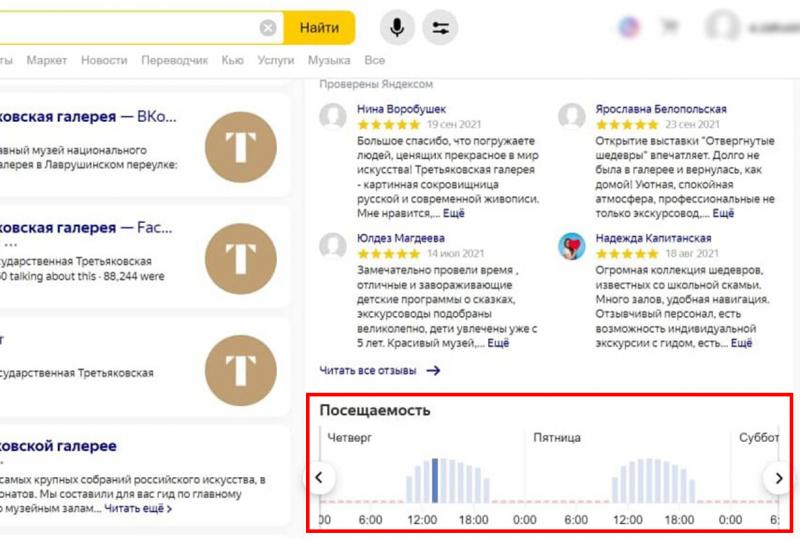
Российский стартап BackAd нашел способ использования геолокации даже для показа рекламы оффлайн там, где обитает целевая аудитория клиента. Делается это с помощью курьеров на заданной геолокации, для реализации идеи команда спроектировала и разработала компактное переносное устройство с FullHD-экраном. Курьеры надевают эти смарт-рюкзаки и отправляются по маршруту аудитории.
Социальная дилемма
Возможности такой «социальной слежки» периодически пугают общественность. С одной стороны ситуация выглядит, как «win-win», когда все оказываются в плюсе. Бизнес не тратит ресурсы на бесполезную рекламу а пользователи видят в лентах своих смартфонов только то, что им действительно необходимо, и спасаются от медийного шума.
Но с другой стороны ни одно действие не остается незамеченным, и вокруг каждого человека формируется «информационный пузырь», состоящий только из того, что его интересует. Так люди перестают замечать проблемы других и даже изменения в обществе. Об этом в 2020 Netflix выпустил документальный фильм «Социальная дилемма».
Но все-таки большие опасения у людей вызывает вопрос их собственной безопасности и то, насколько надежны те системы, которые хранят и обрабатывают данные. Одну из таких платформ, которая сейчас востребована во всем мире, как раз разработали в России. Это платформа ClickHouse, она позволяет обрабатывать огромные массивы данных о клиентах в реальном времени.
Система может вмещать до десятка триллионов записей и петабайтов данных, умеет запрашивать, вставлять, изменять или удалять данные, а главное защищает их от передачи третьим лицам в соответствии с законом. Гарантом надежности ClickHouse стала востребованность разработки среди таких техно-гигантов, как Uber, Tesla, Spotify, eBay, ByteDance (владелец соцсети TikTok), Alibaba, Tencent, а также «ВКонтакте» и Wildberries.
Но чтобы усилить собственную безопасность, пользователям самим стоит помнить о правилах элементарной безопасности в интернете, которые обеспечат сохранность данных и даже включены в некоторые программы школьных уроков ОБЖ:
- Двухфакторная аутентификация: установите подтверждение входа с помощью смс-подтверждения после того, как введете логин и пароль от аккаунта.
- Установка приложений из проверенных источников. Телефоны – наше самое уязвимое устройство, в нем хранится огромное количество данных, которые нужно защищать. Установка пиратских приложений с вредоносным ПО может сильно навредить вашей безопасности и конфеденциальности.
Сюжет по этой теме
13 июля 2021, 17:34
Умная среда: инструкция по применению
Подписывайтесь на ФедералПресс в Дзен.Новости , а также следите за самыми интересными новостями в канале Дзен . Все самое важное и оперативное — в telegram-канале « ФедералПресс ».
Источник: fedpress.ru
Big Data и маркетинг: 5 методов использования с реальными кейсами
Big Data находится в авангарде цифровой революции. Примерно 43% организаций вносят изменения в структуру компании, чтобы использовать преимущества больших данных. Маркетологам Big Data помогает лучше понимать аудиторию и принимать более взвешенные решения по улучшению показателей продаж и ROI. Руководитель PR-агентства PRonline Дмитрий Трепольский предлагает рассмотреть 5 способов применения больших данных в маркетинге.

Big Data позволяет маркетологам с потрясающей точностью изучить, какие темы и виды контента интересуют аудиторию бренда. Анализируя данные пользователей с помощью Big Data, можно предлагать им максимально релевантный контент. Важно избавиться от мысли, что сайт и аккаунты бренда в социальных сетях — это статичный маркетинговый актив, который воспринимается всеми одинаково.
Компании, которые предлагают персонализированный контент, сильно выигрывают на фоне конкурентов, учитывая, сколько контента борется за внимание аудитории ежедневно. По данным SmarterHQ, предоставление персонализированного контента позволяет увеличить лояльность к бренду среди миллениалов в среднем на 28%.
Пример Coca-Cola
Coca-Cola — одна из компаний, которая использует Big Data таким образом. Собирая и анализируя данные из упоминаний в социальных сетях, каналов службы поддержки и других взаимодействий потребителей с брендом, Coca-Cola подбирает релевантный контент для каждого сегмента аудитории. Например, одни люди очень любят музыку, а другие следят за всеми видами спорта независимо от времени года. С учетом этой информации подбирается контент.
Персонализация e-commerce
Big Data оказывает огромное влияние на интернет-коммерцию и дает брендам возможность увеличить доход от онлайн-покупок. Аналитика, полученная с помощью больших данных, помогает предсказать предпочтения пользователя, подготовить персонализированные рекомендации и оптимизировать цены, чтобы увеличить маржинальность продукции.
По данным McKinsey, увеличение цены на 1% может привести к повышению операционной выручки на 8,7%, если не наблюдается спад в объеме продаж. Таким образом, Big Data представляет особый интерес для бизнеса, поскольку позволяет оптимизировать цены.
Big Data можно использовать для формирования релевантных рекомендаций. Когда речь заходит об апселлинге и перекрестных продажах, компании используют анализ с помощью больших данных, чтобы изучить поведение и предпочтения потребителя, а также его историю покупок. В результате формируются максимально релевантные и персонализированные предложения. Вероятность того, что потребитель просмотрит продукты, рекомендованные на основе информации, которой он поделился с компанией, на 40% выше.
Пример Very
Британский онлайн-ритейлер Very анализирует прогнозы погоды и данные пользователей, чтобы менять рекомендации на домашней странице сайта в соответствии с индивидуальными предпочтениями потребителя и погодой в том месте, где он находится. Кроме того, на баннерах на домашней странице отображается имя потенциального покупателя. В «арсенале» Very более 1,2 миллиона вариаций домашней страницы, которые демонстрируются разным пользователям.
Оптимизация кампаний и сокращение расходов
Маркетологам приходится сражаться за внимание пользователей на постоянно растущем количестве каналов. К тому же путь покупателя фрагментирован, и потребители часто переходят с одного канала на другой прежде чем совершить покупку. Поэтому определить, как эффективно распределить бюджет по каналам — задача не из легких.
Big Data помогает определить, какие каналы приносят наилучшие результаты, и в соответствии с этим распределить бюджет. Моделирование атрибуции позволяет маркетологам создать карту пути покупателя для разных сегментов аудитории и предсказать, какие точки взаимодействия окажут наибольший эффект на рост продаж.
Таким образом, Big Data приводит к сокращению расходов. Если верить Invespcro, 83% маркетологов, которые при подготовке кампаний ориентируются на аналитику больших данных, добиваются увеличения ROI в 5 раз.
Пример AdriaCamps
Хорватское агентство кемпинга AdriaCamps использует большие данные, чтобы определить, с помощью каких каналов лучше всего взаимодействовать с аудиторией. В течение первых 6 месяцев после начала этой практики им удалось получить на 60% больше лидов, чем ожидалось, и на 66% больше броней. Также AdriaCamps смог настроить очень точный, узконаправленный таргетинг. Например, одна из email-рассылок предназначалась всего для 8 людей. В результате уровень открытия писем достиг 45%, а кликабельности — 20%.
Больше таргетированной рекламы
С доступом к данным о предпочтениях и поведении пользователя, а также о внешних факторах, оказывающих на него влияние, маркетологи могут сформировать более персонализированные рекламные предложения. Анализ того, как люди взаимодействуют с брендом, позволяет выявить паттерны и тренды, которые помогают сделать рекламу более релевантной и привлекательной для потребителей. Детальная характеристика различных сегментов аудитории дает возможность создать lookalike-аудитории и найти похожих пользователей, которые раньше не взаимодействовали с брендом.
Повышение персонализации увеличивает эффективность рекламы и помогает сократить затраты на «пустые» клики. Пользователи остаются в выигрыше, потому что получают полезную рекламу, а бренд — потому что повышается эффективность и увеличивается ROI.
Пример The Weather Co.
Компания The Weather Co. известна тем, что широко использует Big Data. Она анализирует поведение пользователей из более чем 3 миллионов локаций по всему миру. Объединяя эту информацию с данными о прогнозе погоды, The Weather Co. предоставляет маркетологам возможность показывать пользователям максимально релевантную рекламу.
Например, бренд Pantene и онлайн-ритейлер Walgreens использовали данные The Weather Co., чтобы предлагать таргетированную рекламу продуктов с эффектом anti-frizz пользователям, которые находятся в местах с влажным климатом. В ходе кампании продажи продуктов Pantene на площадке Walgreens увеличились на 10%.
Улучшение тестирования
Возможность обрабатывать большие объемы данных и находить в них инсайты за короткий промежуток времени позволяет маркетологам проводить тестирование в ранее недоступных масштабах и с удивительной точностью.
Вместо того чтобы тестировать одну вариацию маркетингового актива, можно сразу изучить несколько вариаций и единиц данных, чтобы получить более полезные инсайты. К примеру, вариации лендинга могут быть протестированы на разных сегментах целевой аудитории. Демографические данные, предыдущие взаимодействия с сайтом и другие источники информации обрабатываются, чтобы определить, какая из вариаций наиболее эффективна для конкретного сегмента аудитории.
Пример pCloud
Система защиты файлов pCloud запустила рекламную кампанию с целью продвижения новой функции платформы. Компания отследила и протестировала каждый шаг, который совершают пользователи перед совершением покупки. Проанализировав взаимодействие с сайтом, pCloud смогли определить, на каком этапе пользователи чаще всего покидают страницу. После этого все шаги были снова протестированы и оптимизированы, в результате чего уровень конверсии увеличился на 124% при сокращении недельного бюджета на 6%.
Источник: www.sostav.ru